Overview
Database branching, coupled with deploy requests, allows you to deploy non-blocking schema changes to your production database with zero downtime. You can also undo deployments without losing any data that was written during that time.Create a deploy request
Before you can create a deploy request, the branch you are merging into must have safe migrations enabled.
1
Click on “Branches”.
2
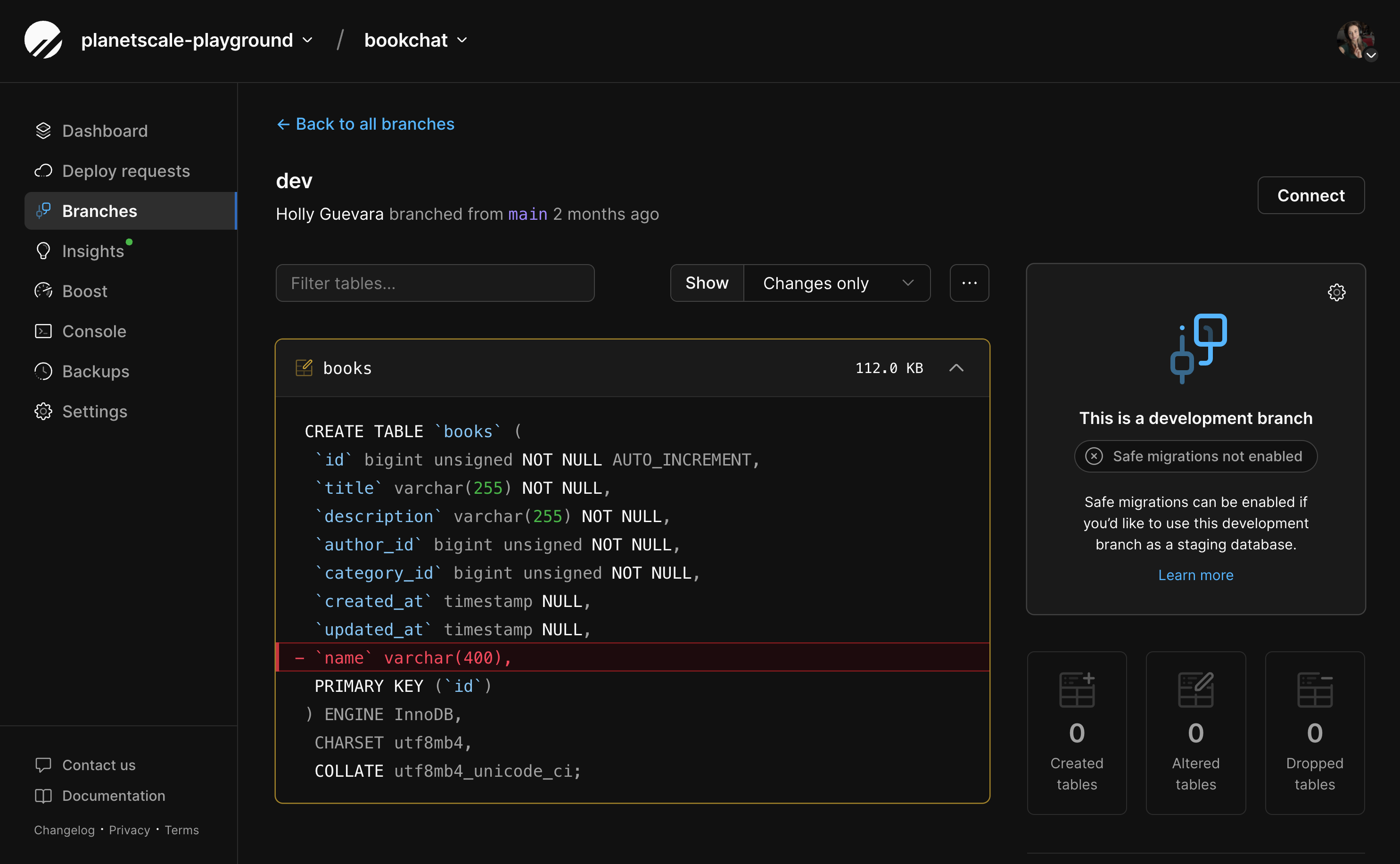
Select the development branch you want to deploy into the base branch.
3
This page shows you a diff of the schema against its base branch.
