Getting started with a relational database can seem like a daunting task. Whether you’re coming from a NoSQL database or you’ve never used a database before, I’m going to talk you through designing a relational database and am hoping to answer the following questions:
- What is a relational database?
- How are relationships made in the database?
- What are the steps to take to ensure an efficient database?
What is a relational database?
A relational database is one way to store data related to each other in a pre-defined way. By pre-defined, we mean that at the time of the creation of the database, you can identify the relationships that exist between different entities or groups of data. Relational databases are great for storing structured data that should model the relationship between real-life entities.
The anatomy of a relational database:
- Tables: Data representing an entity organized into columns in rows.
- Properties: Attributes that you want to store about an entity.
- Relationships: The relationships between tables.
- Indexes: Useful for connecting tables and making quick look-ups.
A relational database is made up of two or more tables with a variable number of rows and columns. Tables are unique to the entity they represent. Each column represents one specific property associated with each row in the table, and the rows are the actual records stored in that table. To illustrate the magic of a relational database, we’ll be designing a database for a retailer that wants to manage their products, customers, orders, and employees.
Design a database for a new retailer in town. This retailer really cares about customer relationships and wants to reward customers who meet a spending goal and gift these top customers on the 1 year anniversary of their first purchase. This retailer needs a way to organize products by price and category to make smart recommendations to their customers based on their age. This retailer also wants to track the best-performing employees to reward those with the highest sales with a raise at the end of the year.
Designing the database schema
The schema is the structure that we define for our data. The schema defines the tables, relationships between tables, fields, and indexes.
The schema will also have a significant impact on the performance of our database. By dedicating time to the schema design, we will save ourselves a headache in the future. One tool that will help us design our schema is an ERD, entity-relationship diagram. We’ll use Lucidchart to build out our ERD, and you can sign up for free. This diagram will allow us to visualize our entities and their relationships.
Here are the major to-dos when designing our schema we will cover in this post:
- Understand business needs
- Identify entities
- Identify properties/fields on those entities
- Define relationships between tables
Step 1: Understand business needs
The first step in designing a relational database schema is to understand the needs of the business. This will help us determine what type of information we should be storing. For example, if we are working with a retailer that wants to offer an anniversary gift for clients on their first anniversary, we would have to store the date a customer joins.
A recap of the requirements for our customers:
- Store customer spending to-date
- Store customer anniversary date of first purchase
- Store customer’s age
- Store employee sales total in dollar amount
- Store products and include a category and price property
Step 2: Define entities, aka tables

Once that is clear, the next step is defining the entities we want to store data about. These entities will also be our tables. Following the retailer example, our entities should be:
- customers
- products
- orders
- employees
This could extend to add more entities like stores if there are multiple storefront locations, manufacturers, etc., depending on the needs of the business. For this blog post, we’ll just be working with the four entities we defined above to meet the needs of our fictitious client. We can represent an entity in our ERD with a rectangle and the table/entity name at the top.
