Overview
Schema recommendations uses query-level telemetry to generate tailored recommendations in the form of DDL statements that can be applied directly to a database branch and then deployed to production.Schema recommendations are also available through the PlanetScale MCP server, and can be automatically evaluated and implemented by AI coding agents on a recurring schedule. See Self-improving database.
If you are a PlanetScale Enterprise customer, please get in touch with your account manager to learn how you can fully benefit from schema recommendations.
How to use schema recommendations
To find the schema recommendations for your database, go to the “Insights” tab in your PlanetScale database and click “View recommendations.” You will see the current open recommendations that may help improve database performance. Select a recommendation to learn more. Each recommendation will have the following:- An explanation of the recommended changes, including some of the benefits of the recommended change (E.g., reduced memory and storage, decreased execution time, prevent ID exhaustion)
- The schema or query that it will affect
- The exact DDL that will apply the recommendation
- The option to apply the recommended change to a branch for testing and a safe migration
Schema recommendations that depend on your database traffic run once per day. Recommendations that depend only on database schema are run whenever the the schema of your default branch is modified. Schema recommendations are generated only for the database’s default branch.
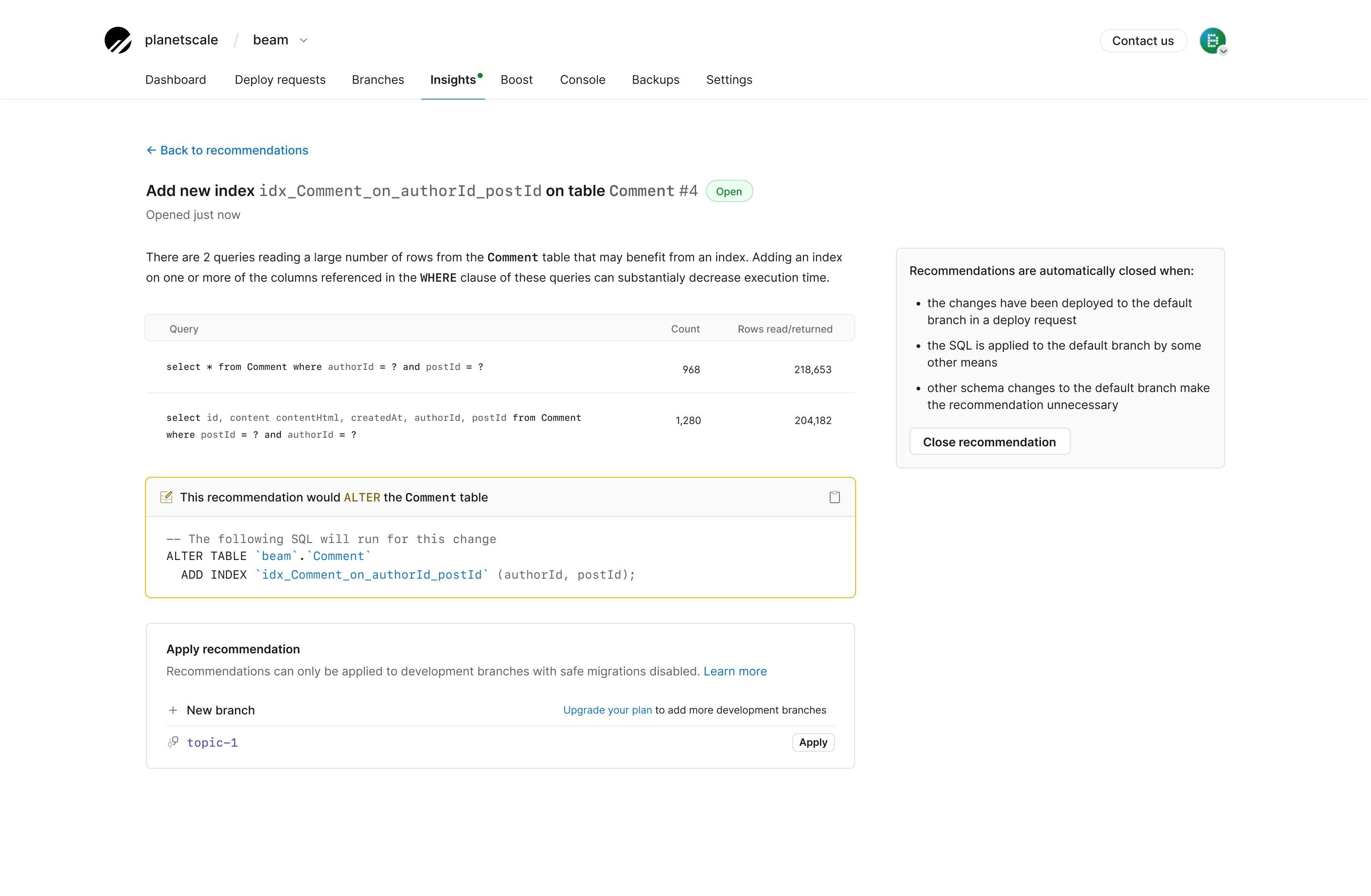
Applying a recommendation
Once you better understand the recommendation, you can apply the recommendation by either:- Applying it directly through a database branch
- Making the schema change directly in your application or ORM code
Applying a recommendation directly through a database branch
When directly applying through a database branch, you can apply the recommendation by creating and applying it to a new or existing branch. After applying the recommendation, click on the branch name to see the recommended schema changes. At this point, you can connect to this branch to do your own testing of the change. You can create a connection string for this branch using the “Connect” button. Once ready, you can use the “Create deploy request” button on the branch page to open a deploy request to merge the changes with your base branch. Once it is reviewed and ready to be deployed, you can deploy the changes to production. If you realize you have made a mistake, you can still revert the schema change in the deploy request for up to 30 minutes.Applying a recommendation directly in your application or ORM code
