Upgrading to Metal
When upgrading your existing PlanetScale database to Metal, it’s useful to know where to look to see how the upgrade has improved performance. Here, we cover the two main places you can inspect: Insights and the database metrics panel.The examples shown on this page use a Vitess database, but Metal is available for both Vitess and Postgres databases.
PS-640 to an M-640.
These both have 8 vCPUs and 64GB of RAM, but use a different underlying storage system that allows for the M-640 to have improved performance.
Let’s look at the effects of this in PlanetScale.
Insights
After upgrading to Metal, Insights is a great place to look to see how performance has changed. When you visit the Insights page, there are several tabs you can use to view graphs for different statistics. The first and default one is a query latency chart.Query latency
After zooming in to the time period when we upgraded to Metal, here is what we see: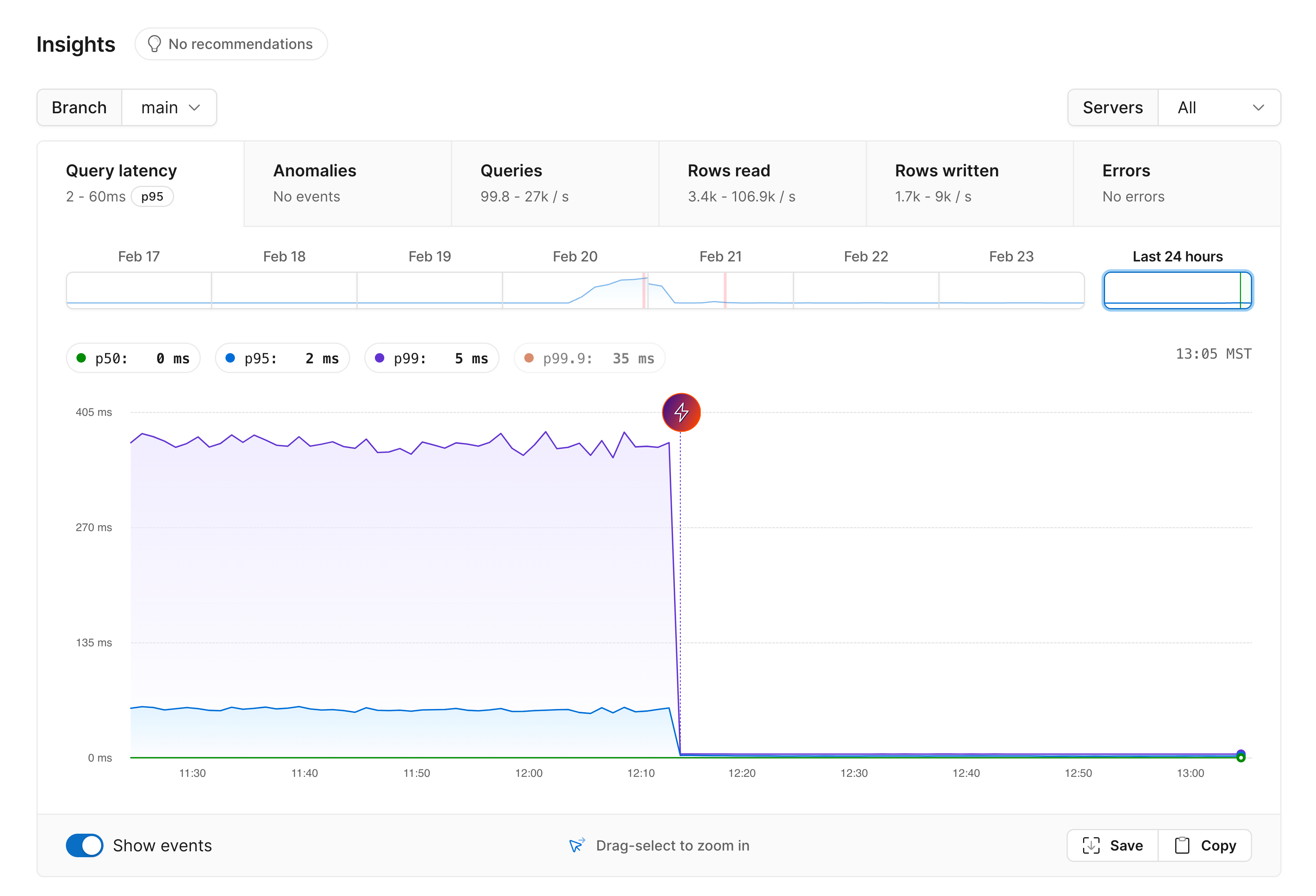
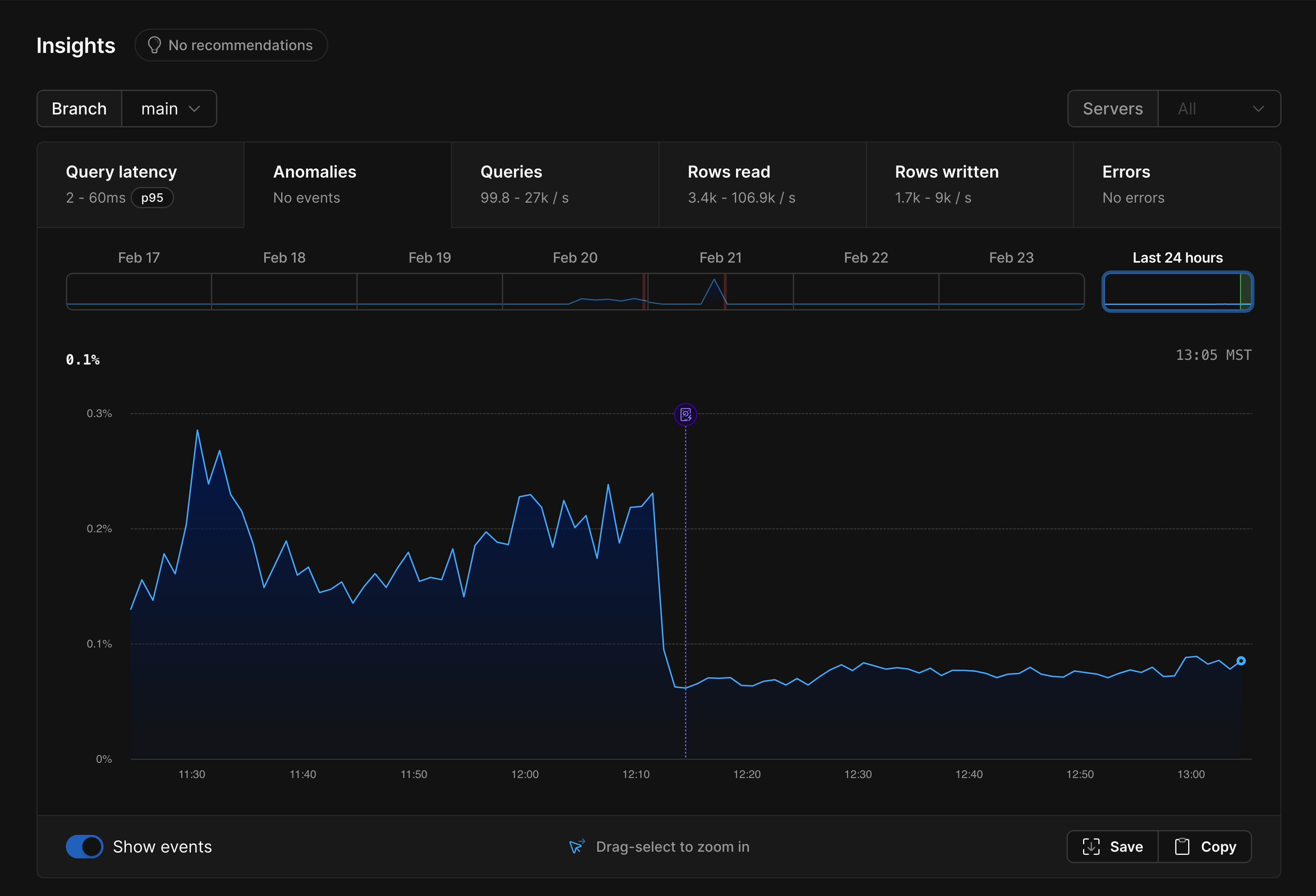
Anomalies
The anomalies graph shows the % of queries that are considered anomalous, or slow-running.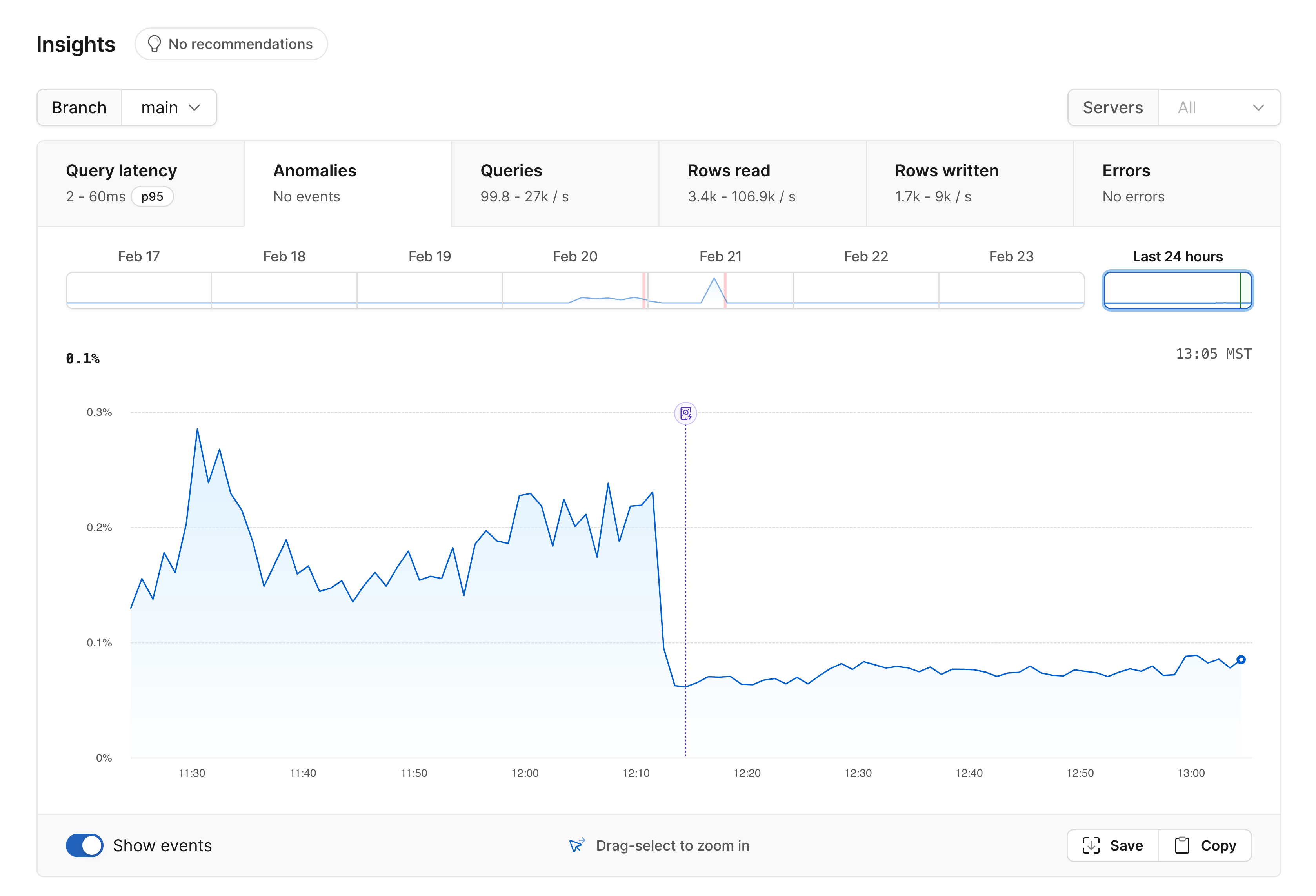
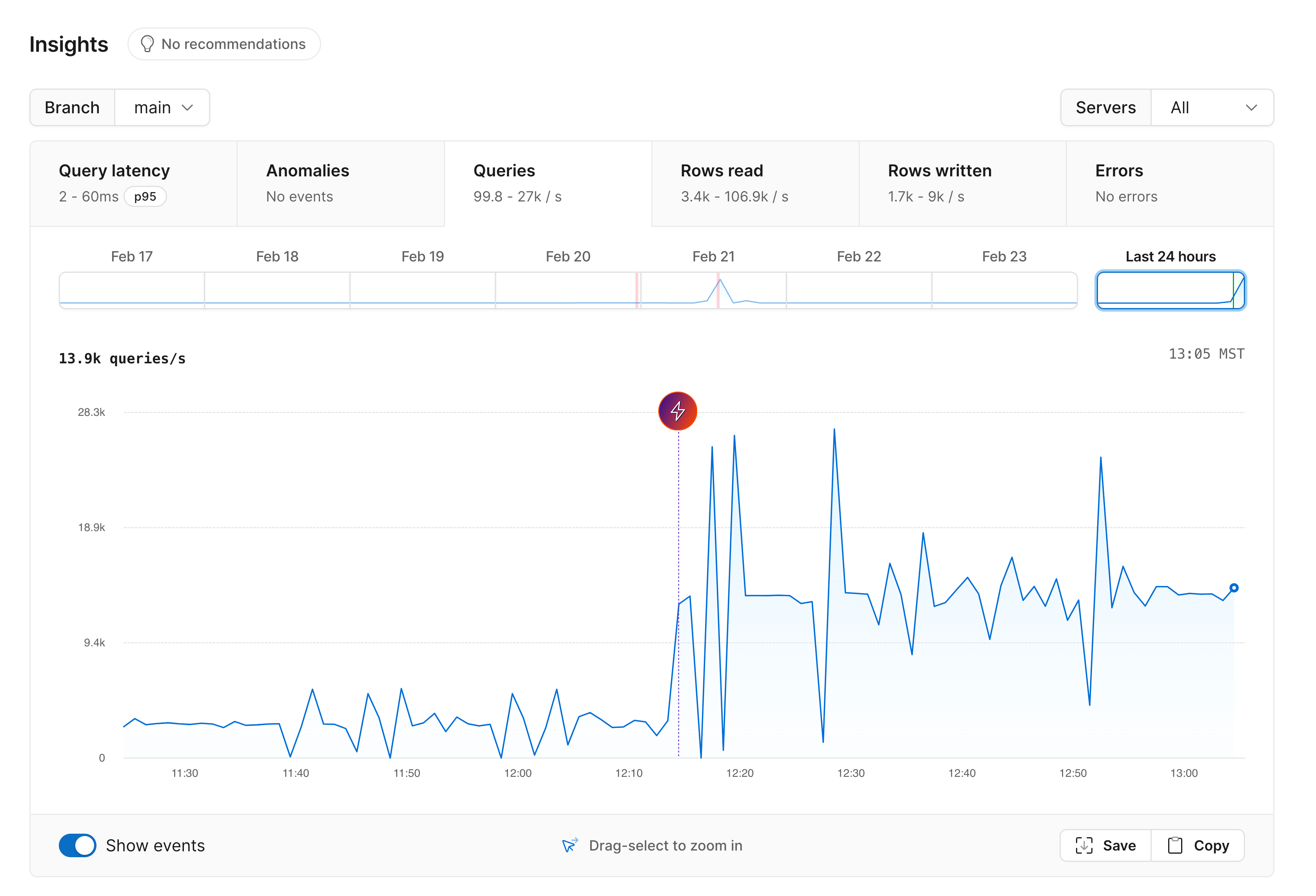
