Since PlanetScale Metal is now generally available, I wanted to share a post describing our experience migrating the PlanetScale database that powers the Query Insights feature to Metal.
Data collection in Query Insights
First, a bit about how we collect the data for Query Insights. The basic steps are:
- Collect query-pattern telemetry from the Vitess layer of your PlanetScale database
- Publish the data to Kafka
- Consume the data from Kafka and write to several MySQL tables, aggregated by time.
The primary scalability concern in the Query Insights pipeline is ensuring that we can process and write data to the database quickly enough to keep up with the inbound volume. To accomplish this, we read Kafka messages in batches, coalesce data in memory to avoid unnecessary writes, and hand the writes off to a thread pool in each Kafka consumer.
Pre-Metal: Write-heavy with provisioned IOPS
The result is that the Query Insights database is very write-heavy. As of this writing, we execute approximately 10k UPDATE/INSERT statements per second. These writes come from 32 consumer processes, each with 25 writer threads for a total max concurrency of 800 threads.
The Query Insights PlanetScale database has 8 shards and, prior to our upgrade to Metal, we'd had to provision more IOPS to the EBS volumes backing MySQL in our sharded keyspace to keep up with the telemetry volume. Since this workload had demonstrated a sensitivity to I/O latency, we figured it would be a good candidate for upgrading to Metal.
