In the past, sharding was often a last resort for scaling a growing a database. With solutions like Vitess and PlanetScale, it's much less intimidating to shard your database. However, even with our in-dashboard sharding options, it's still not exactly as simple as clicking a button.
When it's time to shard, you'll still have to come up with a sharding strategy — the procedure the database uses to distribute incoming data across shards. There's a lot that goes into this, and which we'll cover in a short series of posts.
In this article, we'll start by covering some of the different types of sharding you can do: directory or lookup-based, range-based, and hash-based.
Note
For a condensed overview of sharding strategies, you should also check out the Sharding Strategies lesson in our Database Scaling course.
Directory-based sharding
With directory-based sharding, also known as lookup-based sharding, you map your shards with something called a lookup table.
For example, if you want to shard a table based on region so that all rows in a certain region end up on the same shard, you can set up a lookup table that maps that region to the specific shard.
Let’s say we have this members table here that has name and court columns. In this example, court is essentially the region that the member is from. We want to split them up by court, so we create a lookup table that maps each court to a shard.
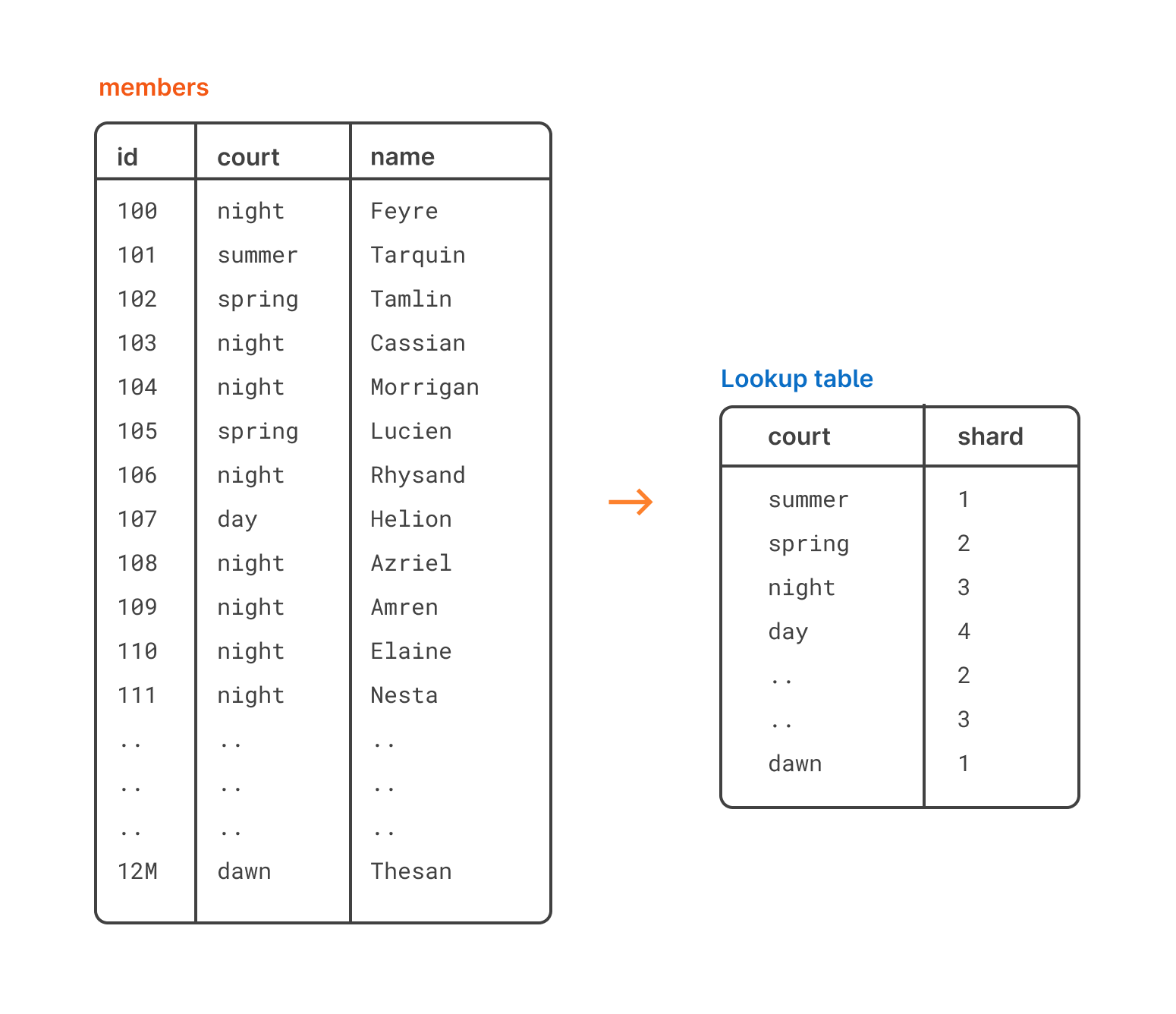
In this case, we’re using the court column as our shard key. The shard key is the chosen column that will be used as the basis for sharding the table.