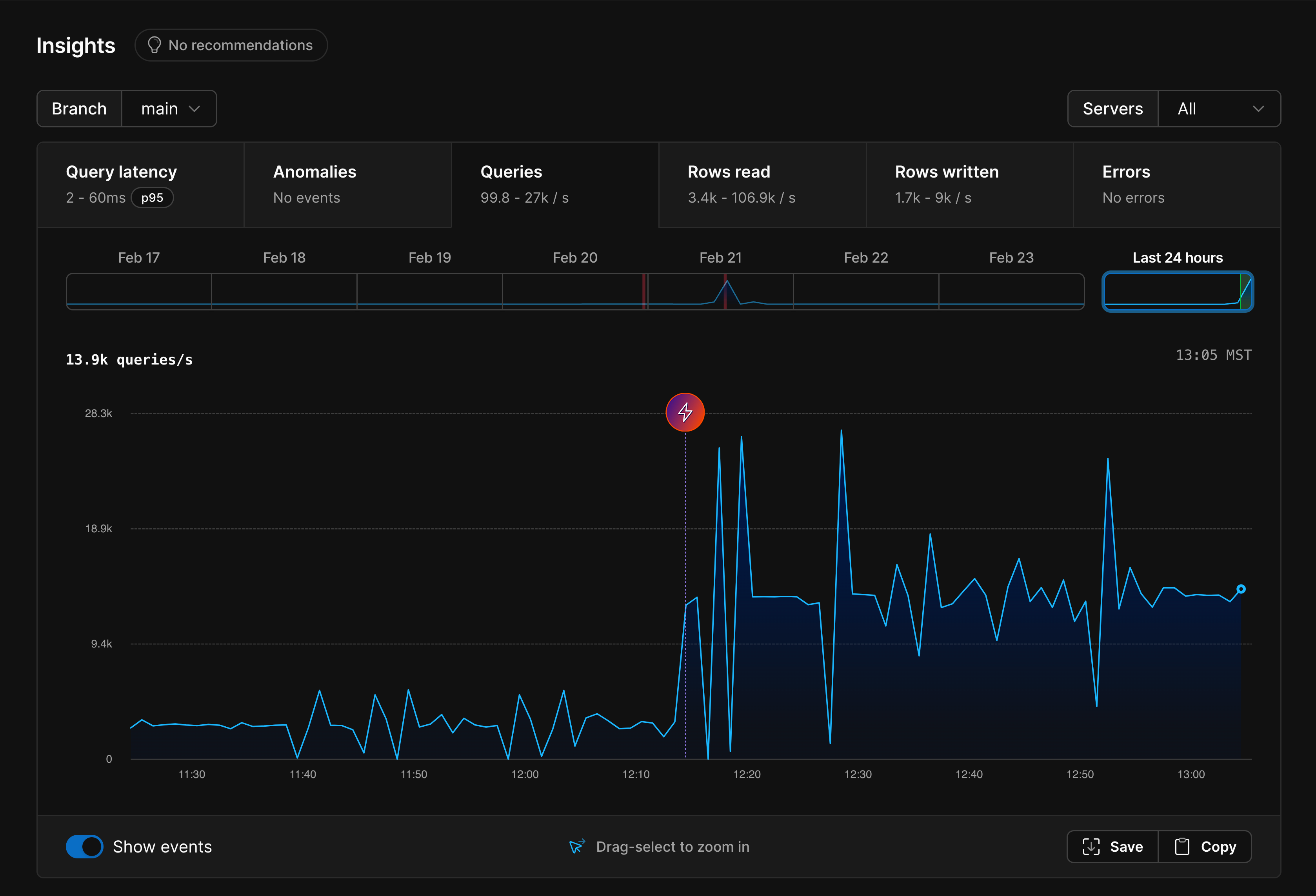
Queries
Rows read
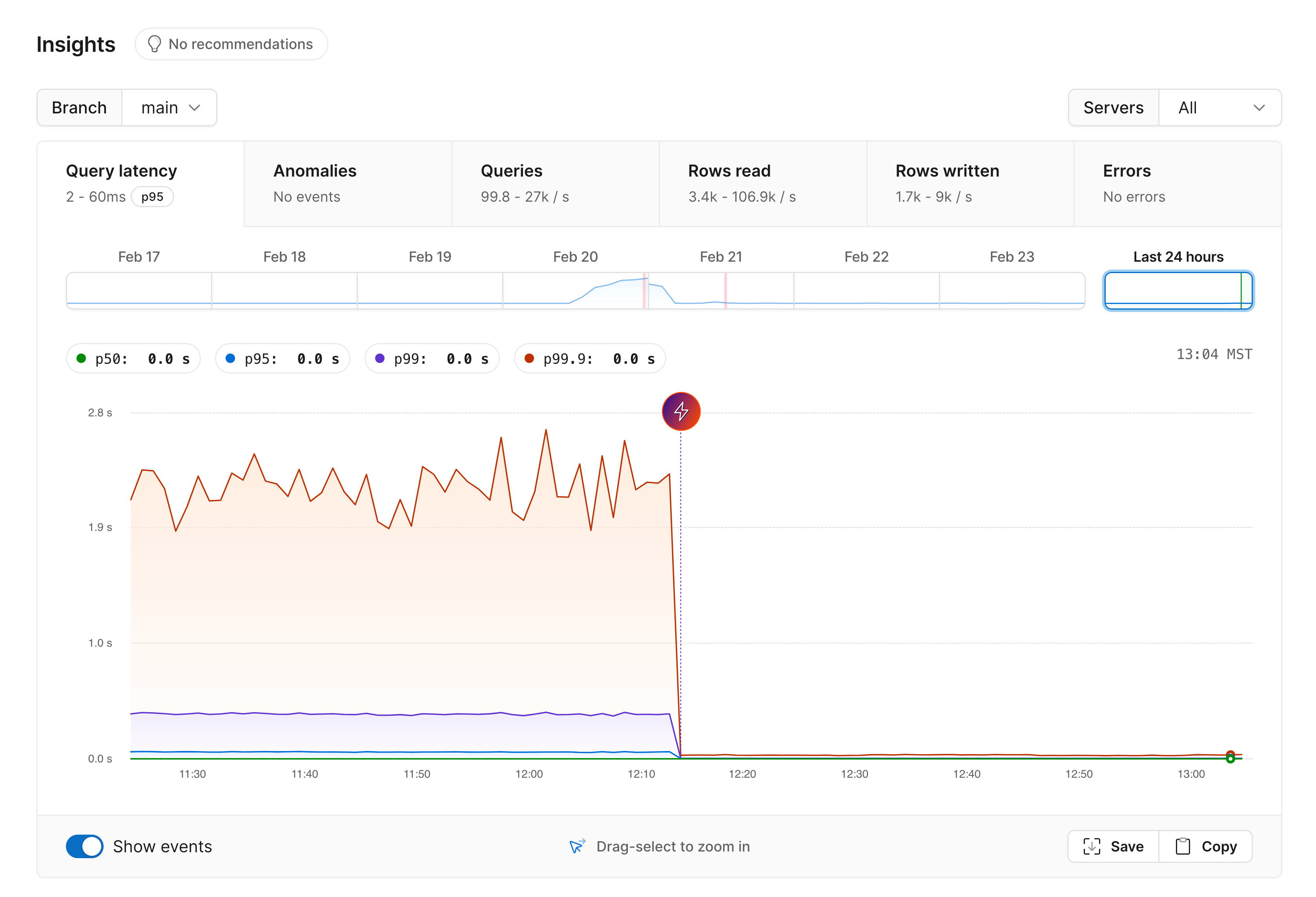
This is the rows read graph: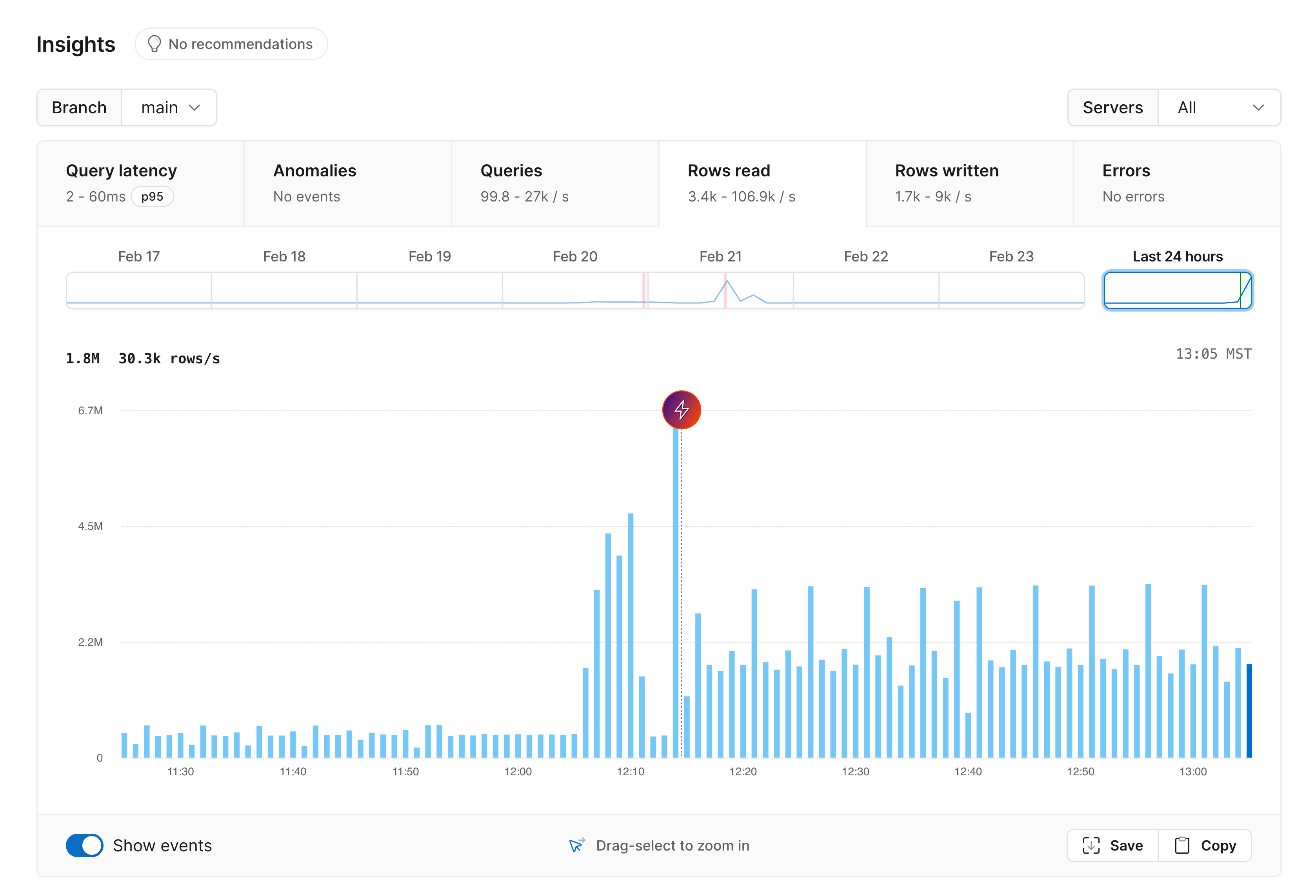
- (A) PlanetScale spins up three new NVMe-backed instances for you (one primary and two replicas)
- (B) Once these are up and running with all the necessary MySQL and Vitess components, we begin copying the data from your existing database onto the three NVMe drives, starting with restoring from the most recent backup.
- (C) Once the backup is restored, we catch the backup up to the current state of your other