When directly applying through your application or ORM code, you can take the recommended change from PlanetScale and make the equivalent change in your code. The exact DDL provided in each recommendation will help you know what change to make. The exact change will depend on how you manage your schema in your application code. Then, once you have made the change, you will run the same migration process you would run for any other schema changes with PlanetScale. We recommend doing this inside a development branch with safe migrations. This will allow you to do your own testing of the change inside the isolated branch. You can create a connection string for this branch using the “Connect” button. Once ready, you can use the “Create deploy request” button on the branch page to open a deploy request to merge the changes with your base branch. Once it is reviewed and ready to be deployed, you can deploy the changes to production. If you realize you have made a mistake, you can still revert the schema change in the deploy request for up to 30 minutes.Closing a recommendation
Recommendations are automatically closed when:- The changes have been deployed to the default branch in a deploy request
- The SQL is applied to the default branch by some other means
- Other schema changes to the default branch make the recommendation unnecessary
Supported schema recommendations
The following are the currently supported schema recommendations:Adding indexes for inefficient queries
Removing redundant indexes
Preventing primary key ID exhaustion
Dropping unused tables
Upgrading legacy character sets and collations
Schema recommendations may not be in line with your desired outcomes. PlanetScale shall not be held liable for any actions you take based on these recommendations.
Adding indexes for inefficient queries
Indexes are crucial for relational database performance. With no indexes or suboptimal indexes, MySQL may have to scan a large number of rows to satisfy queries that only match a few records. This results in slow queries and poor database performance. The right index can reduce query execution time from hours to milliseconds. You can read more about how database indexes work in this blog post.How PlanetScale recommends adding indexes
To find missing indexes, Insights scans your query performance data to identify queries over the past 24 hours that consume significant resources and have a high aggregate ratio of rows read compared to rows returned. It will then parse the query to extract indexable columns, estimate each column’s cardinality (number of unique values) to determine optimal column order, and suggest a suitable index. In multi-column index suggestions, we first order columns with the most selective (highest cardinality). Our index recommendation engine doesn’t yet support all queries types, and some queries cannot benefit from an index.Caveats
- Indexes do require both more memory and storage. Evaluating these additional costs against your application’s improvement in read performance is always a good idea. This is also why we offer recommendations to remove redundant indexes.
- Indexing is a complicated topic and depends on many factors, such as the distribution of values in your database and the particular queries your database receives. Every effort is made to ensure our suggestions improve performance, but verifying and measuring is important.
- If you’re unsure about the impact of adding an index, we recommend benchmarking the index in a non-production environment. If you can simulate production-level traffic, you can do this inside a development branch.
