Scaling challenges, frequent maintenance tasks, constant fear of when it's going to all fall over, and quickly rising costs — these are all common issues that teams will put up with just to avoid the task of migrating a database that has outgrown its home.
And with good reason. There is a lot of risk in moving from one database server or system to another: extended downtime, data loss, version incompatibilities, and errors no one could have even predicted.
But what if I told you it doesn't have to be this difficult? At PlanetScale, we regularly migrate databases in the terabyte and even petabyte range to our platform — all without any downtime. Our process allows us to do heavy testing with production traffic prior to cutover and even reverse the migration back to the external database if needed.
To give you a sense of the scale involved, you can see the size of one of the larger data sets — after migrating only a subset of the databases to date — that originated from migrations here:
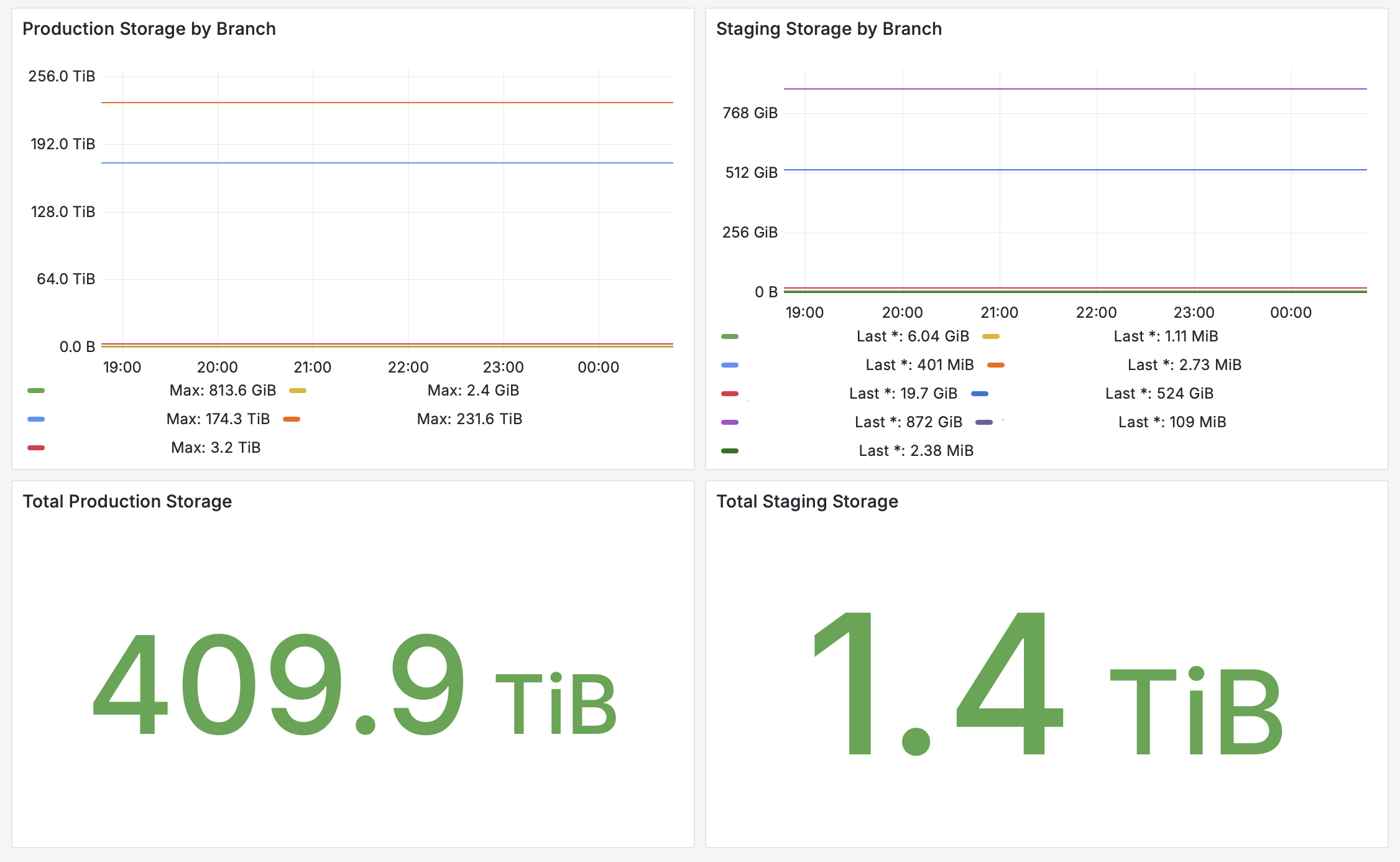
In this article, we'll take a look under the hood to show you how our migration process works and what allows us to handle huge data migrations with no downtime.