4
To the right of the page, you’ll see a dropdown that says “Deploy to”. If you don’t see this option, you likely don’t have safe migrations enabled on the branch you’re deploying into. Go to the branch page for the branch you’d like to merge into, and enable safe migrations.
5
Select the branch you want to deploy to. Again, if the branch doesn’t show in the dropdown, you need to enable safe migrations.
6
Optionally, add a comment about the deploy request.
7
Click “Create deploy request”.
Review a deploy request
Once you create a deploy request, you or your team can review it and, optionally, approve it before deploying it. PlanetScale will check if the request is deployable. This process includes checking for issues like:- Incompatible unique keys
- Invalid charsets (PlanetScale supports
utf8,utf8mb4,utf8mb3,latin1, andascii) - Invalid foreign key constraints
- Other schema lint errors that would prevent a successful schema change
1
Click the “Deploy requests” tab on the database dashboard page.
2
Select the open deploy request you want to review.
3
Under “Summary”, you’ll see if the request is deployable.
4
To review the schema changes, click the “Schema changes” tab.
5
You’ll see the proposed changes here. New additions are highlighted in green, and deletions are highlighted in red.
6
If you have required deploy requests to be approved before deployment, other users in your Organization will see the option to “Approve changes” or “Leave a comment” on the “Schema changes” tab.
If you are the only administrator in your Organization and you enable the “Require administrator approval for deploy requests” setting, you can self-approve your own deploy requests. If there is more than one administrator, self-approval is not allowed.
Approvals dismissed on schema changes
To ensure only approved schema changes are applied to production, an approval is automatically dismissed if the proposed changes are updated after the deploy request is approved. When this occurs,planetscale-bot comments on the deploy request with the list of changes since the last approval.
If the deploy request is already in the deploy queue when it’s schema changes, it will be removed from the queue. It must be re-approved and added to the queue again before it can deploy.
Reviewing changes across shards