database. This can be as quick as a few minutes or seconds if there isn’t much new data, but can take some time, as we see here, if it has a lot of data to catch up.
- (D) Once the state of the old and new databases are identical, the cut over is made and the Metal instances begin serving your database traffic.
- (E) The old instances are torn down.
Rows written
We get a clear jump in rows written after the upgrade: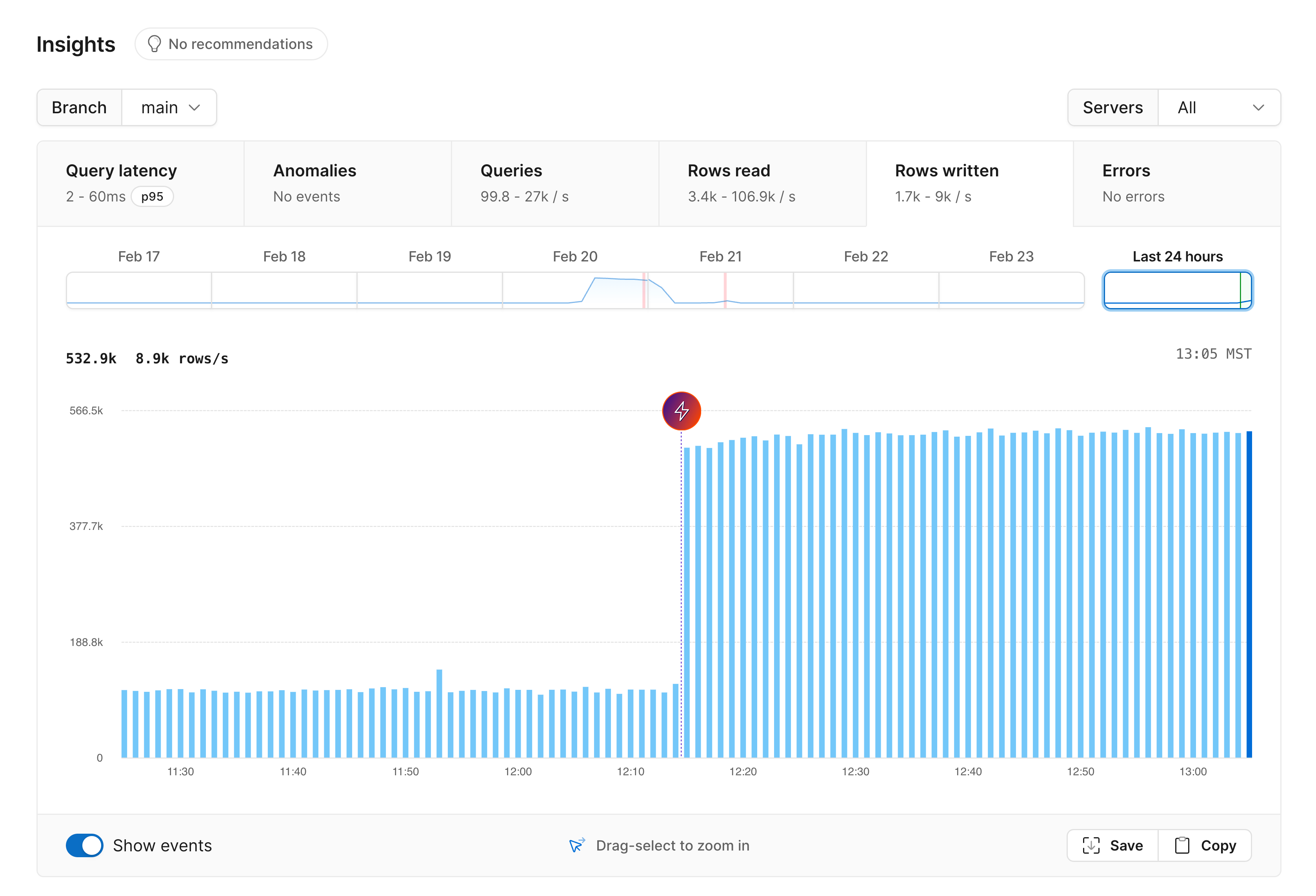
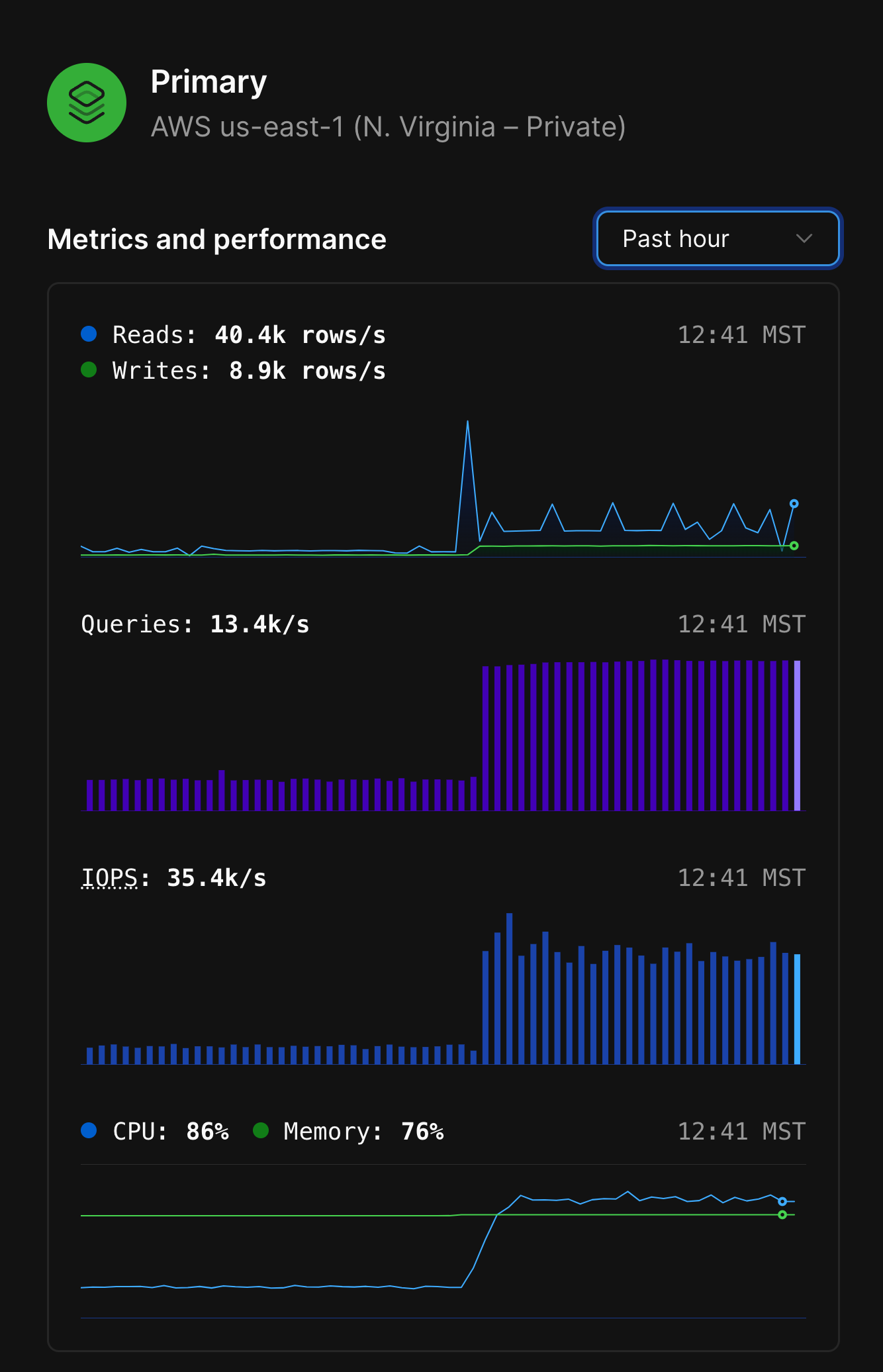
Primary metrics