Data migrations
Before we get into the specifics, let's cover the high level problem and lay out the relevant terminology so that we can better understand and appreciate the details.
A data migration is the process of moving data from one database server or system to another — with the goal of transferring the responsibility for housing and serving this data from the old system to the new at a future point in time, often called the point of cutover. Each database vendor and system will have some paved roads for this process. For example MySQL has mysqldump and mysqlimport while PostgreSQL has pg_dump and pg_restore for logical data copies. And both products have methods for setting up replication from the old to the new system if the new system is of the same type as the old (e.g. MySQL to MySQL). Common migration examples being upgrading across several major versions of the same database system (e.g. PostgreSQL 13 to 16), or moving from one database system to another (e.g. PostgreSQL to MySQL or vice versa).
How data migrations work
At a high level, this is the general flow for data migrations:
Take a snapshot of the data in the old system.
- This can be done with a logical backup or a physical (volume/filesystem/block device) snapshot, with a logical backup being decoupled from the storage and offering the ability to migrate across different databases and storage types.
Restore the snapshot to the new system.
- Either replaying the SQL statements in the logical backup or restoring the physical snapshot to the new system
Verify the new system.
- Perform at least some basic checks to ensure the new system is able to read and serve the data we expect to see.
Cutover application traffic to the new system.
- Have all applicable applications start sending read and write traffic to the new system.
Decommission the old system.
- Once you're satisfied with the new system behavior, you can completely shut down and optionally archive the old system.
The simplest of processes would incur extensive downtime — and at least write unavailability — which covers all of these steps so that the system is read-only from the time that step 1 starts to the time that step 4 is complete. That can take hours, days, or even weeks. So this is not always acceptable for production systems, especially those of considerable size and which are expected to be available 24/7. This also offers no way to revert the cutover step if for some reason things go poorly afterward — e.g. some of your common queries may now throw errors or perform much worse than before.
An ideal process would allow us to perform all of these steps without any downtime and offer the ability to revert the cutover step if necessary — i.e. to support cutting over traffic in both directions until we're satisfied with the end state (and only at some point after that would we decommission the old system). The process which PlanetScale uses has been very intentionally designed to meet these criteria! Now that we've laid the groundwork, we can start to dive into the specifics.
Data migrations at PlanetScale
The process of migrating data at PlanetScale is done this way at a higher level (you can see user guides in the PlanetScale documentation, for example, the AWS RDS migration guide):
Take a consistent non-locking snapshot of the data which includes the metadata needed to replicate changes that happen after our snapshot was taken. We will be replicating changes throughout the migration process.
- This is critical as it means that the availability of your database and the applications using it are not affected by the migration process — thus no downtime.
Once the data has been copied to the new system, we continue to replicate changes from the old system to the new system so that the new system is ready for cutover at any point.
- We replicate changes from the old database instance to the PlanetScale database in order to keep our consistent snapshot from step 1 up to date and in sync with the original system — thus no downtime.
Run a
VDiffto verify that all of the data has been correctly copied and that the new system is in sync with the old, identifying any discrepancies that need to be addressed before the cutover.- This is a critical step that ensures nothing went wrong during the migration process and all of the data was copied correctly and the systems are in sync — providing the confidence to move on with the eventual cutover.
At some point between steps 1 and 4, the application starts sending traffic to PlanetScale rather than directly to the old system. PlanetScale then continues to route traffic back to the old system until we're ready to cutover.
This can be done any time before we perform the cutover in step 6. This allows you to test how your application behaves when PlanetScale is its target, and most importantly, it allows the eventual cutover to be fast and transparent as PlanetScale manages the routing — thus no downtime.