If your deploy request contains changes to a sharded keyspace, you can see the affected shards by clicking the arrow next to each changed table. This will show the SQL that will run, and in the next tab, each shard that will be affected.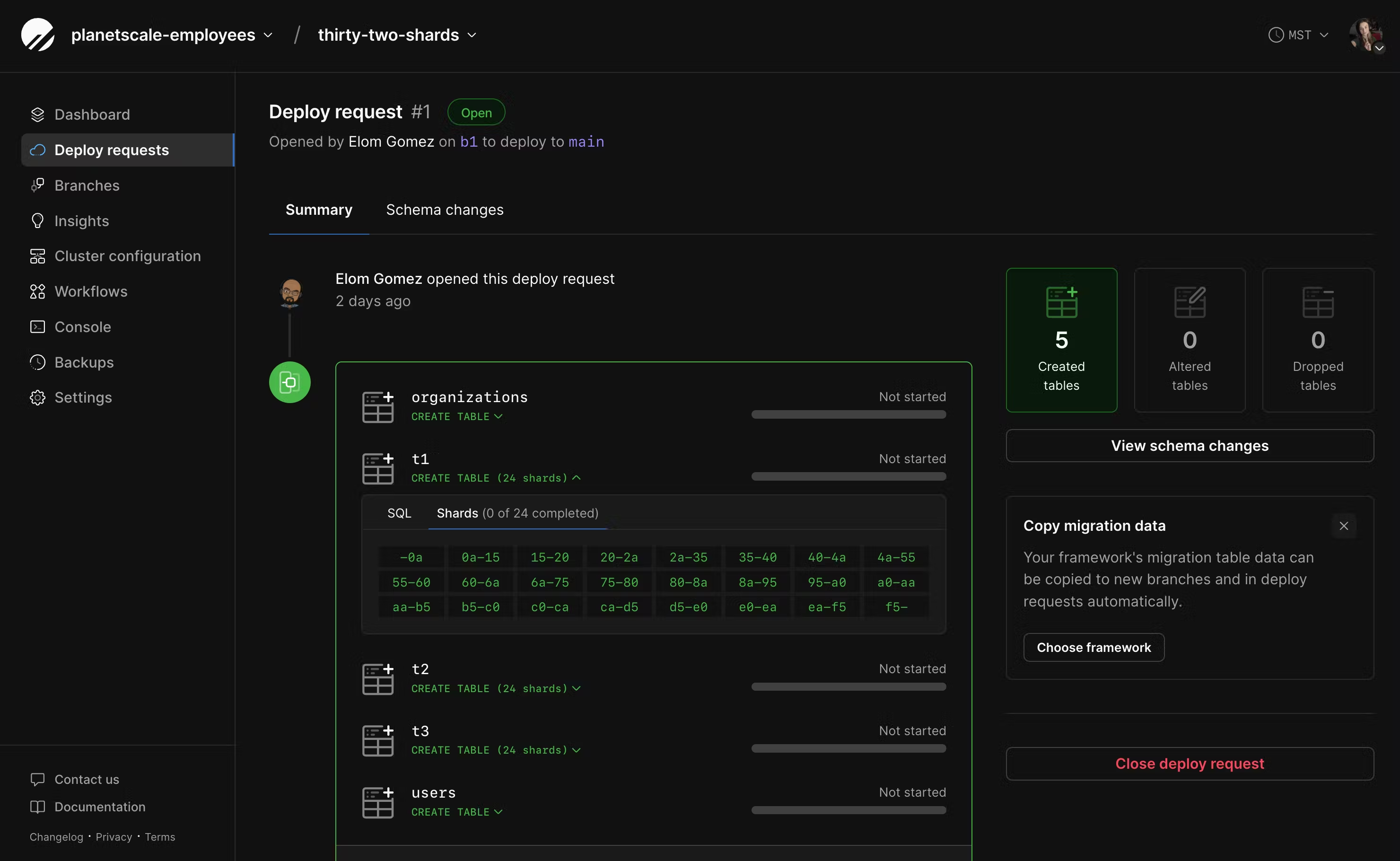
Deploy a deploy request
1
Once the request is approved, if required, it’s ready to be added to the deploy queue. Click on the “Summary” tab, and you’ll see the option to deploy.
2
Here you’ll have the option to choose to “Deploy changes” or to “Deploy changes instantly”: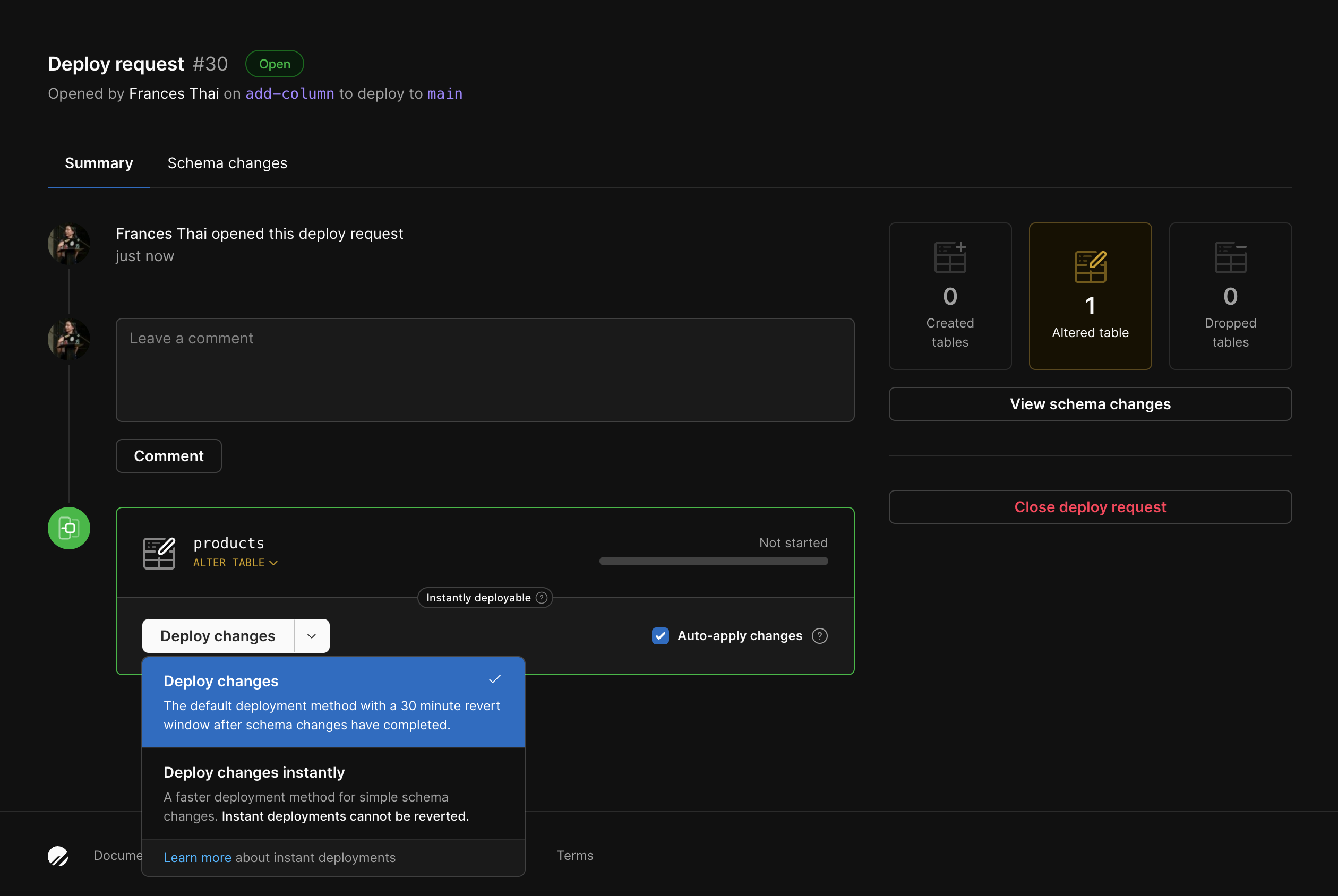
Deploy changes
1
(Optional) You have the option to enable gated deployments, which gives you the power to control exactly when the migration cuts over. You’ll see an “Auto-apply changes” checkbox, which is checked by default. If you uncheck this, you will get the option to apply the changes once the schema changes are complete. If you leave it checked, it will auto-deploy as soon as it’s ready.
2
(Optional) You also have the option to run the migration using MySQL’s ALGORITHM=INSTANT. If you would like to deploy instantly, click the arrow next to “Deploy changes” and select “Deploy changes instantly”. Gated deployments are not available for this option. See the Deploy changes instantly section below for more information.
3
When you’re ready to deploy, click “Deploy changes”. The deployment will begin or be queued if there are other pending deployments. You will still have a short window after deploying to enable gated deployments in this step.
4
If you enabled gated deployments (step 2), you can click “Apply changes” to merge the deployment to production once it completes.
5
After you deploy, you have 30 minutes to “undo” it using our schema revert feature.
6
If you are deploying changes to a sharded keyspace, you’ll see the progress for each shard here as well.
Deploy changes instantly
You also have the option to use MySQL’s ALGORITHM=INSTANT to instantly deploy the schema change. Learn more in the Instant Deployments section.- When you’re ready to deploy, click “Deploy changes instantly”. The deployment will begin or be queued if there are other pending deployments.
- Though the deployment many be queued, once it’s at the front of the queue, it will be deployed instantly.