After sharding using this technique, the data will be distributed like this:
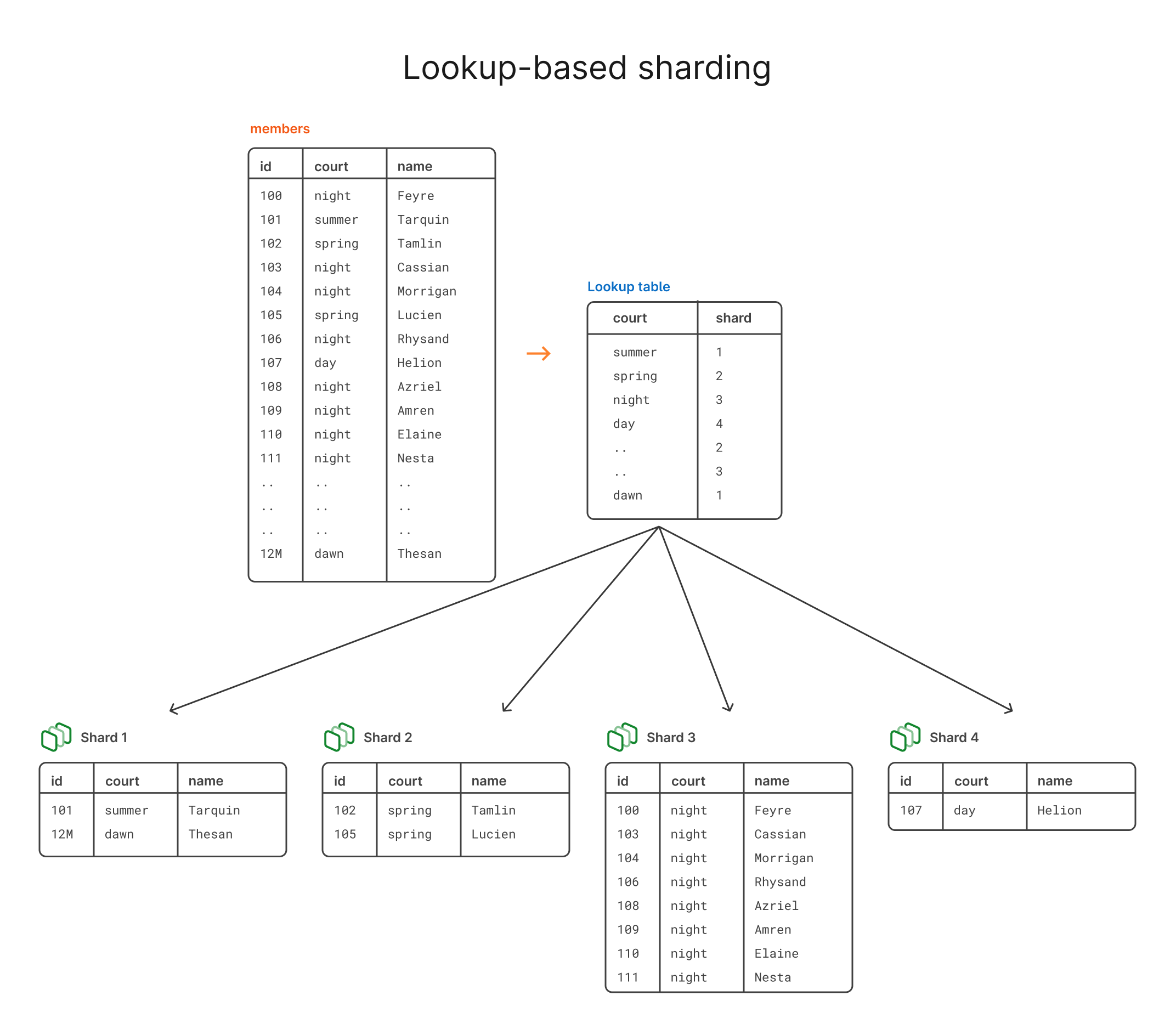
Pros and cons of directory-based sharding
This can be a great option if you have very specific criteria for separating your data onto different shards. It also makes it pretty simple to add new courts, if needed. If we suddenly have 4 new courts join, we can just spin up 4 new shards if the dataset is large enough or if we want to stay on 4 shards, we can assign the new courts to one of the existing shards by throwing them in the lookup table.
There are, however, some downsides to this method. As you can imagine, if one court has significantly more members than another, you risk having one shard that’s much larger than the others. Additionally, if one court has one or several members that are much more active in whatever you’re doing, you can create a hotspot where that shard is being accessed much more frequently than the others. In short, data distribution can become a problem.