Step 3: Define properties, aka fields
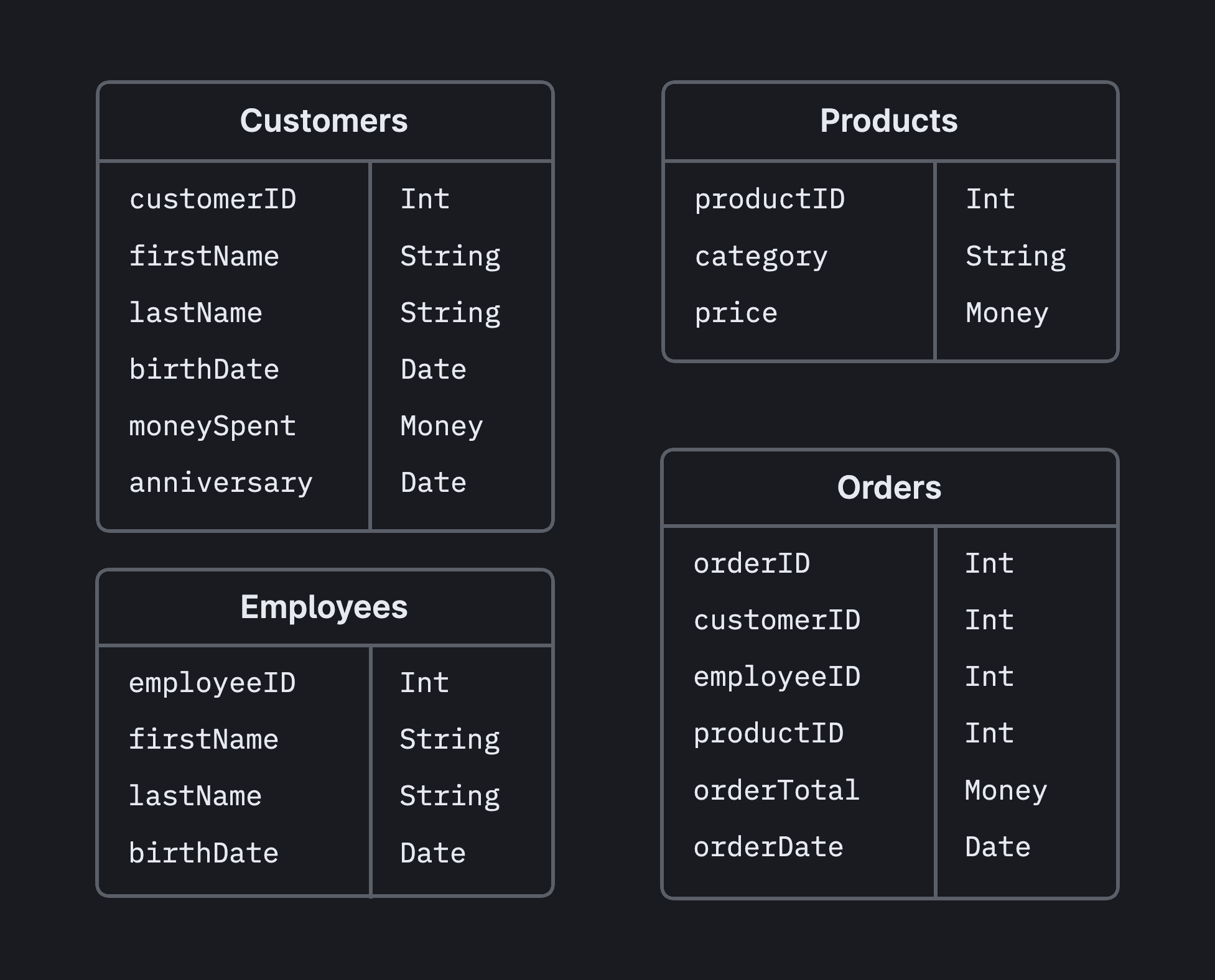
Once we’ve identified our entities, we should define what fields we want to store about these entities. One important thing to keep in mind is that each table, or entity, should have one unique, identifying property. This unique value is known as the primary key, and this helps us differentiate records from each other. For example, if we have two customers with the same name or same birthdate, we would have to spend some time figuring out which customer is the one we intend to work with.
Two common ways to come up with a primary key:
- Programmatically generate a unique value
- Assign an integer that automatically increases with each new entry
All of these are straightforward and were taken directly from the specs that the business gave us. For example, the business wants to know which customer made the purchase, which employee made the sale, and which products were in the order. In the Orders table, you will noticed that we reference a customerID, employeeID, and productID to meet those needs.