- If you decide to deploy a suggested index to production, it is a good idea to use Insights to verify that your index has the desired effect on relevant queries. If you realize it is not the desired effect, you can still revert the schema change in the deploy request for up to 30 minutes.
Removing redundant indexes
While indexes can drastically improve query performance, having unnecessary indexes slows down writes and consumes additional storage and memory.How PlanetScale recommends removing indexes
Insights scans your schema every time it is changed to find redundant indexes. We suggest removing two types of indexes:- Exact duplicate indexes - an index that has the same columns in the same order
- Left prefix duplicate indexes - an index that has the same columns in the same order as the prefix of another index
Caveats
Removing redundant indexes is more nuanced than adding an index.- Exact duplicate indexes are always safe to remove.
- Left prefix duplicate indexes are almost always safe to remove, but in some cases can lead to a performance regression. Usually, the larger index can be used instead of the left prefix duplicate indexes. Read the following section for more details on how this works.
Left prefix duplicate indexes
Since MySQL can use the leftmost elements of a multi-column index to efficiently find rows, an index that is a left-prefix duplicate of another index can usually be removed. To understand this, consider the following table.idx_a_b or id_a_b_c to quickly find results because both indexes have a and b as the leftmost columns. In general, removing left prefix duplicates, idx_a_b in our case, will result in lower memory and storage usage and improve the performance of inserts, updates, and deletes to this table because there is one less index to be maintained. However, there are a few important caveats.
Queries that use the primary key
MySQL implicitly appends the primary key to the end of indexes. An index declared asKEY idx (a, b) can be thought of as KEY idx (a, b, id), assuming id is the primary key. This has the potential to affect queries that make use of the indexed columns and the primary key. For example:
idx_a_b because the ORDER clause is satisfied by the implicitly appended primary key. Since idx_a_b_c includes an additional column (c), MySQL must perform additional work to return rows in the correct order when using this index.
Index size
Even though MySQL can use either index in our table to efficiently look up rows by a and b, searching through the largeridx_a_b_c index may take longer simply because the index is larger and will require more pages to be scanned.
In most cases, you can safely remove redundant left-prefix indexes, resulting in better performance. However, ensure that your application doesn’t issue performance critical queries that the above mentioned issues will significantly impact. If you’re unsure about this, we recommend looking through your Insights dashboard to find queries that may be affected.
Preventing primary key ID exhaustion
As new rows are inserted, it’s possible for auto-incremented primary keys to exceed maximum allowable value for the underlying column type. When the column reaches the maximum value, subsequent inserts into the table will fail, which can cause a severe outage to your application.How PlanetScale detects primary key ID exhaustion
Insights scans all of theAUTO INCREMENT primary keys in your database schema and checks the current AUTO INCREMENT value daily to identify where you might be approaching primary key ID exhaustion. If Insights detects that one of the columns is above 60% of the maximum allowable type, it will recommend changing the underlying column to a larger type.
Additionally, Insights scans queries to parse joins and correlated subqueries to find foreign keys and suggests increasing the column size for those columns.
Caveats
- It is always a good idea to manually check your database and application for foreign key references to the column you are increasing to ensure none were missed.
Dropping unused tables
Dropping unused tables can help clean up data that is no longer needed and reduce storage. If the table is large, it can also decrease backup and restore time. If you are unsure if a table should be retained but decide to drop the table, make sure to create a manual backup of your database before you deploy the change. If you realize after dropping the table that it is needed, you can still revert the schema change in the deploy request for up to 30 minutes with no data loss. If you are outside the 30-minute period, you must restore and recover the data inside a database backup branch. If you determine that the table should be retained, close the recommendation, preventing the suggestion from being remade.How PlanetScale recommends dropping unused tables
Insights scans your query performance data daily to identify if any tables are more than four weeks old and haven’t been queried in the last four weeks.Caveats
- Only you can know if the table’s data is no longer needed. Ensure that the table is never used (even infrequently) and does not contain important data before removing it.
- Once a drop unused table recommendation is opened, it will remain open even if it is subsequently queried. Check your Insights data to verify that the table is still unused before permanently dropping it.