You also have the added factor of the lookup table itself, which results in an extra query every time you need to read or write a row. Before you do anything, you have to first consult the lookup table to see where something lives. In practice, you’d want to heavily cache the lookup table to make it faster, but you’ll still have that extra step regardless.
Range-based sharding
Range-based sharding is another type of sharding strategy that involves splitting up your shard mapping based on a range of values. This is a silly example, but let's say we wanted to shard based on the name column in that members table — so using name as the shard key.
We want any name where the first letter starts with A-G to go to shard 1, H-N to go to shard 2, and so on.
With this sharding strategy, the rows of the table would be distributed like this:
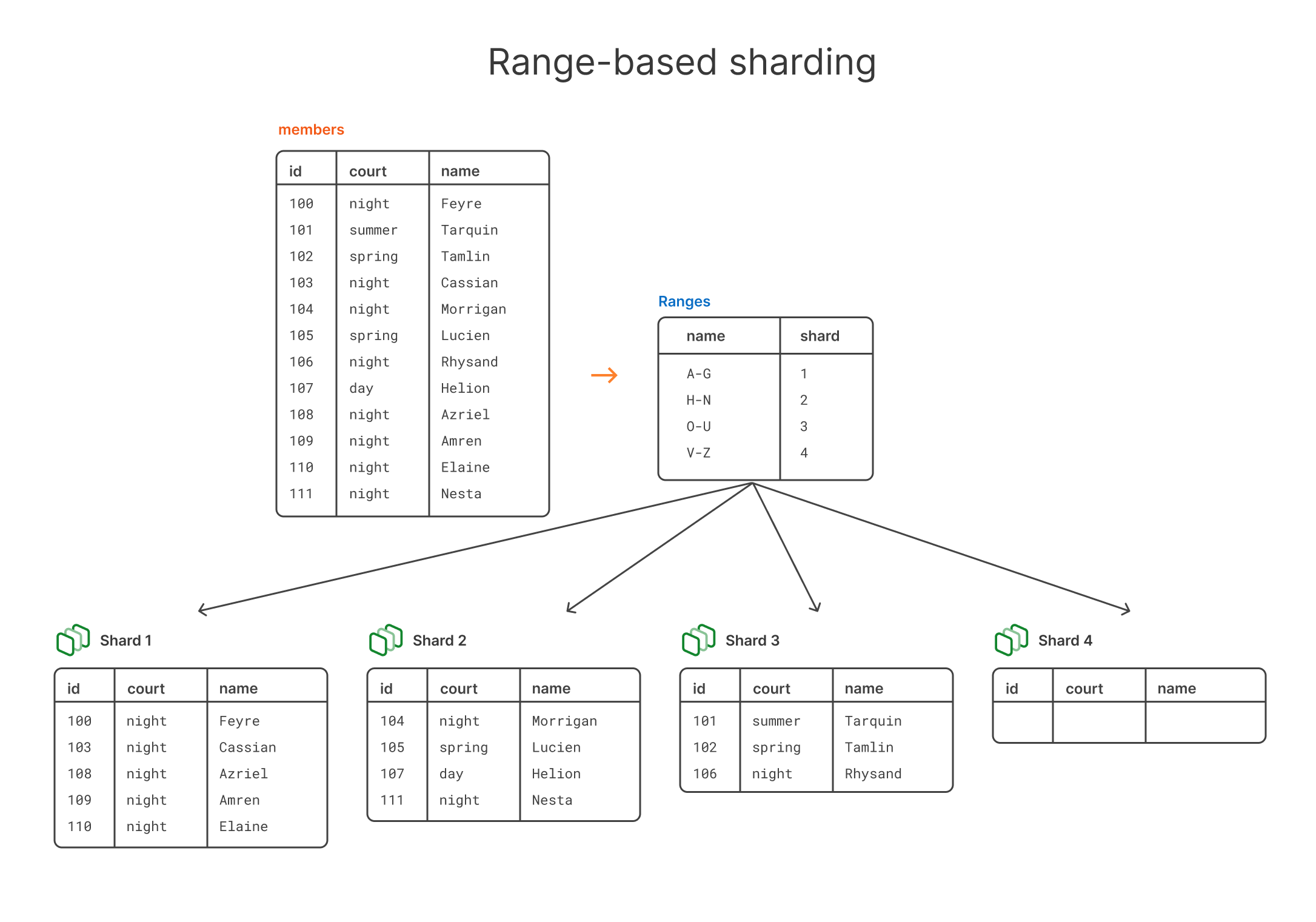
Pros and cons of range-based sharding
The problem with this setup should be immediately clear. Depending on how you’re picking these ranges, you can easily overload shards. In this case, shard 1 has 5 records in it while shard 4 has 0. This is of course because certain letters occur much more frequently as the first letter in a name.
This is one of the downsides of range-based sharding, but there are definitely ways to avoid it. For example, if we started with this method for mapping the ranges, but then quickly noticed that shard 1 was growing much faster than the others, we may decide to break shard 1 up into multiple shards with a reshard operation. We can also make the range for the last shard larger since those letters happen less frequently.
