At PlanetScale, we speak to developers at all stages of their database journey. The diversity of database products on the market today can make choosing the right one for your needs extremely difficult. The purpose of this blog post is not to reduce the complex database landscape to a simplistic view, but rather to offer a framework for developers to consider as they start to think about building applications for production.
In this post, we will explore how to identify data processing methods for your workload so you can optimize the performance, scalability, and security when choosing the database for your modern application.
A brief overview of the database landscape: OLAP and OLTP
OLTP (Online Transaction Processing) and OLAP (Online Analytical Processing) are two different types of data processing systems that are often used together in traditional architectures.
OLTP is used for processing high volumes of small, transactional data. It's often used for applications such as e-commerce, banking, and social media.
OLAP databases are designed to handle complex queries that require analysis of large amounts of data. They are often used for applications such as business intelligence and data mining.
The combination of OLTP and OLAP systems provides businesses with a powerful tool for managing and analyzing their data. OLTP systems handle the day-to-day transactions, while OLAP systems provide insights into the data that can be used to make better business decisions.
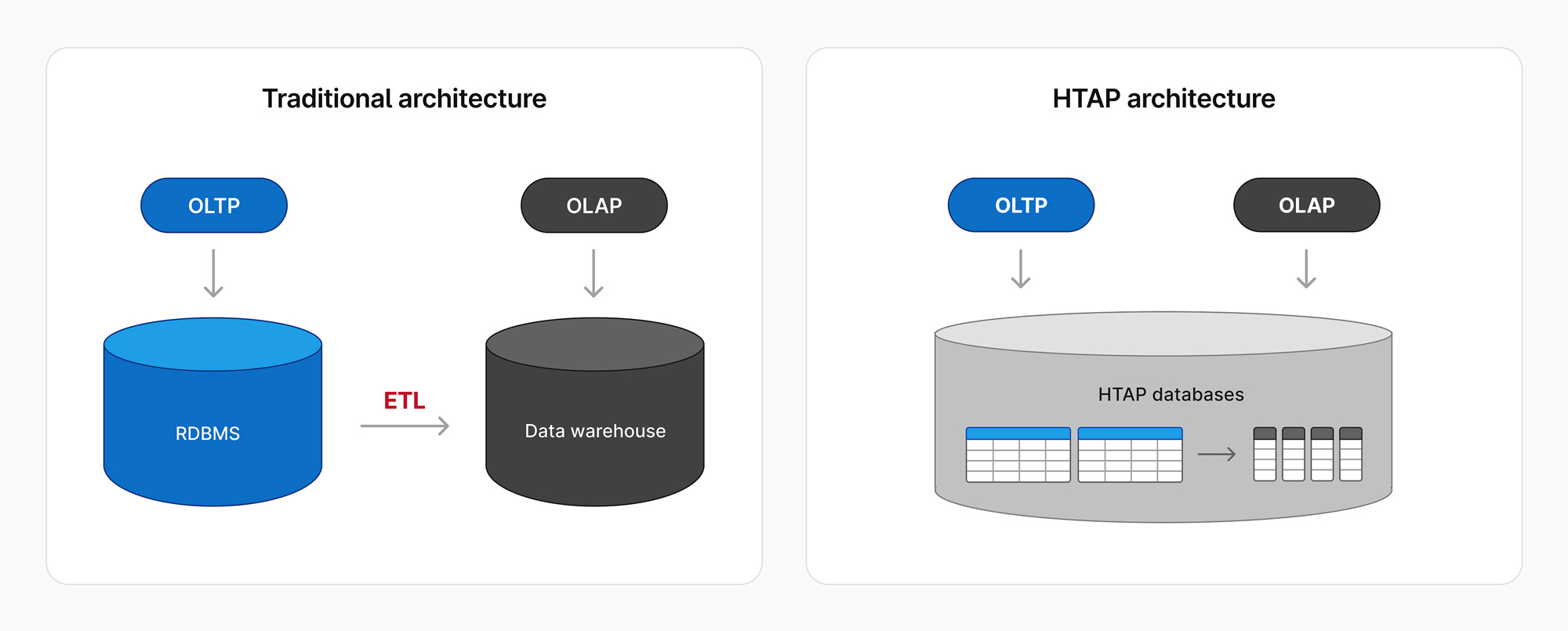
In recent years, there has been a rise of HTAP (Hybrid Transactions and Analytics Processing) databases to target new applications that require both analytics and transactions. To understand HTAP, we need to understand the history of OLTP and OLAP systems.