- Instant deployments cannot be reverted.
Close a deploy request
If you decide you don’t want to proceed with a deploy request, you can easily close it.1
Click the “Deploy requests” tab on the database dashboard page.
2
Select the request you want to close.
3
Click on the “Close deploy request” button on the right-hand side.
Deploy requests and foreign key constraints
In most cases, deploy requests should work as expected when your schema changes have foreign key constraints. There are some cases where a deploy request will not be deployable. This includes cases where there is a mismatched column type or when a foreign key constraint references a deleted column. For example, if we open a deploy request to add a foreign key constraintt1_id with type BIGINT on a table t2 that references a column id on table t1, where t1.id’s type is BIGINT, the following cases would produce a linting error in the deploy request because it is not deployable:
- if, while the previously mentioned deploy request is open, someone else updates
t1.idto a different column type, i.e.,int. - if, while the previously mentioned deploy request is open, someone else deletes
t1.id. - if, while the previously mentioned deploy request is open, someone else deletes all indexes that cover
t1.idas their prefix. (Because in a foreign key relationship, the referenced columns on the parent table must be indexed, usually by a dedicated index, but they can be the first columns in an otherwise wider index.)
Validating referential integrity of existing columns
Deploy requests do not validate the referential integrity of existing columns.ALTER TABLE… ADD FOREIGN KEY… does not validate existing row relations within the context of a deploy request. Unlike standard MySQL, it is possible to add the foreign key constraint to a table with orphaned rows, and they will remain orphaned. In standard MySQL, adding a foreign key is a blocking operation, and it fails if any orphaned rows are found.
Instant deployments
Instant deployments give you the option to run schema changes using MySQL’s ALGORITHM=INSTANT. This is different than how our online schema migrations work. Instant deployments will apply schema changes faster, however, these schema changes must be auto-applied and cannot be reverted.Who should use instant deployments?
