Today we introduce Gated Schema Deployments, which help us think of schema changes as more of atomic operations, solve the complexity of making changes across a sharded database, and answer one of the most common requests from our users. Let’s first understand what the deployment complexity is.
PlanetScale already offers non-blocking schema changes. You make some schema changes in your development branch, you submit a deployment request, it gets approved, and each change is then applied, non-intrusively, to your production database. Some deployments take mere seconds and some take hours, based on the size of the affected tables and based on the production workload.
The problem begins with multi-dimensional deployments. With these, you will either have multiple schema changes in the same deployment, or have a single change deployed over a multi-sharded database, or both.
The multi-change dimension
A schema deployment may contain multiple changes. Those will often correlate to each other. E.g., a new table is added, and a new column is added in an existing table, that refers to the PRIMARY KEY column of the new table. Or, maybe a new type of data is added (e.g., a location), that applies to many tables, and so multiple tables are modified.
The common practice to deploy multiple changes is to run them one at a time. A CREATE TABLE is a simple and lightweight enough of an operation, but an ALTER TABLE change is frequently heavyweight, and running multiple of those in parallel can hog your database. But running one migration at a time also creates a bit of discrepancy. Some of your changes may have been applied, some not. And should anything go wrong in the duration of the deployment, you’re left with a half-baked change.
With Gated Deployments, PlanetScale applies all changes as closely as possible, seconds apart from each other. In order to do that, it may run some migrations in parallel, but without exhausting database resources. Consider two ALTER TABLE changes over two large tables. The bulk work is copying over the existing table data, which is done sequentially per table. But tailing the changelog and applying the ongoing changes can be done in parallel.
We run as much of the bulk work as possible upfront, sequentially, and then run the more lightweight work in parallel. We thus maintain multiple schema changes at once, ongoing. Once all changes are in good shape, we complete the migrations as closely as possible. While not strictly atomically, the deployment can be considered more atomic; up till the final stage, no change is reflected in production. In fact, the deployment may be canceled at any point up until its completion time.
The multi-shard dimension
As your database scales, you want to address a new, multi-sharded dimension. By design, a multi-sharded database acts as though it were a monolith, and yet the shards are independent of each other. This has important benefits such as resource allocation or minimization of the blast radius when anything goes wrong. But it also raises new challenges: how do you keep the schema in sync across shards?
Different shards work under different workloads, and may run a schema migration to completion minutes to possibly hours apart. A multi-sharded database where different shards have different schemas can be either inconsistent in performance, or outright inconsistent in design.
Our gated deployments minimize that gap period, by tracking the progress of a schema deployment across all shards and holding off the final switch to the new schema until all shards are ready. The switch then takes place almost simultaneously (though not atomically) on all shards.
Solving the most requested schema revert feature: controlled gated deployments
PlanetScale offers a powerful flow: the ability to revert a deployment. A way to revert to the previous schema, but without losing any data accumulated in the interim. When a deployment completes, PlanetScale offers a 30 minute window in which it’s possible to revert, if needed.
The most common questions around our schema revert feature revolves about that time limit: “why 30 minutes?”, “What happens if the deployment completes at 2:00am over the weekend, and I can’t access my laptop in time?”, “Can we have better control over the timings?”
Responding to these questions, Gated Deployments now allow users to choose the deployment completion time at their discretion. By default, deployments auto-complete when ready, and this is great for most cases, and clears up the deployment queue. However, if the user so chooses, they may uncheck the "Auto-apply" box.
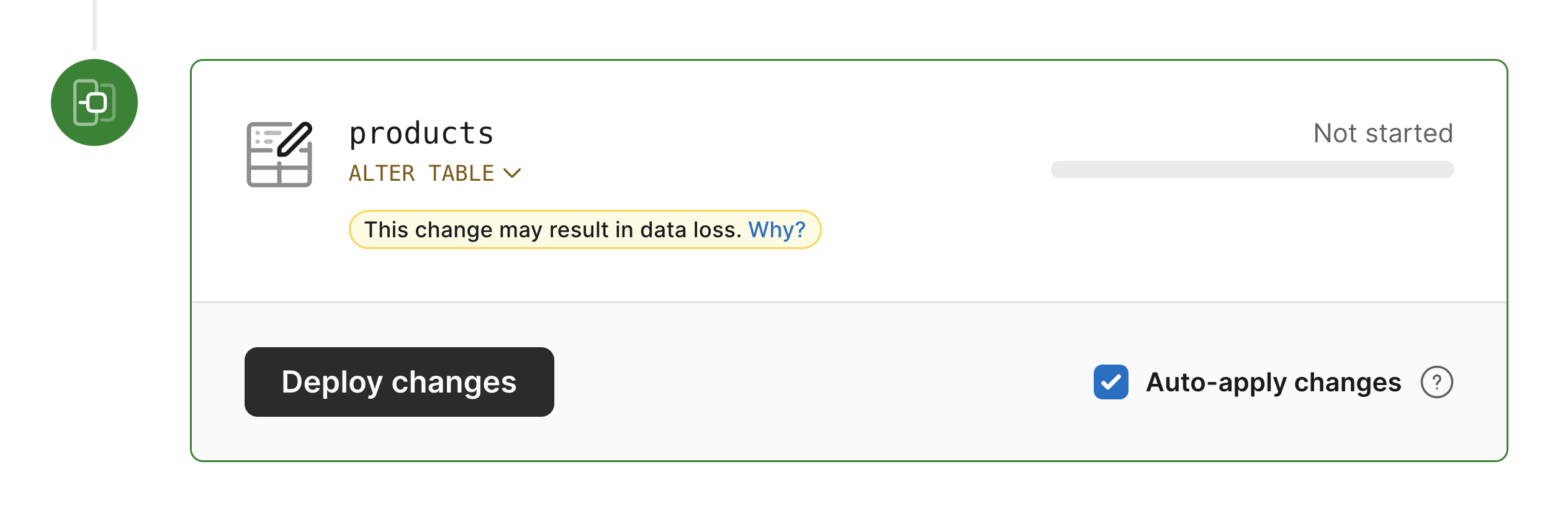
The deployment now stages all changes and runs all long-running tasks. When all changes are ready, the deployment awaits the user to hit the "Apply changes" button. With no input from the user, the deployment will just keep on running in the background, always keeping up to date with data changes.