Relational databases have been used for both transaction processing and analytics, but OLTP and OLAP systems have different characteristics. OLTP systems are designed for individual record insert/delete/update statements and point queries that benefit from indexes. OLAP systems are designed for batch updates and table scans. Batch insertion into OLAP systems is typically done through ETL (extract transform load) systems that consolidate and transform transactional data from OLTP systems into an OLAP environment for analysis.
HTAP: benefits and categories
Through extensive marketing efforts, HTAP has been positioned as a promising new computing paradigm that will solve performance, cost, and complexity challenges that arise from managing two separate workloads. HTAP systems can be broadly classified into three categories:
| Shared-everything architectures | Shared-nothing architectures | Hybrid architectures |
|---|---|---|
| All data is stored in a single shared storage system | Each node in the cluster stores its own data | Combines elements of both architectures, typically storing transactional data in a shared-everything system and analytical data in a shared-nothing system |
| Simplest to implement and ensure data consistency; can be limited in scalability | More scalable, with possibility to scale horizontally; can be more difficult to implement and manage | Can be difficult to ensure data consistency, especially when there are concurrent transactional and analytical operations; can be limited in scalability |
There have been many different approaches to building out these HTAP systems:
- In-memory HTAP databases: In this type of architecture, each node in the cluster stores its own data in memory. This makes it possible to scale the system horizontally, but it can also make it more difficult to ensure data consistency. It also becomes more expensive because it requires a lot of memory.
- Columnar HTAP databases: These systems store data in a columnar format, which is optimized for analytical queries. Columnar systems can provide good performance for analytical queries, but they can be slower for transactional queries.
- Separation of storage and compute databases: This separates the storage of data from the processing of data.
- Hybrid HTAP systems: These store transactional data on disk and analytical data in memory.
Challenges with HTAP
There are inherent challenges with HTAP systems that can hinder their ability to optimize efficient data processing for modern applications at a large scale. Although every use-case is different, there are some factors to consider where HTAP systems can become prohibitive.
- Mixed workload complexity: HTAP databases aim to accommodate both transactional and analytical tasks within a single system. However, this leads to a complex environment where the database must juggle the demands of high-speed transaction processing and resource-intensive analytical queries. This inherent conflict in requirements can result in performance compromises.
- Performance trade-offs: In HTAP setups, optimizing for one workload often comes at the expense of the other. For instance, in pursuit of quick transaction processing, analytical queries might experience slowdowns due to the shared resources. Conversely, if resources are allocated to enhance analytical performance, transactional operations could suffer, leading to increased latencies and reduced throughput.
- Data model mismatch: OLTP and OLAP workloads typically involve different data models. OLTP transactions focus on updating individual records and maintaining data integrity and consistency, while OLAP operations involve complex aggregations and scans. Trying to fit both types of workloads into the same data model can lead to suboptimal design compromises that hinder efficient processing for either workload.
- Scalability challenges: Large-scale modern applications often require horizontal scalability to accommodate growing data volumes and user loads. HTAP databases can face difficulties in maintaining the same level of performance and scalability as specialized solutions tailored solely for one type of workload. Balancing the expansion needs of both transactional and analytical components becomes increasingly complex as the system grows.
- Resource contention: In HTAP systems, contention arises when transactional and analytical workloads vie for the same resources, such as CPU, memory, and I/O bandwidth. This contention can lead to resource bottlenecks, unpredictable performance fluctuations, and overall system instability.
- Maintenance and administration complexity: HTAP databases demand more intricate administration and maintenance compared to standalone OLTP or OLAP systems. Database administrators must manage the configuration, tuning, and optimization of the system to ensure both transactional and analytical workloads perform adequately. This complexity can result in increased operational overhead and potential human error.
- Limitation in analytical processing: While HTAP databases can provide insights from operational data in near real-time, their analytical capabilities might not match those of dedicated data warehousing solutions designed explicitly for complex analytical queries and reporting. Specialized analytical databases can employ more sophisticated optimization techniques for complex analytical operations, offering superior performance and richer insights.
- Evolution of data processing architectures: Modern applications often incorporate distributed computing, microservices, and serverless architectures. These architectures are designed to optimize specific types of workloads, potentially making it challenging to fit a hybrid database into the larger application ecosystem and take full advantage of emerging technological trends.
The PlanetScale approach
PlanetScale does not claim to be an HTAP database, nor are we an OLAP database built for pure analytical workloads. Instead, PlanetScale offers the only managed Vitess solution and we are optimized for OLTP workloads.
As developers who have worked with databases in production at some of the largest proprietors in the world, we understand that every application is different, and finding a single database that offers a one-size-fits-all approach often means making compromises.