Upgrading legacy character sets and collations
All non-binary string columns, such asCHAR, VARCHAR and TEXT, have an associated character set and collation. The character set represents the range of valid characters and how they are stored. The collation controls how values are compared, such as in ORDER BY clauses and UNIQUE KEYs. Over time MySQL has added support for new character sets and collations. The most recent character sets and collations have numerous advantages over their legacy counterparts.
- Full Unicode support including emoji
- Improved performance
- Improved sort order for multi-byte characters
- Awareness of trailing spaces in comparisons
uftmb4 character set and the utf8mb4_0900_* collations. Unless you need byte-level comparisons (utf8mb4_0900_bin) or language-specific comparisons (e.g. utf8mb4_0900_es_* for spanish), we recommend using MySQL’s default collation utf8mb4_0900_ai_ci.
0900 in the name of MySQL’s modern collations refers to version 9.0.0 of the Unicode Collation Algorithm. ai and ci stand for accent insensitive and case insensitive, respectively. Accent and case sensitive collations are also available. To see a list of all available character sets and collations, connect to your database and run show collation;. When in doubt, use utf8mb4_0900_ai_ci.The
utf8 character set is, for compatibility reasons, an alias for utf8mb3. We suggest the utf8mb4 character set instead.Caveats
Joins
Before upgrading from a legacy character set/collation, it is important to ensure there are no joins on string columns that will become incompatible after the upgrade. For example, if you issue the queryt1.name and t2.name need to have have identical character sets and collations. If the character sets are the same but the collations are different, the query will fail. If the character sets are different, the query will succeed but will be unable to make use of indexes, which can cause unexpected table scans and dramatically degrade performance for large tables.
Character set/collation upgrade recommendations are not created for tables with a recent history of joins on string columns. However, we cannot automatically detect all join types so it is important to verify that your application does not join on a table’s string columns prior to deploying a recommendation that would alter its character set or encoding.
To upgrade the character sets or collations for tables that have string column joins, we recommend upgrading both tables to the same character set and collation in a single deploy request to minimize disruption.
Length limits
Length limit issues only apply when upgrading from
utf8mb3 to utf8mb4 character sets. Collation-only changes are unaffected.utf8mb3 to utf8mb4, it is possible that some adjustments will have to be made to column types. Because utf8mb3 is a subset of utf8mb4, existing data will not increase in size. However, utf8mb4 requires up to four bytes per character instead of up to three. Because of the this, some column type changes may be required.
Some data type changes occur automatically when applying the recommendation. TEXT-type columns increase to the next largest size (TEXT becomes MEDIUMTEXT, MEDIUMTEXT becomes LONGTEXT etc). Because utf8mb4 possibly requires an extra byte per character, and TEXT-type columns are defined by the maximum number of bytes, not characters, these columns are upgraded to ensure the ability to store at least the same number of characters in the column before and after the CONVERT TABLE command in the recommendation. If storing fewer maximum-length characters is acceptable, you can alter the deploy request produced by the recommendation to restore the original TEXT-type column definitions.
Other data type changes may need to be made manually. For example, the column definition VARCHAR(20000) CHARACTER SET utf8mb3 is legal, because 20,000 characters * 3 bytes per character = 60,000 bytes and VARCHAR columns can accommodate up to 65,535 bytes. However, when attempting to convert this column’s character set to utf8mb4, the number of bytes required to store 20,000 4-byte characters (80,000 bytes) is over the VARCHAR byte limit. In this case, the VARCHAR length can be decreased, or the column can be changed to MEDIUMTEXT.
Migrating from utf8mb3 to utf8mb4 may cause indexes on string columns to exceed the maximum number of bytes per entry (the maximum is dependent on the row format). If this happens, an index prefix length can be added or the existing prefix length can be reduced to bring the number of bytes under the limit.
For more details, see the MySQL docs for utf8mb3 to utf8mb4 conversion.
Padding
Legacy MySQL collations ignore trailing whitespace. For exampleSELECT * FROM t WHERE a = 'a' and SELECT * FROM t where a = 'a ' (note trailing whitespace) are functionally identical if column a has a legacy MySQL character set. Usually trailing space-aware comparisons are more in line with developer expectations, but it is important to verify that this change in behavior won’t adversely affect your application.
For more details, wee the MySQL docs for collation padding