Step 4: Define relationships
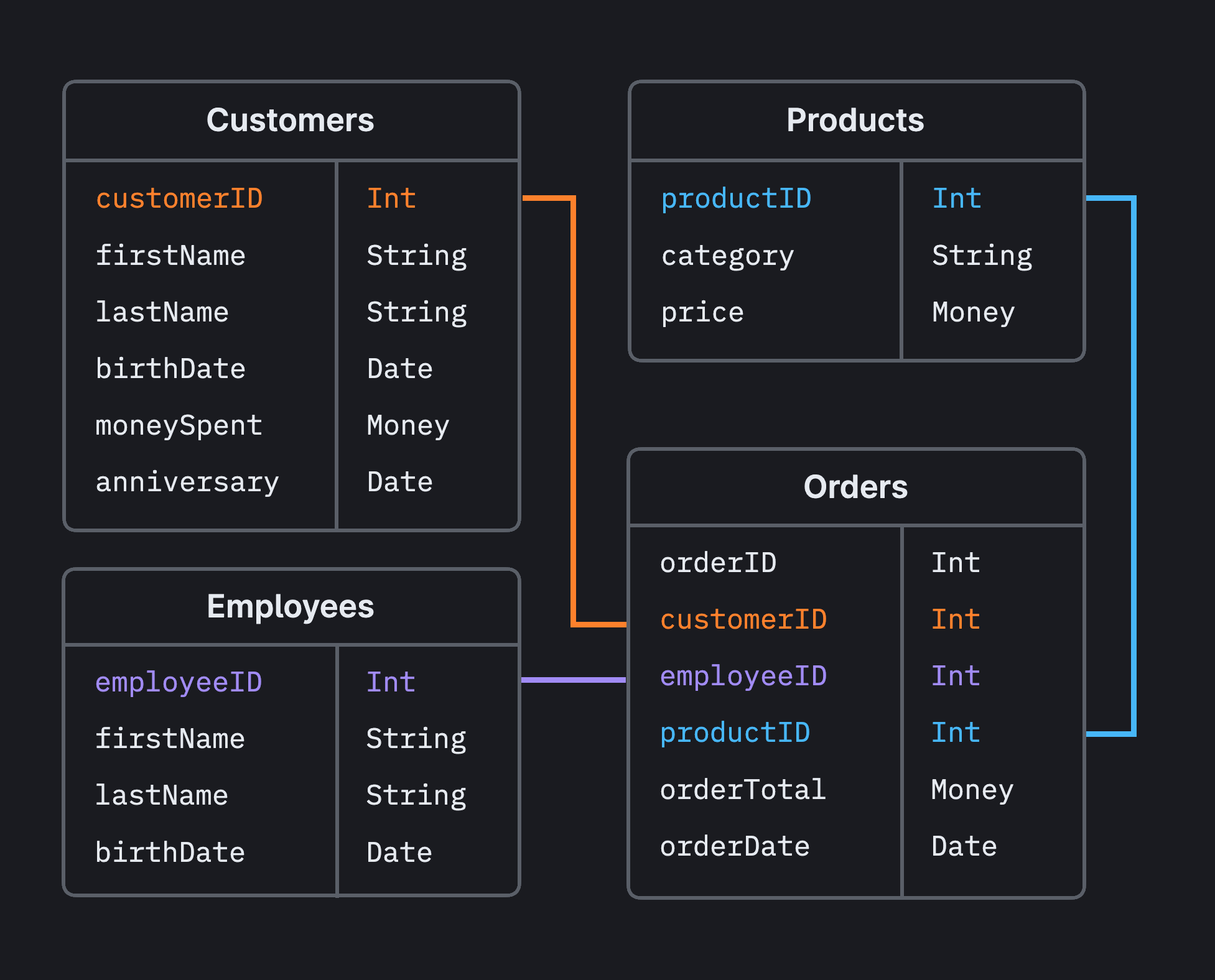
Once we’ve defined our entities and their properties, we can think about how these tables relate to each other. The cornerstone of relational databases is that tables are often related. A parent table will have a unique primary key column, and a child table will have its own primary key and then a parent_id column that references the parent table. We have already inadvertently done this when we defined the properties in the preceding step. For example, the customers table has a customerID, which is the primary key. In the Orders table, we set an orderID as the primary key and reference the customerID to denote which customer made the order. Similarly, we also have a column referencing the Employees table, employeeID, to denote which employee made the sale.
When a primary key appears in another table, that field is called a foreign key in that table. The relationship between primary keys and foreign keys creates the relationship between tables.
You’ve done it
We’ve covered the main steps to take when designing your database schema: understand the business needs, define entities, define properties, and define relationships. Designing your database schema can be scary because with traditional relational databases, some schema changes can bring your whole application down and cause you to lose data. With PlanetScale’s branching feature, you can branch your schema like your code. Test your schema changes in an isolated environment, and once you are happy with your new schema, you can merge your changed branch into your main production branch without experiencing any downtime or data loss. Sign up for a PlanetScale account to get started.