Instant deployments are well-suited to experienced users who want their schema change to take effect immediately rather than going through the online schema migration process.Supported operations
In order for a deploy request to be instantly deployed, all schema changes in the deploy request must be instantly deployable. Some of those changes include:- Adding or dropping a column (with some exceptions)
- Changing or dropping a column’s default value
- Changing an
ENUMorSETdefinition
- Changing a column’s data type
- Adding a column with a non-literal default value
- Adding or dropping an index
- Altering the visibility of an index
- Adding or dropping a foreign key constraint
- Extending a
VARCHARcolumn size - Updating a column to
NULLorNOT NULL
Gated deployments
Gated deployments give you more control over when a migration goes live after the deployment process completes. As part of our non-blocking schema change process, instead of directly modifying table(s) when you deploy a deploy request, we make a copy of the affected table(s) and apply changes to the copy. We get the data from the original table and the copy table in sync, and once complete, initiate a quick cutover where we swap the tables.If a deploy request includes changes to multiple tables, all tables cut over at the same time — unless there is a sequential dependency.
Enable gated deployments in the dashboard
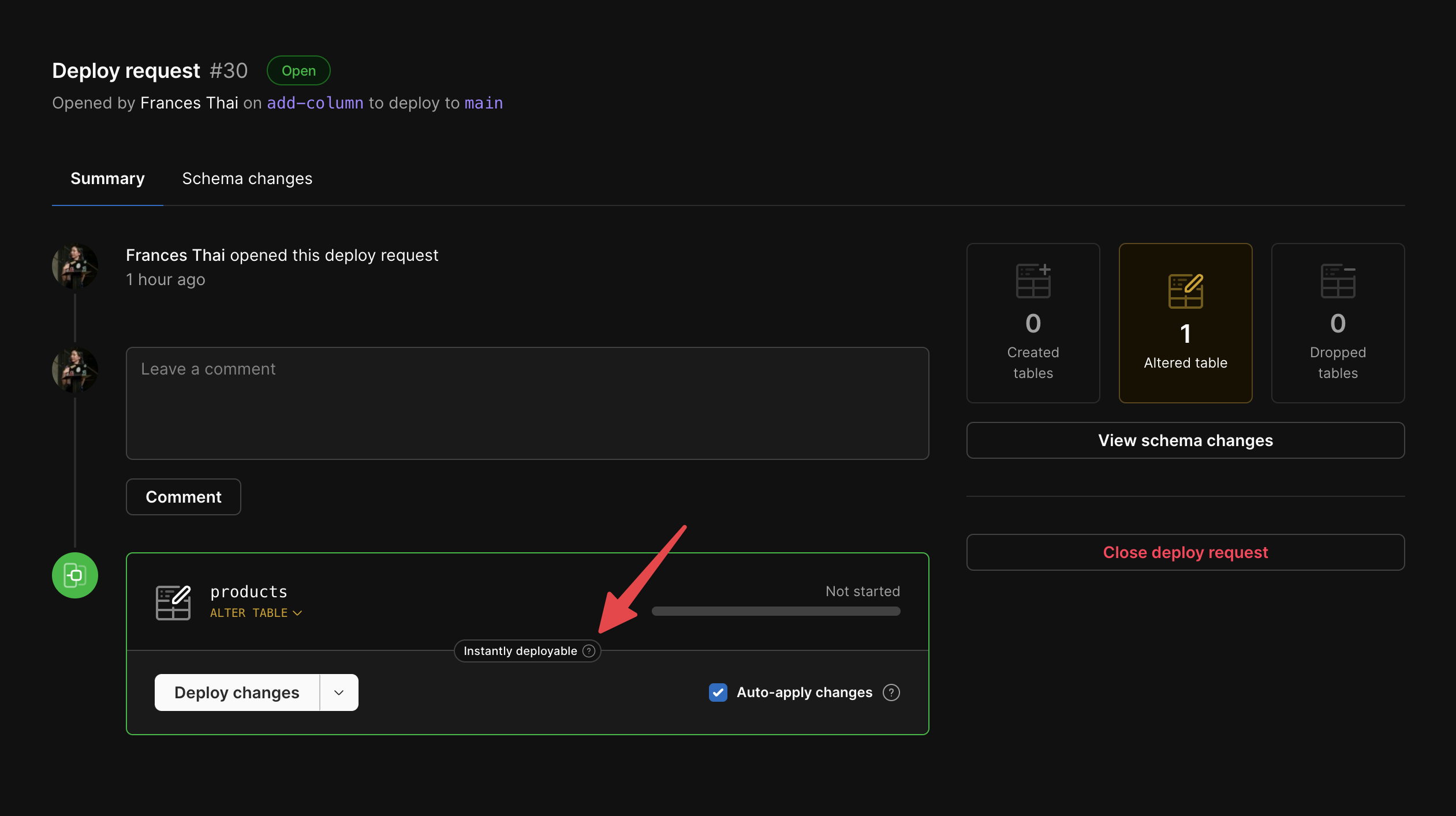
1
When you open a deploy request, uncheck the “Auto-apply changes” box.