Warning
You will typically want to take this step as you get closer to the potential cutover point. That is because at this pre-cutover stage your query route is Application->PlanetScale->OldDB with the query response following that same path in reverse. This will incur a significant performance cost — all the more so if the application was previously connecting to the original database using a fast local connection (unix domain socket, loopback device, etc). It's for this same reason that you should not attempt to do application side performance comparisions using PlanetScale, comparing it to the usage of your original database, until you've done the cutover. This is because in this temporary pre-cutover stage the bulk of the total execution time will be spent in network round trips for well optimized queries.
Please note, however, that when using PlanetScale Managed — as most customers at this scale would be doing — the additional network cost would be minimal as the application and PlanetScale database would typically be in the same cloud vendor account and sharing the same physical locations (regions and availability zones) and physical networks in those locations.
You can remain in this state as long as necessary for you to prepare for the application cutover and perform additional testing of the application and database system.
Transparently cutover application traffic to the new system so that application traffic is going to PlanetScale.
- During this process we ensure that there is no data loss or drift.
- Incoming queries are paused/buffered while performing the system changes for the traffic switch.
- Once the cutover is complete — which would typically take less than 1 second — the paused/buffered queries are executed and the system is back to normal operation.
- Reverse replication is put in place so that if for any reason we need to revert the cutover, we can do so without data loss or downtime (this can be done back and forth as many times as necessary).
The query buffering done here is the last part that allows the entire migration to be done without any downtime.
Whenever you are confident in the system and no longer require the need to cut traffic back over to your old system, you can finish or complete the migration.
- This is the final step in the migration process and is the point at which you can decommission your old system whenever you like.
At no point during this process is the old system down or are application users aware that anything out of the ordinary is occurring. The only thing one would typically notice is the slight spike in query latency at the point of cutover where we briefly pause the incoming queries so that we can route them to the correct side of the migration (old vs new) once the cutover work is done.
Note
When you've reached a certain scale — where a database is larger than 250GiB being the recommendation in Vitess — horizontally sharding your database is the best way to continue scaling without incurring exponentially more expensive hardware related costs and affecting the performance of queries and various operations (e.g. schema changes and backups). This is a key feature of Vitess and PlanetScale and it is typical to shard a database as part of the data migration. So e.g. you can have an unsharded MySQL database that we then split into N shards as part of the data migration into PlanetScale. In fact, being able to do this is a common reason for migrating to PlanetScale in the first place.
A deep dive into the technical details
PlanetScale is a database-as-a-service offering a "modern MySQL" developer experience, built around Vitess. Vitess offers a suite of related tools and primitives related to data migrations called VReplication.
The PlanetScale feature built around that set of Vitess primitives for imports is called (not surprisingly) Database Imports. This feature provides the web and CLI based user interfaces around VReplication's MoveTables workflow for the consistent data copy (streaming rows) and the replication (streaming binary log events).
If we walk through the process of a data migration at PlanetScale again at a lower level (the steps are somewhat simplified here with certain details and optional behaviors left out, but it covers the main points):
Copy the existing data by taking a consistent non-locking snapshot of the data which includes the metadata needed to replicate changes that happen after our snapshot was taken — which we will be doing throughout the migration process.