If you have a complex application with distinct transactional and analytical workloads that can be separated, then it may be more appropriate to use separate databases for each workload. This approach allows each database to be optimized for its specific workload and can provide better performance and scalability.
Physical resource isolation is an effective way to guarantee the performance of transactional queries. Analytical queries often consume high levels of resources such as CPU, memory, and I/O bandwidth. If these queries run together with transactional queries, the latter can be seriously delayed.
For large ETL workloads, we support and recommend data integration engines such as Airbyte, Fivetran, and Stitch, with which you can offload these processes to other platforms that are more specialized in OLAP workloads.
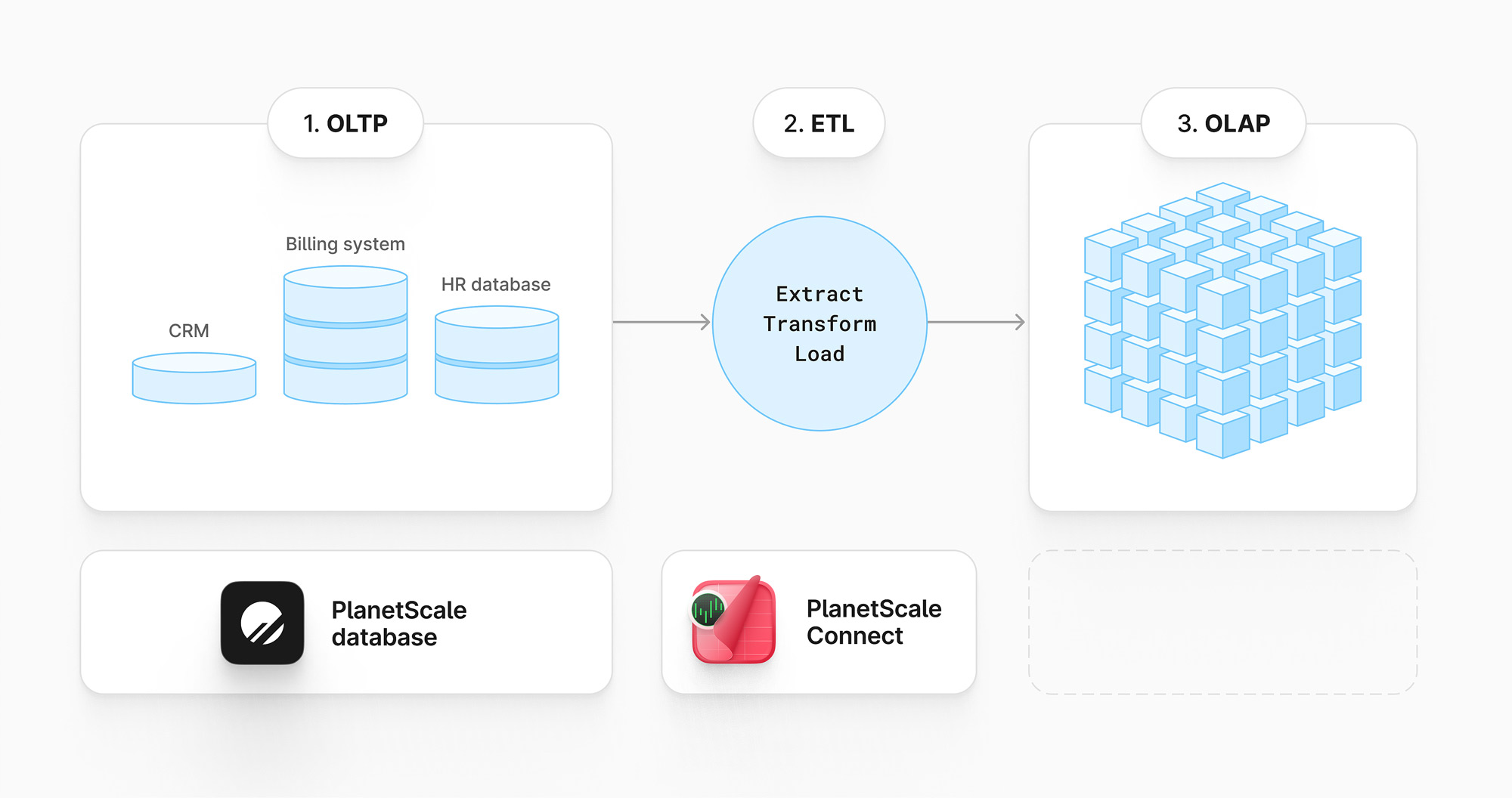
Sign up to try it out yourself, or reach out to talk to us if you’d like to learn how PlanetScale can fit into your data pipeline.