2
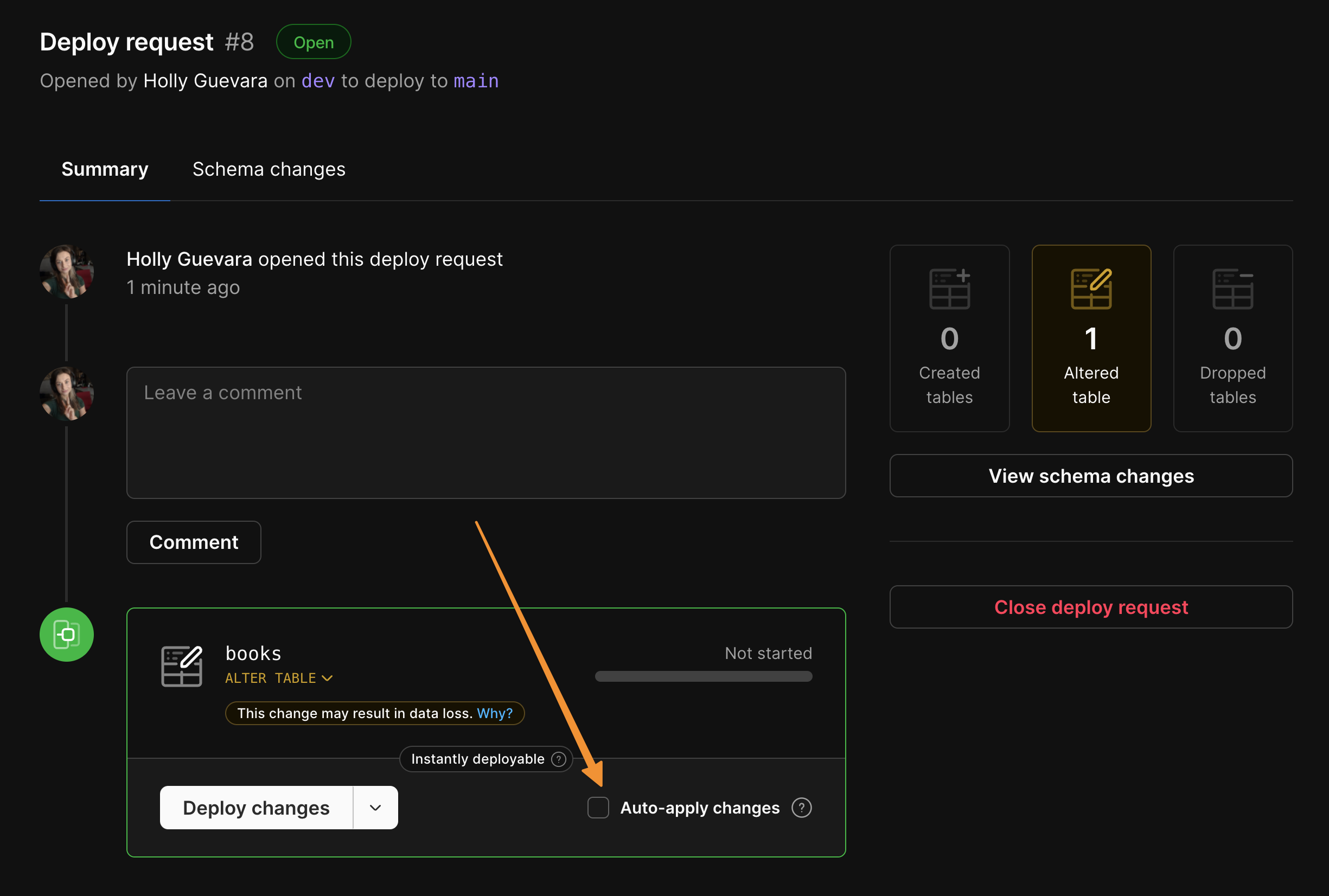
3
When your deploy request has completed and is ready for cutover, the “Apply changes” button will appear. You can now complete the deployment at any time by clicking this button.