a. Each of the N shards in the PlanetScale database cluster has a
PRIMARYtablet. Those connect to the unmanaged tablet that is placed in front of the external MySQL instance (the old system) and initiates a stream where we issue aLOCK TABLE <tbl> READquery to make it read-only just long enough to issueSTART TRANSACTION WITH CONSISTENT SNAPSHOTand read the@@global.GTID_EXECUTEDvalue, then releasing the lock. At this point we have a consistent snapshot of the table data and theGTIDset or "position" metadata to go along with it so that we can replicate changes to the table that have occurred since our snapshot was taken.b. We then start reading all of the rows from our snapshot — at a logical point in time — ordering the results by the
PRIMARY KEY(PK) columns in the table (if there are none then we will use the best PK equivalent, meaning non-null unique key) so that we can read from the clustered index immediately as we are then reading the records in order and do not need to formulate the entire result set and order it with afilesortbefore we can start streaming rows. The source tablet then has N streams, where each stream is going to a target shard'sPRIMARYtablet, and each stream filters out any rows from our query results that are not going to the stream's target shard based on the sharding scheme defined for the table. The applicable rows are then sent to the target shard'sPRIMARYtablet where they are inserted into the table and metadata for the stream is updated there (in the sidecar database'svreplicationandcopy_statetables) so that we can continue where we left off when the copy is interrupted for any reason.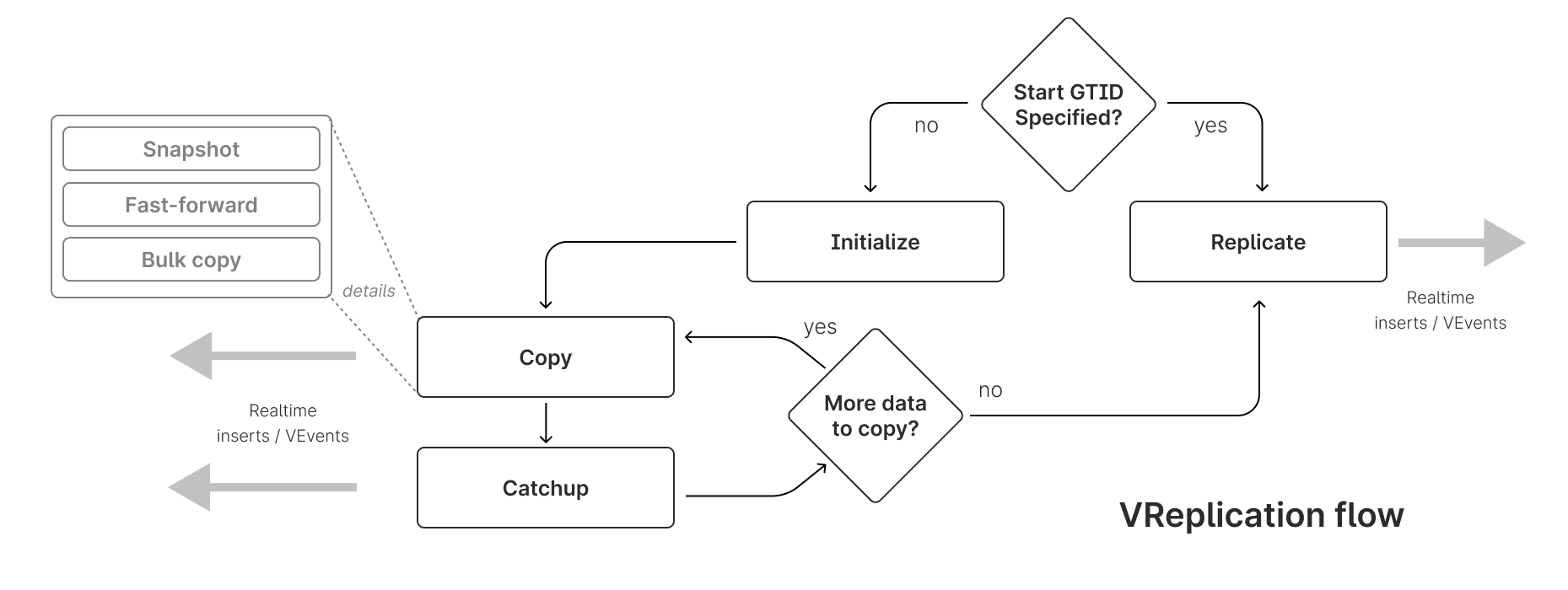
The streams continue to copy rows until we've completed copying all of the rows in our snapshot or we hit the configured copy phase cycle duration (see Life of a Stream for more details) — in which case we will pause the row copy work and catch up on all of the changes that have happened to the rows we've copied so far by streaming the applicable binary log events. The binlog events are filtered in each stream by the destination shard and whether or not the change is applicable to a row we've copied as otherwise we'll get a later version of the row in a subsequent copy phase cycle. This regular catchup step is important to ensure that we don't complete the row copy only to then be unable to replicate from where we left off because the source MySQL instance no longer has binary log events that we need as they have been purged — in which case we would be forced to start the entire migration over again. This also happens to improve the performance of the overall operation as we are replicating the minimal events needed to ensure eventual consistency.
c. We do this table by table (serially), across all of the streams (the streams running concurrently), until we're done copying the initial table data.