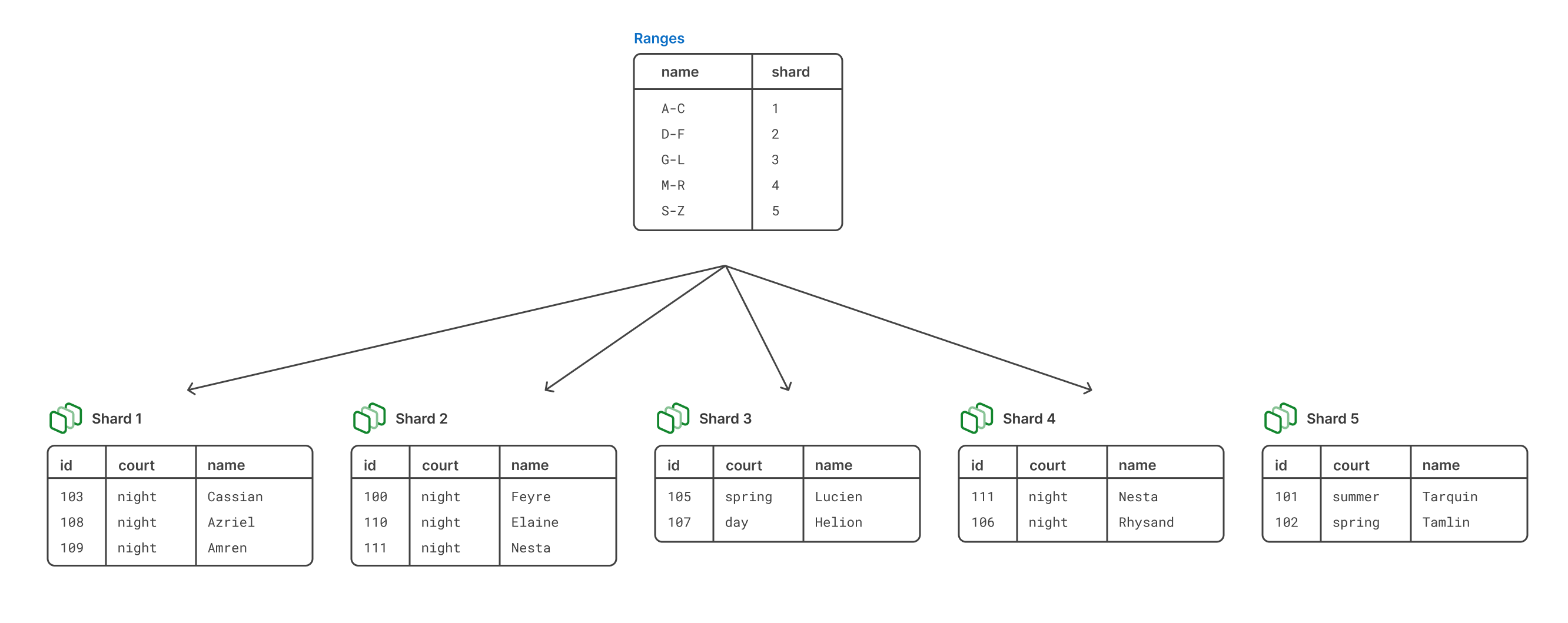
Overall, it’s a relatively simple approach for sharding and gives you a meaningful way to map data to shards.
Hash-based sharding
The final type of sharding we’re going to discuss is hash-based sharding. With this method, you decide which shard key you want to use, then run that value through a hash function. You then shard based on the output of the hash function.
It’s similar in a way to range-based sharding, but this time, we’re using an alphanumeric range instead of say letter-based in the previous example.
For this example, let’s say we have an id for each court member in our members table, and we want to use this id as our shard key. We’re going to run that id through an md5 hash function, and then distribute the output across 4 shards.