Enable gated deployments via CLI
You can also manage auto-apply settings using the PlanetScale CLI. To create a deploy request with auto-apply disabled:If neither
--enable-auto-apply nor --disable-auto-apply is provided when creating a deploy request, the setting is inherited from the previous deploy request.Limitations
- If you have an open gated deployment, you cannot deploy another deploy request until the current one has been merged in.
- Deploy requests that are instantly deployed cannot be gated.
Artifact tables
During schema changes, Vitess creates artifact tables to facilitate non-blocking migrations. For detailed information about artifact table behavior, storage implications, and cleanup processes, see the Artifact tables in schema changes documentation.Revert a schema change
If you ever merge a deploy request, only to realize you need to undo it, PlanetScale can handle that! You have the option to revert a recently deployed schema change while maintaining data that was written to the original schema during that time.Deploy requests that are instantly deployed cannot be reverted.
How to revert a schema change
You can revert a deployment for up to 30 minutes after the deploying. After the 30 minute period is up, the deployment becomes permanent, and you will no longer have the option to revert.1
Select the deploy request you want to revert.
2
To revert the schema changes made with the deploy request, click “Revert changes” and confirm.
3
We will immediately revert the base branch back to its previous schema.
4
Any data that was written to the original schema in the time between deploying and reverting will remain in your database after the revert.
5
The deploy request will be closed, but the branch will remain for you to continue development on if you choose.
When is data not retained
There are some scenarios where some data is not retained when you revert your changes.- You add a table or column to your schema and then revert it. If any data was written to those newly introduced fields between deployment and reverting, that data will not be retained upon revert, as the fields will no longer exist.
When a revert can result in orphaned rows
In some cases, when you are using foreign key constraints, a revert of a deploy request can result in orphaned rows. These can happen when your schema change is:- Dropping a foreign key constraint: Once a foreign key constraint is dropped, new data written to the table is less constrained. Reverting this change may result in data that is inconsistent with the dropped foreign key constraint.
- Dropping a table with foreign key constraints: When a table with foreign key constraints is dropped, the parent table(s) will continue to be written to. If this change is reverted, data in the table that was dropped may no longer be consistent with its foreign key constraints.
You must enable foreign key constraint support in the database settings page before using them.
When are you unable to revert a schema change
There are also some edge cases where reverting a schema change is not possible. We will always attempt to revert, but if there are scenarios where your data integrity is at risk, we will not proceed with the revert. The following are some cases where a revert will fail:- If you deploy a schema change that expands the length of some column, such as changing from
VARCHAR(10)toVARCHAR(50), and add new data larger than 10 characters to it, a revert attempt may fail. This is to protect your data. You may have written data to theVARCHAR(50)field in that time that will not fit in the smaller 10 character space. If no data is added between deployment and revert, the revert process can proceed. - Some examples of other similar scenarios where revert won’t be possible (again, only if larger sized data is added between deployment and revert) are:
INTtoBIGINTNOT NULLtoNULLTIMESTAMPtoTIMESTAMP(6)utf8toutf8mb4- Any other operation that expands the size of a field
- If you deploy a schema change that removes a unique key or relaxes a unique constraint, and in the time between deployment and attempting to revert, you insert rows that would otherwise conflict with that constraint, the revert may fail.
- Another uncommon but possible scenario: you deploy a schema change that has a
NOT NULLcolumn without aDEFAULTvalue, combined with anALTER TABLE DROP COLUMNstatement for that column. If you insert some rows between the deployment and the revert attempt, the revert will fail. We will not be able to re-add that column for the newly inserted rows and will not know how to populate it.
Schema revert and migration data
If you’ve selected a migration framework or specified a table with migration data in the settings tab of your database, the data within the table that tracks migrations will be moved to the production branch only after the revert window has been closed. This is to ensure that if the deploy request is reverted, the production branch has the correct log of applied migrations.Billing considerations
You may see some temporary_vt tables in your database. These are called artifact tables and are used to facilitate the deployment and revert process. They do not count toward your storage costs if you’re using network-attached storage.