Note
As you can imagine, executing all of this work on your current live database instance can be somewhat heavy or expensive and potentially interfere with your live application traffic and its overall performance (and there is that brief window in step a where we take a read-only table level lock to get a
GTIDset/position to go along with the consistent snapshot of the table). It's for this reason that we recommend you setup a standard MySQL replica — if you don't already have one — and use that as the source MySQL instance for the migration. This is another key factor that ensures we not only avoid downtime, but we avoid any impact whatsoever on the live production system that is currently serving your application data.Once the data has been copied to the new system, we continue to replicate changes from the old database instance to the PlanetScale database so that we are ready for the cutover at any point.
Again, there is a stream from the source (MySQL and unmanaged tablet pair) to each target shard's
PRIMARYtablet. For each stream, the tablet on the source will connect to the external MySQL instance and initiate aCOM_BINLOG_DUMP_GTIDprotocol command, providing theGTIDexecuted snapshot that the migration/workflow has which corresponds to where we were when the copy phase completed (see Life of a Stream for more details). Each replication stream then continues to filter those binlog events based on the sharding scheme and forward them to the target shard'sPRIMARYtablet where the changes are applied and persistent metadata is stored (in the sidecar database'svreplicationtable) to record the associatedGTIDset/position so that no matter what happens, we can restart our work and pick up where we left off. We continue to do this until we're ready to cutover.Run a
VDiffto verify that all of the data has been correctly copied and that the new system is in sync with the old, identifying any discrepancies that need to be addressed before the cutover (see Introducing VDiff V2 for more details) — also done without incurring any downtime.Note
Each table in the workflow is diffed serially before the
VDiffis complete. So all steps below are done for each table in the workflow.a. We first get a named lock on the workflow in the target keyspace — in the topology server — to prevent any concurrent changes to the workflow while we are initializing the
VDiffas we will be manipulating the workflow to stop it, update it, and then restart it. Once we have the named lock on the workflow we stop the workflow for the table diff initialization done in steps a through e.b. We then connect to the source (MySQL and unmanaged tablet pair) and initiate a consistent snapshot there to use for the comparision in the same way that we did in step 1a for the data copy. At this point we have the snapshot we need on the source side.
c. We then use the
GTIDposition/snapshot from step b to start the stream on each targetPRIMARYtablet until it has reached that given position and then it stops (this is the same thing a standard MySQL instance does forSTART REPLICA UNTIL). On each target shard we then setup a consistent snapshot just as we did on the source side. Now we have a consistent snapshot of the table on the source instance and each target shard that we can use for the data comparison.d. Now we restart the VReplication workflow so that it can continue replicating changes from the source instance to the target shards.
e. At this point, we are done manipulating the workflow for the table diff, and we release the named lock on the workflow in the target keyspace taken in step a.
f. We then execute a full table scan on the source instance and all target shards, comparing the streamed results as we go along, noting any discrepancies as they are encountered (a row missing on either side or a row with different values) — the state of the diff being persisted in the sidecar database's
VDifftables on each target shard.You can follow the progress as it goes, which includes an ETA, and when it's done you can see a detailed report which notes if any discrepancies were found and providing details on what those differences were — allowing you to address them before the cutover (see the
VDiff showcommand).Note
The
VDiffwill chooseREPLICAtablets by default on the source and target, for the data streaming (the work is still orchestrated by and the state still stored on the targetPRIMARYtablets), to prevent any impact on the live production system. TheVDiffis also fault-tolerant — it will automatically pick up where it left off if any error is encountered — and it can be done in an incremental fashion so that if e.g. you are in the pre-cutover state for many weeks or even months, you can run an initialVDiff, and then resume that one as you get closer to the cutover point.While it is not required that this step is taken, it is highly recommended that at least one
VDiffis run before the cutover to ensure that the data has been copied correctly and that the new system is in sync with the old.At some point between steps 1 and 4, the application starts sending traffic to PlanetScale rather than directly to their old system. PlanetScale then continues to route traffic back to the old system until we're ready to cutover.
