Zero downtime Rails migrations with the PlanetScale Rails gem
Learn about the Ruby on Rails workflow that protects your database and application from accidental downtime and data loss.
We've recently released the planetscale_rails gem. It contains a collection of Rake tasks that we have been using internally to manage the schema of our own Rails application.
The workflow we use to build the PlanetScale Rails application allows our engineers to ship changes without the fear of downtime. This leads to faster releases and an all-around more confident team. In this blog post, I'm going to go over the risks of running Rails schema migrations directly on your production database and teach you how to set up a workflow that mitigates those risks.
The ultimate production schema migration workflow
Before digging in, let's go over the high-level workflow we use for our own Rails application. We run MySQL locally to make schema changes in development and use PlanetScale branches once we're ready to deploy to production.
Our team uses GitHub for code review, and we automatically deploy code changes when a pull request is merged into main. We separate our schema changes from our code changes, and for those, we use PlanetScale deploy requests.
Separating out schema changes from code changes may be a new concept for some, but it's an essential part of shipping changes without risk of downtime.
How PlanetScale deploy requests prevent downtime
PlanetScale databases introduce a git-like workflow for making schema changes. When you're just getting started, we provide a default main branch that you can run your initial migrations on. Once you're done, you promote that branch to production and connect it to your production application. Now, whenever you need to make schema changes, you can branch off of that production schema, make your schema changes on that dev branch, and open a deploy request to deploy to production with no downtime. The deploy request is how we make safe schema changes in PlanetScale databases. Think of it as a very advanced version of rails db:migrate. Under the hood, it uses Vitess's online schema migration tooling, which allows you to make schema changes without worrying about accidentally causing a production incident by locking a table.
The best part, if something does go wrong, you can also revert it without data loss. Sounds impossible, but you can read through our How schema reverts work blog post if you want the details on how it all works.
We love using rails db:migrate for development. But when it comes to production, we prefer the safety that deploy requests provide.
Deploying schema changes before code changes
Many Rails applications are set up to run their production schema migrations during their deployment process.
While this setup feels easy, "you just merge!", we do not recommend it.
When the code and schema deploys are coupled, we've found teams eventually run into problems. Migrations are slow on large tables, or worse, fail completely. Both of these cases block the flow of code getting into production.
Deploying code to production and migrating the database are two of the highest risk actions engineers do in their work. For these tasks, we prefer to focus and take care of each important step one at a time.
It's also impossible to atomically deploy both code and a schema change at the same time. If either is dependent on the other, users will experience errors or downtime. Having engineers focus on how to get both their code and schema changes out separately forces best practices to be implemented. And, fortunately, it doesn't take too much extra work to set up this safe, no downtime workflow.
The no downtime PlanetScale + Rails workflow
Here are the details of how an engineer on our team gets a schema change into production. Again, make sure you first have your PlanetScale database set up with a production branch with safe migrations enabled. If not, follow our Rails quickstart to get connected.
- Follow the instructions in the
pscaleREADME to install the PlanetScale CLI. - Follow the instructions in the
planetscale_railsREADME to install theplanetscale_railsgem - Create a new PlanetScale branch via the CLI
pscale branch switch my-feature --database my-db-name --create
Notice that you're using switch here. This places a .pscale.yml file in your local directory. This is how Rails will know which branch to migrate.
- Run Rails migrations on the new branch (using
planetscale_rails)
bundle exec rails psdb:migrate
- Open a new PlanetScale deploy request
pscale deploy-request create database-name my-feature
- Open a pull request on GitHub
Now, just like a normal code change, the engineer will push up their migration file and schema.rb changes in a pull request to be reviewed. They'll include a link to the deploy request in their PR description.
- Once both deploy and pull request are reviewed. The PlanetScale deploy request will be shipped first. Once successful, then the code gets merged in.