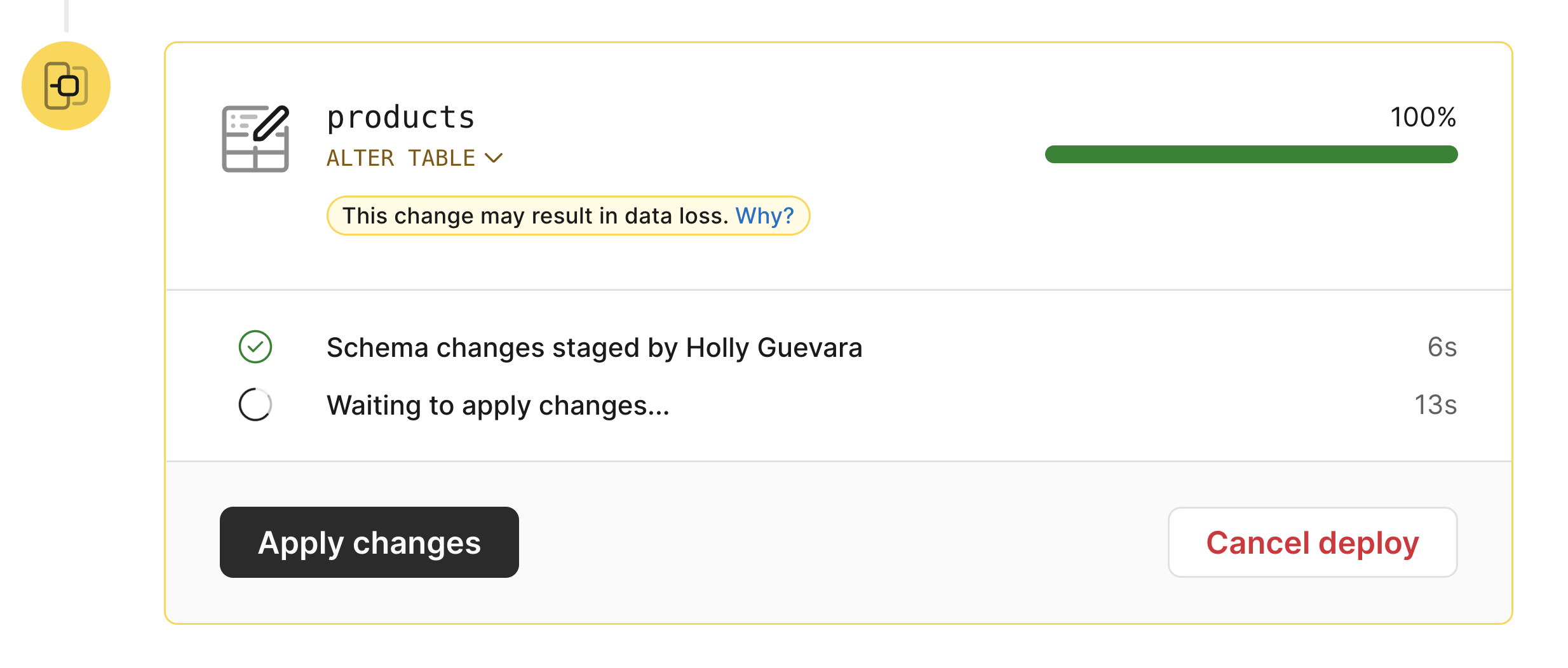
For example, a deployment with three ALTER statements over large tables may take a day to run. It may be 2:00am on the weekend when it finally completes the hard work of copying the dataset. But it won’t apply the changes: the deployment will just keep on syncing and responding to ongoing changes like any INSERT, DELETE or UPDATE on the relevant tables. Come Monday morning, when the developer is at their desk and fully prepared to begin their work week, they may click the “Apply changes” button. The deployment then completes, and the 30 minute window for schema reverts starts ticking, all while the developer is in control of the situation.
Try it out
This release of Gated Deployments brings us another step closer to our goal of a more modern and cohesive development flow, where schema changes happen alongside application development, not in isolation.