Another good place to look after upgrading to Metal is the metrics for your primary database node. From the database’s Dashboard page, click on your primary from the architecture diagram. A panel should display on the right side of your screen with metrics from this instance.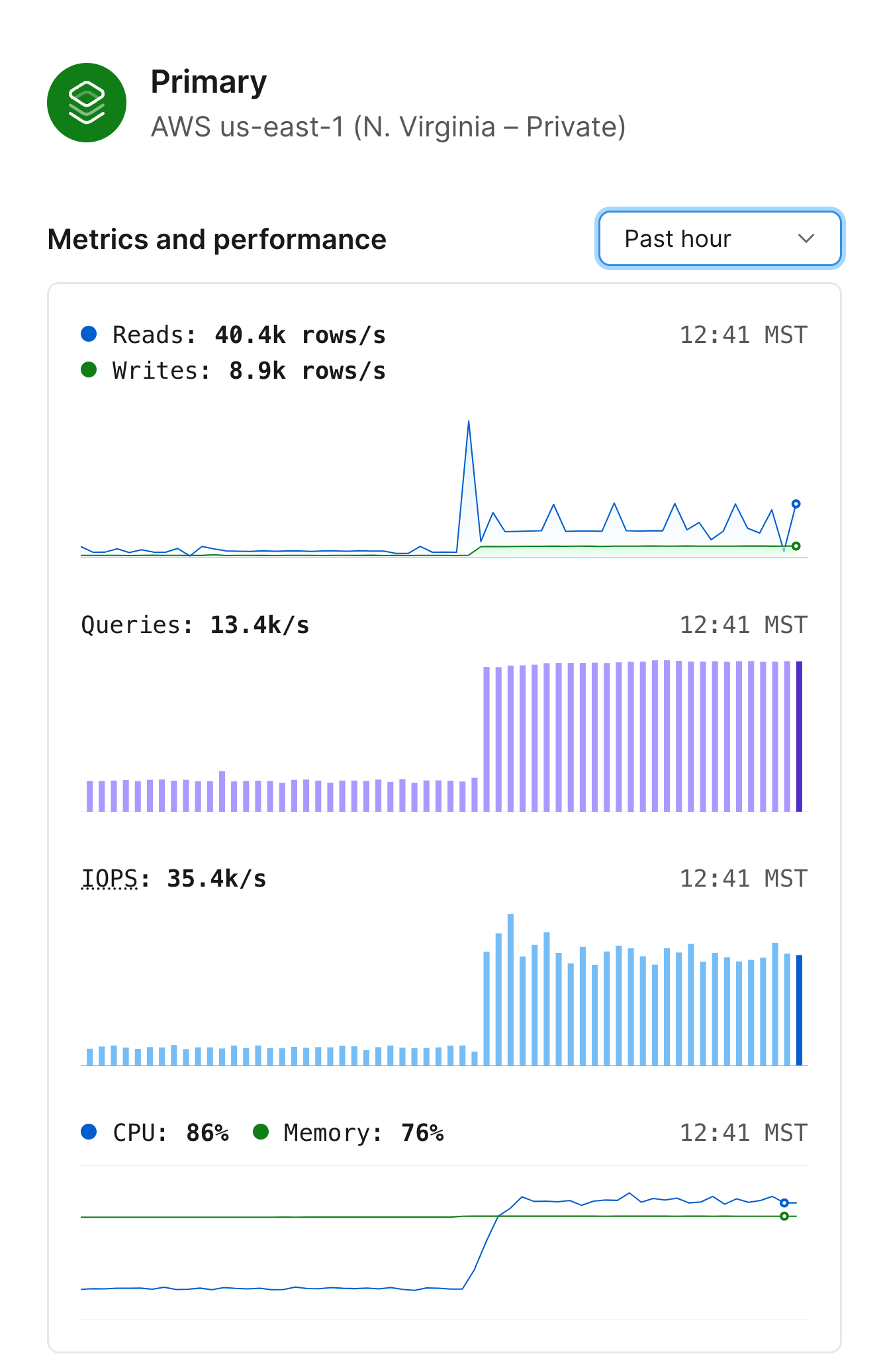
Why is Metal so much faster?
PlanetScale databases come in two main flavors: Metal and network-attached storage. Network-attached storage (Amazon Elastic Block Storage or Google Persistent Disk) databases store all data on storage volumes that are attached to your database’s compute resources over the network. For databases in AWS we use Elastic Block Storage (EBS) and in GCP we use Persistent Disk. These network-attached storage solutions are convenient for several reasons. For one, it is easy to resize such storage volumes. PlanetScale leverages this to auto-scale your storage as the size of your database grows or shrinks, allowing you to pay a per-GB storage price. This also means that you can pair a tiny compute instance with a large amount of storage. This works well for large data sets that are not frequently queried. The opposite is also true — you can pair a small amount of storage with a large compute instance for workloads that are heavily CPU-bound. One disadvantage of using network-attached storage storage is I/O latency. Reads from and writes to disk need to make network round-trips to be fulfilled. The intra-AZ network speeds in AWS and GCP data centers are generally very good, but still slower than accessing a locally-attached solid-state drive. There is also the issue of IOPS. The populargp3 EBS volume class provides 3000 IOPS included, but using more than this requires paying for additional IO bandwidth, leading to more expensive databases.
These disadvantages do not just apply to PlanetScale.
Many of the popular cloud-hosted database solutions, including those offered by Amazon and Google, use network-attached storage to simplify storage scalability.
This convenience and scalability comes at a performance cost.
Metal databases store all data on locally-attached NVMe SSDs.
Using direct-attached storage provides a clear solution to the performance issues described above.
The removal of network round-trips for I/O operations means low-latency IO, and we sidestep the issue of needing to pay for increased IOPS completely.
Your database now has the ability to use modern NVMe SSD technology to it’s full potential.