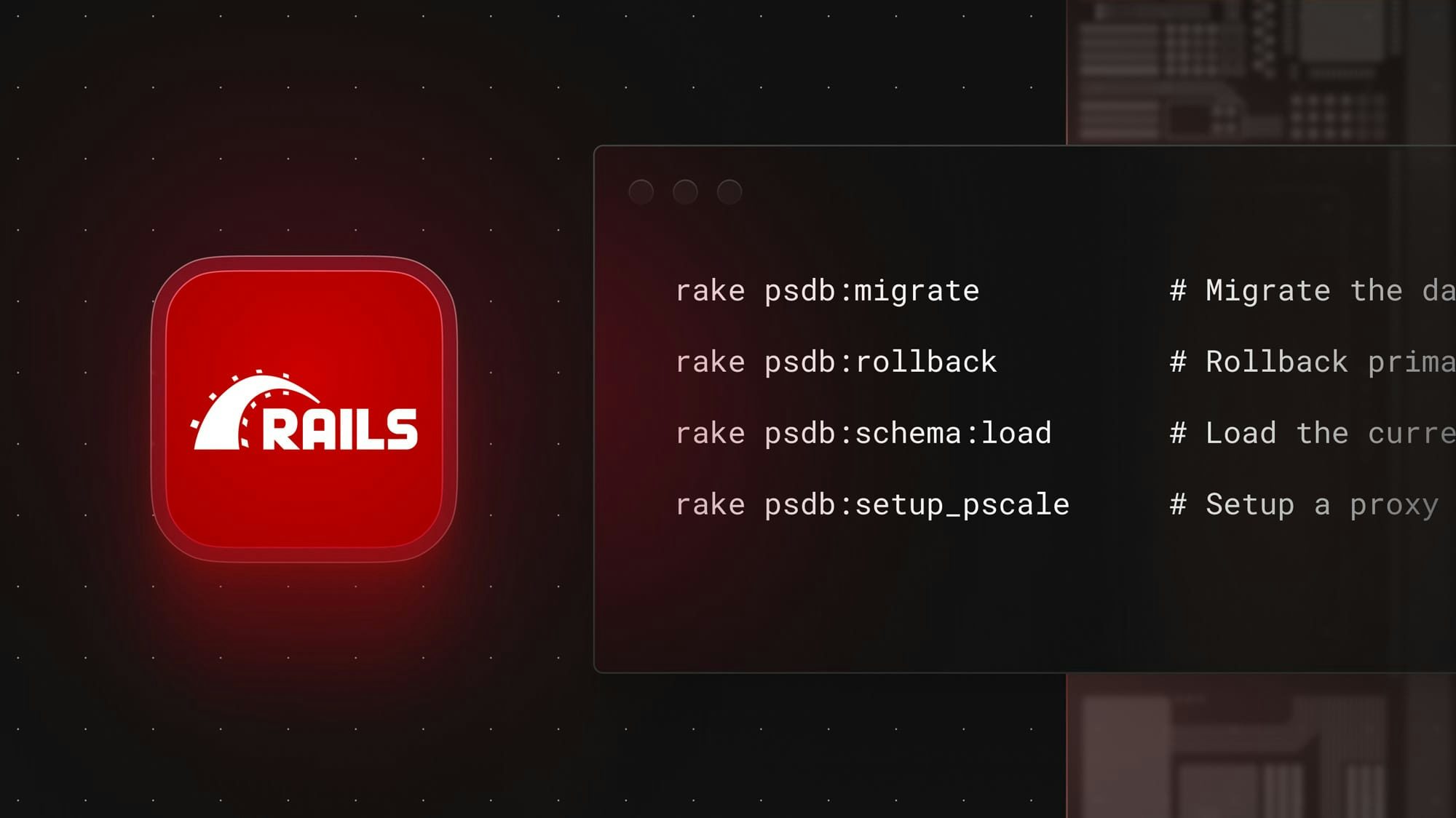
planetscale_rails rake tasks
In the above example, we used rake psdb:migrate. Here's the full list of tasks made available by the gem:
rake psdb:migrate # Migrate the database for current environment
rake psdb:rollback # Rollback primary database for current environment
rake psdb:schema:load # Load the current schema into the database
rake psdb:setup_pscale # Setup a proxy to connect to PlanetScale
Migrate and rollback also work in multiple database Rails apps. For targeting a different database, you can add onto the command just like a normal db:migrate, rails psdb:migrate:primary, or rails psdb:migrate:rollback.