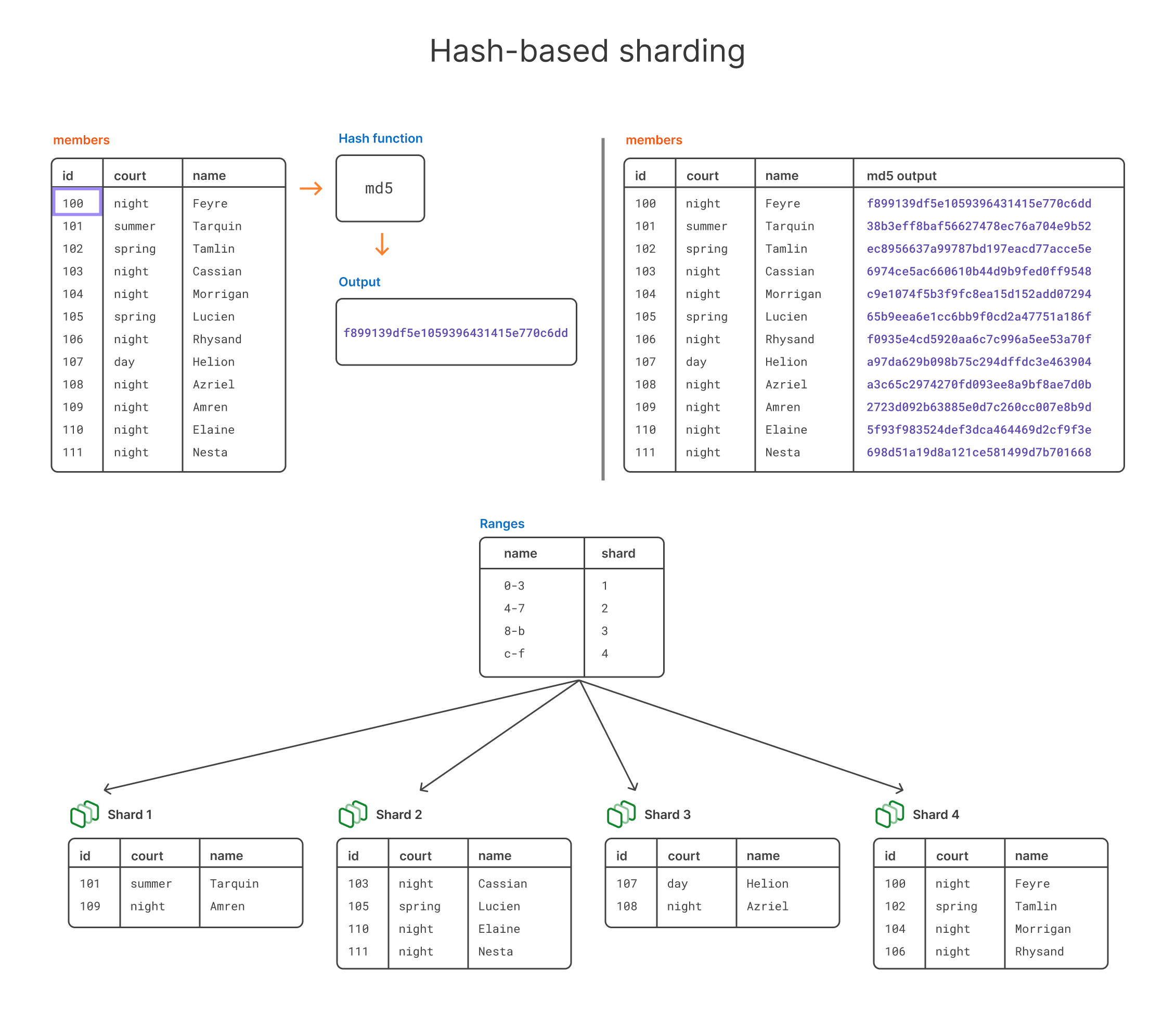
Pros and cons of hash-based sharding
One of the pros of this method are that you’re taking human guesswork out of the equation. Rather than relying on a human to guess at how much data will fall into each range, the hash will keep the data evenly distributed, so long as the shard key has high cardinality. There’s less chance of overloading a shard because you’re distributing the data based on a well-proven hash function. However, you still have to put some thought into what shard key you choose here, as you want it to work well with the data access patterns of your application.
With this method, it’s also a bit easier to reshard if you find that certain shards are taking more of a hit than others. The main downside is having the extra hashing step, but in practice, this isn't usually a huge deal.