- Schema routing rules are put in place so that during the migration, queries against the tables being migrated will be routed to the correct destination — the external MySQL instance (old system) or the PlanetScale database (new system) depending on where we are in the migration process. When the migration starts, these rules ensure that all queries are sent to the source keyspace (old system) and they are updated accordingly when traffic is cutover along with if and when the cutover is reversed.
You can remain in this state as long as necessary as you prepare for the application cutover and perform additional testing of the application and database system.
Transparently cutover application traffic to the new system as application traffic is going through PlanetScale and PlanetScale will now route traffic to the new internal system rather than the old external one.
a. Under the hood, the
MoveTables SwitchTrafficcommand is executed for the migration workflow.b. It will first do some pre-checks to ensure that the traffic switch should succeed, such as checking the overall health of the tablets involved, the replication lag for the workflow (as the workflow has to fully catch up with the source before we can do the traffic switch and there's a timeout for that since this should be a brief period of time as the queries are being buffered), and other necessary state across the cluster. If everything looks good then we will proceed with the actual traffic switch.
c. We ensure that there are viable
PRIMARYtablets in the source keyspace necessary to setup the reverse VReplication workflow which we will put in place when the traffic switch is complete so that the old system continues to stay in sync with the new and we can cut the traffic back over to the old system if needed for any reason. This offers even more flexibility and confidence as if any unexpected errors or performance issues occur (keep in mind that you may be going from one MySQL, or even MariaDB, version to another and from an unsharded database to a sharded one) then you can quickly revert the cutover and investigate the issue. Then once the issues are addressed you can attempt to cut the traffic back over to the new system again — without the pressure of the system being down or needing to complete the final cutover by any particular time.d. We take a lock on the source and target keyspace in the topology server to prevent concurrent changes to these keyspaces in the cluster, along with a named lock on the workflow in the target keyspace to prevent concurrent changes to the workflow itself.
e. We stop writes on the source keyspace and begin buffering the incoming queries (see VTGate Buffering for more details) so that they can be executed on the target keyspace once the traffic switch is complete.
f. We wait for replication in the workflow to fully catch up so that the target keyspace has every write performed against the source and nothing is lost.
g. We create a reverse VReplication workflow that will replicate changes from the target keyspace (new system) back to the source keyspace (old system). This is the workflow that ensures that the old system is kept in sync with writes to the new system in case we need to revert the cutover for any reason (using the
MoveTables ReverseTrafficcommand).h. We initialize any Vitess Sequences that are being used in the target keyspace. This is done to seamlessly replace
auto_incrementusage, when the tables are being sharded as part of the migration, to provide the same functionality of auto generating incrementing unique values in a sharded environment.i. We allow writes to the target keyspace.
j. We update the schema routing rules so that any queries against the tables being migrated will now be routed to the target keyspace (new system).
k. We start the reverse VReplication workflow created in step g.
l. We mark the original VReplication workflow as
Frozenso that it is hidden and cannot be manipulated but we retain that information and state.m. We release the keyspace and named locks taken in step a.
Note
You can remain in this state for as long as you like. It's only when you are 100% confident in the migration and no longer need the option of cutting traffic back over to the old system that you can proceed to complete the migration, which uses the
MoveTables completecommand, to clean up the workflow and all of its migration related artifacts that were put in place (such as the routing rules).See How Traffic Is Switched for additional details.
Note
All of this work is done in a fault-tolerant way. This means that anything can fail throughout this process and the system will be able to recover and continue where it left off. This is critical for data imports at a certain scale where things can take many hours, days, or even weeks to complete and the likelihood of encountering some type of error — even an ephemeral network or connection related error across the fleet of processes involved in the migration — becomes increasingly likely.
Conclusion
Data migrations are a critical part of the lifecycle of any database system. They are sometimes necessary for upgrading to new versions of your existing database system, sharding your existing database system, or moving to an entirely new database system. You've likely been involved in past migrations that have caused downtime or other issues and may be thinking about the next migration you need to do and how you can avoid those issues.
In walking through how we perform data migrations at PlanetScale we hope that you can see ways to improve your own data migrations and avoid various pitfalls and issues that can lead to undesirable outcomes. We're happy to help you with your next data migration — directly as a customer through our work, or indirectly as a member of our shared database community through the sharing of information and practices as we've done here.
Happy migrations!