Managing schema_migrations table
You may be wondering what happens with the schema_migrations table when using PlanetScale deploy requests. The answer is, nothing changes! Deploy requests will keep it up to date just like db:migrate does for you. When branching, the schema_migrations table gets copied across branches.
To have this work, all you need to do is head to your PlanetScale dashboard, go to your database "Settings" page, and enable "Automatically copy migration data" for the database.
No downtime example migrations
Let's go through some common scenarios to see how we can accomplish these safely.
Adding a database column
To add a new column safely, you must always deploy the schema change before any code using the column is deployed to production.
- Make the schema change via a Deploy Request
- Merge in the code that uses the new column
Since we are using Deploy Requests, we do not need to worry about default values. PlanetScale's schema change tools will add the column and the new default value without any table locking.
Removing a database column
Removing a column is one case where we do want to deploy some code prior to running the migration.
- Set the column as ignored in the model and deploy this change to production.
class Project < ActiveRecord::Base
self.ignored_columns += %w(category)
end
This ensures your application is not using the column in production and removes the risk of any errors when you do run the migration.
After this change is deployed, you can also check Insights to be sure it's not being used in any queries before moving on.
Run the Deploy Request to remove the column
Once the Deploy Request is complete, you can now clean up the
ignored_columnscode and deploy it to production
Renaming a database column
Renaming a column may seem like a simple change, but doing so without any interruption to production takes some extra care.
We cannot rename a column directly without downtime. Instead, we must add a new column and then transfer all the data to it.
Each step in this is a production deployment.
- Run a migration to add the new column
- Update the application to start double writing to both the old and new column
How to do this will depend on the application. ActiveRecord callbacks can be a useful tool here.
- Run a backfill script that updates the new column
# Example backfill script
Project.all.find_each do |project|
project.update(:new_column, project.old_column)
puts "updated #{project.id}"
end
- Update the application to start reading from the new column. Remove the double writes
- Remove the old column.
It is a bit of extra work, but taking these steps ensures a safe transition to the new column and no interuptions to production traffic.
Adding or removing indexes
When using Deploy Requests, there is no risk of table locking while adding or removing a database index. This scenario is quite simple.
- Run the schema change via a Deploy Request
- Merge in the code with the migration file and schema.rb changes
Removing an index can be risky if the application is actively using it. Be sure to check that it's not being used by any queries in production before removing it. One simple way to check is by running the following in your production database.
select * from sys.schema_unused_indexes;
This query will return any unused indexes since MySQL's last restart. If your application runs infrequent scheduled jobs, it may be possible for an index used by that job to show up as unused when running the query.
Handling data migrations
Occasionally, we also need to backfill or migrate data as part of our schema changes. We handle this by running the data migration in production after the schema has been changed.
For example, if we need to backfill a column. We'll run the following script in a production Rails console session.
# use find_each to limit data in memory
Project.all.find_each do |project|
project.update(:new_column, project.old_column)
# print progress to the screen
puts "updated #{project.id}"
end
This is a simple data migration. There are cases where the migration is more complex, and we need to take more precautions. For those cases, we'll setup a Ruby class that manages the migration for us. This allows it to be tested and code reviewed before being run in production.
class MigrateProjectData
def self.run
initialize.run
end
def run
# migration logic here
end
end
We then deploy this code and call it from a production console with: MigrateProjectData.run.
Conclusion
Hopefully this guide has helped you level up your Rails deployment workflow. While the extra steps and thoughtfulness required may seem like a lot of additional work upfront, we promise it'll become second nature very quickly. In the end, it will likely save your team more time overall because everyone will feel more confident making schema changes, leading to faster release times. And, if you ever end up in the unfortunate scenario that you accidentally shipped a bad schema change, you'll be able to revert it with the click of a button using this workflow.