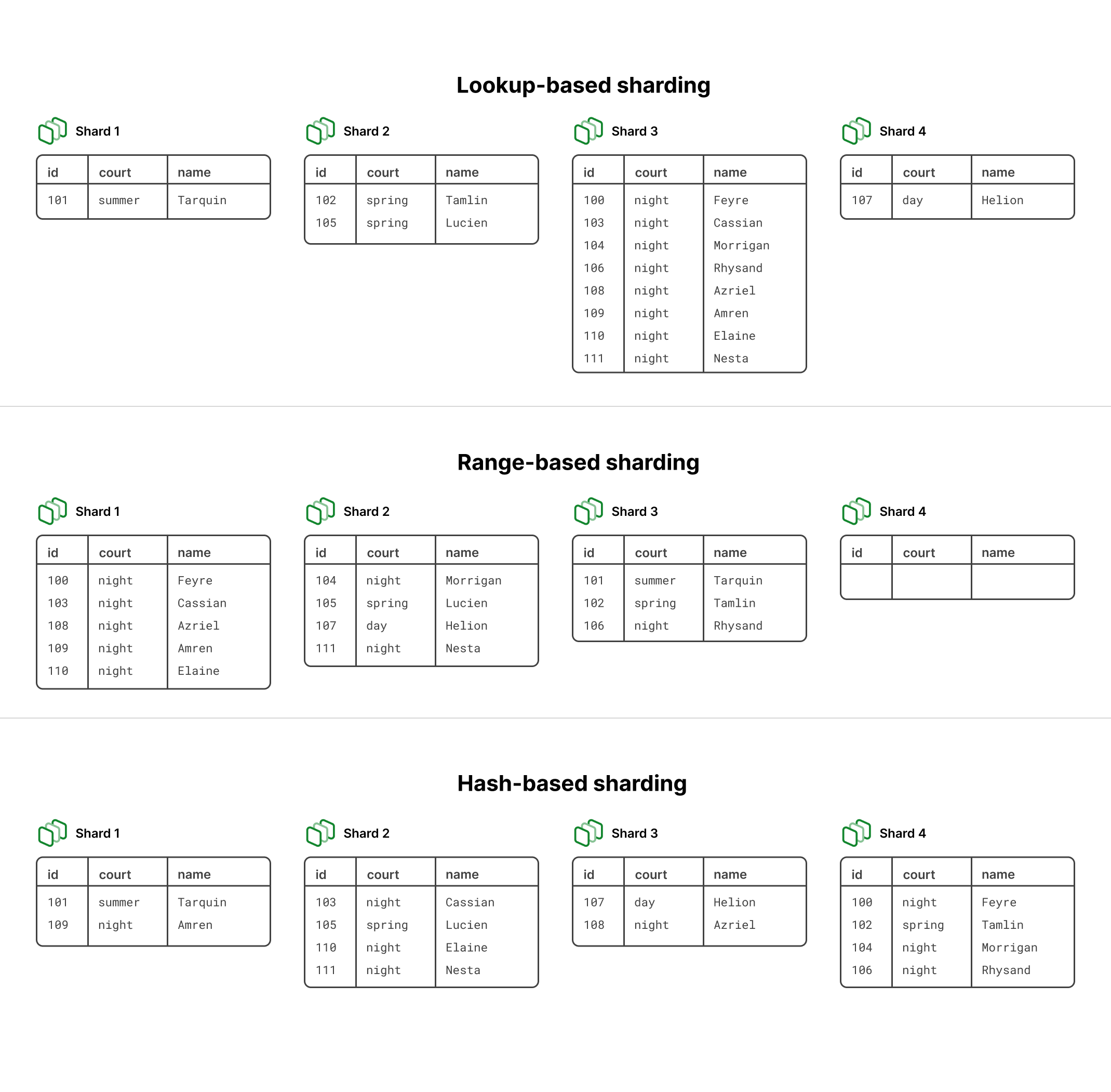
Comparison of sharding types
You may be wondering how you can decide which type of sharding to go with. At PlanetScale, we typically steer customers toward hash-based sharding as the default. It generally gives you the most even distribution and isn't overly complicated.
The diagram below shows what the distribution looked like in our small example. In this case, hash-based sharding resulted in the most even distribution. Of course, this is a tiny example and not a realistic sharding scenario given the size, but in general this holds true in larger datasets as well.
If you have a database that you think is ready to shard and are curious if PlanetScale is the right solution for you, fill out our contact form, and we'll be in touch.