Performance improvements after migrating to Metal
To do this, we picked 1 of our 8 MySQL shards, the busiest one, to upgrade first.
The following graphs show the query latency at various percentiles. The lines shows the latency for the 8 primaries of the Insights database. The purple line corresponds to our busiest shard, which was upgraded to Metal around 19:35.
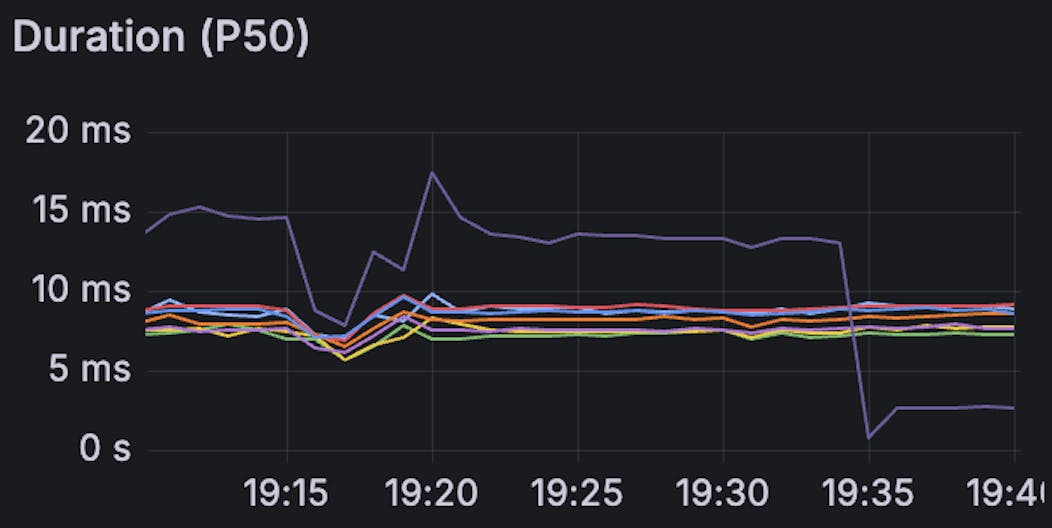
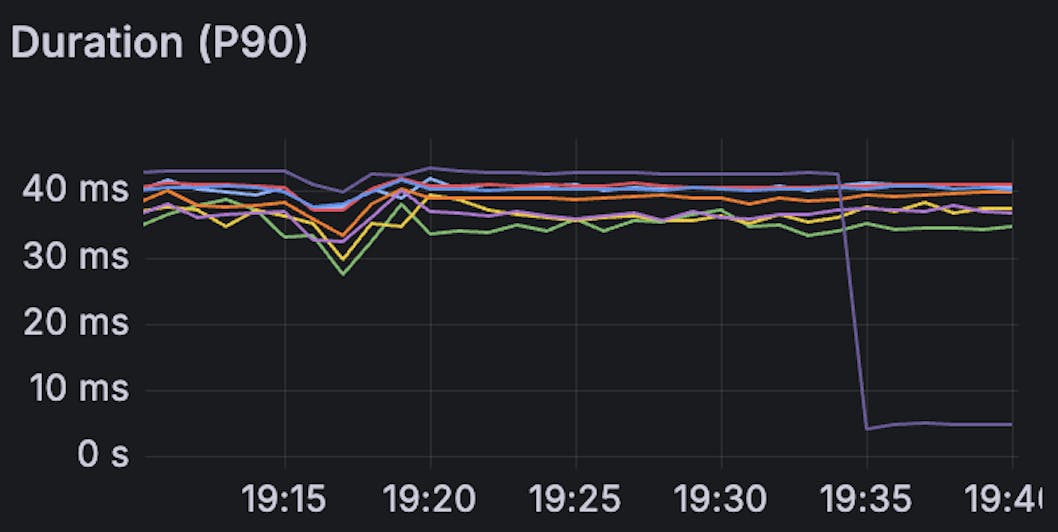
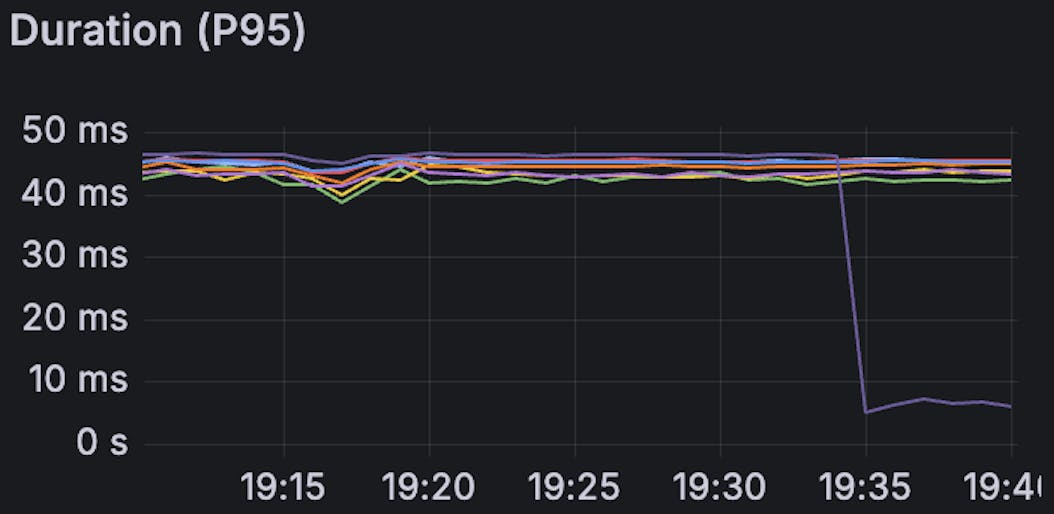
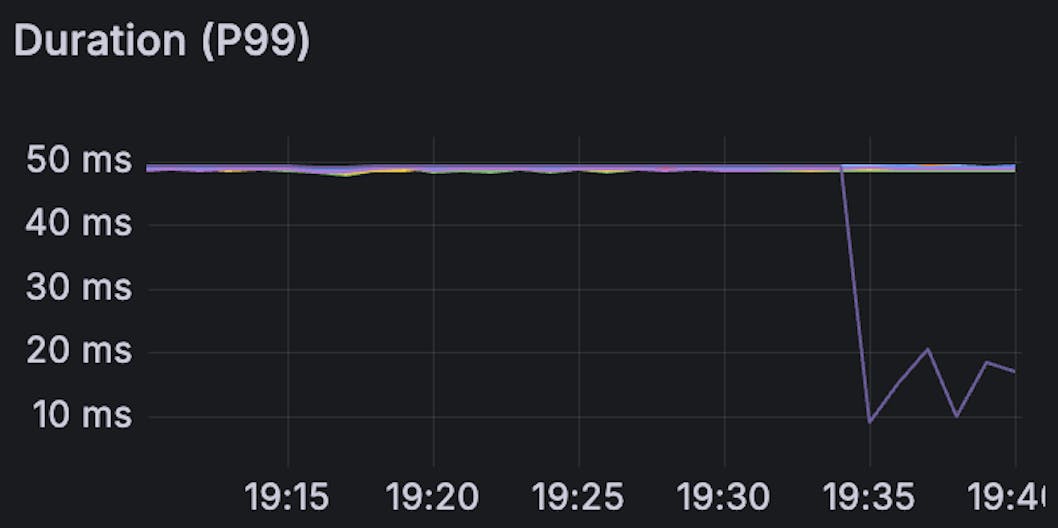
Upgrading a test shard to Metal causes a substantial decrease in latency across all the measured percentiles. After the Metal upgrade, our busiest shard with the highest latencies started executing queries faster than the other shards by a significant margin.
After letting the first upgrade soak for a few days, we upgraded the remaining shards and saw nearly identical improvement in performance.
Without making any changes to our application, architecture, or sharding configuration, we were able to realize substantial performance improvements by upgrading to PlanetScale Metal. This resulted in a lower average backlog in our Kafka consumers, and has given us additional capacity to handle increasing message volume in the future.