Organizations often shard their database to scale beyond what simply adding resources to a single server can provide.
When you horizontally shard your database, you essentially break the data up and split it across multiple database servers. Hearing this, you might think that adding more servers means adding more maintenance overhead to your staff, and more expenses on your budget, with the tradeoff that your organization can handle more database traffic. While there is definitely some truth to that in certain situations, there’s oftentimes more to the story that's not as obvious.
In this article, we’ll cover three ways that sharding your database can benefit your organization beyond additional throughput.
Minimized impact on failures
There’s an old saying in architecting infrastructure: two is one, and one is none.
The implication is that you should never have one of anything, as it creates a single point of failure. This is true for your database as well, perhaps more so since it is a critical part of your application. In a typical MySQL environment, if the database server goes down, the entire application goes down with it.
In sharded environments, this failure domain is actually spread out.
Consider a scenario where you shard based on ranges of customers using the customer ID.
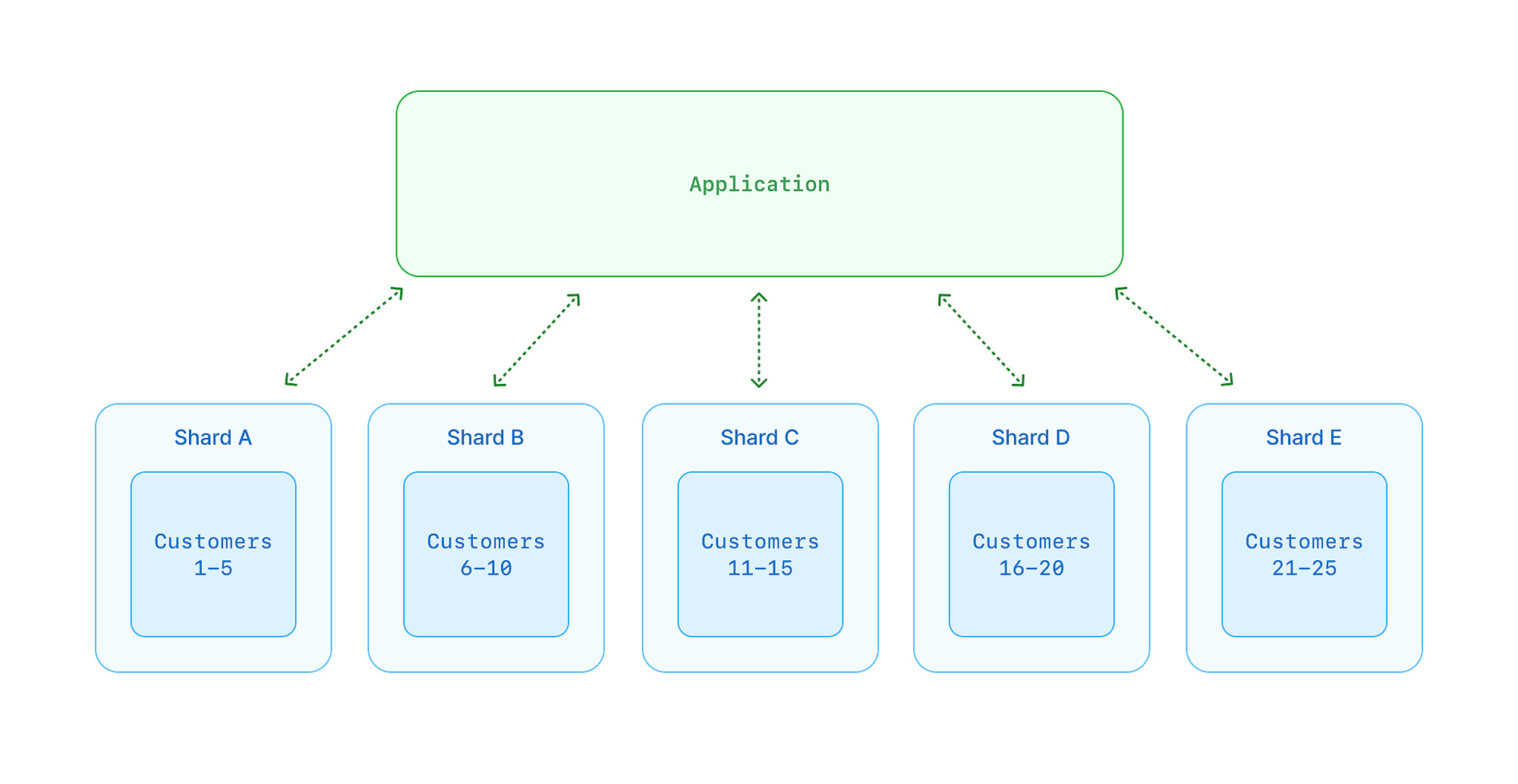
If shard A goes down, it will make a bad day for customers 1-5, but the remaining shards are actually still online and can serve data with no problem. Since the impact of an outage is more isolated, there is less of an impact on various teams across your organization as they work to communicate with customers and recover from the failure.
This does not consider any lost revenue from the outage, which is also minimized.
Maintenance tasks are more efficient
The larger a MySQL environment gets, the harder it gets to manage.
Consider backing up a 1TB database. Not only does the process take a long time, but it can have a significant impact on how fast your database responds to queries. Now let's take that same database and create a sharded environment where the data is evenly split across five shards, similar to the previous example.
Not only is backing up 5× 200 GB databases quicker, but if you ever have to restore data from those databases, that process will be faster as well.
Backups are just one example of how sharding makes database management easier.
Schema migrations are another task that can be performed more efficiently. For example, when you merge in a Deploy Request on PlanetScale, we’ll create a new table on the target database branch with the updated version of the schema and sync data from the live table into this “ghost table”. Once the changes are merged in, the old table is dropped and the “ghost table” becomes the new production table.
Using the same scenario from above, performing this operation on the smaller databases in parallel will dramatically reduce the time it takes to complete.
You might actually save money
I know the thought going through your head right now: “How can sharding save me money if I’m adding more servers?”
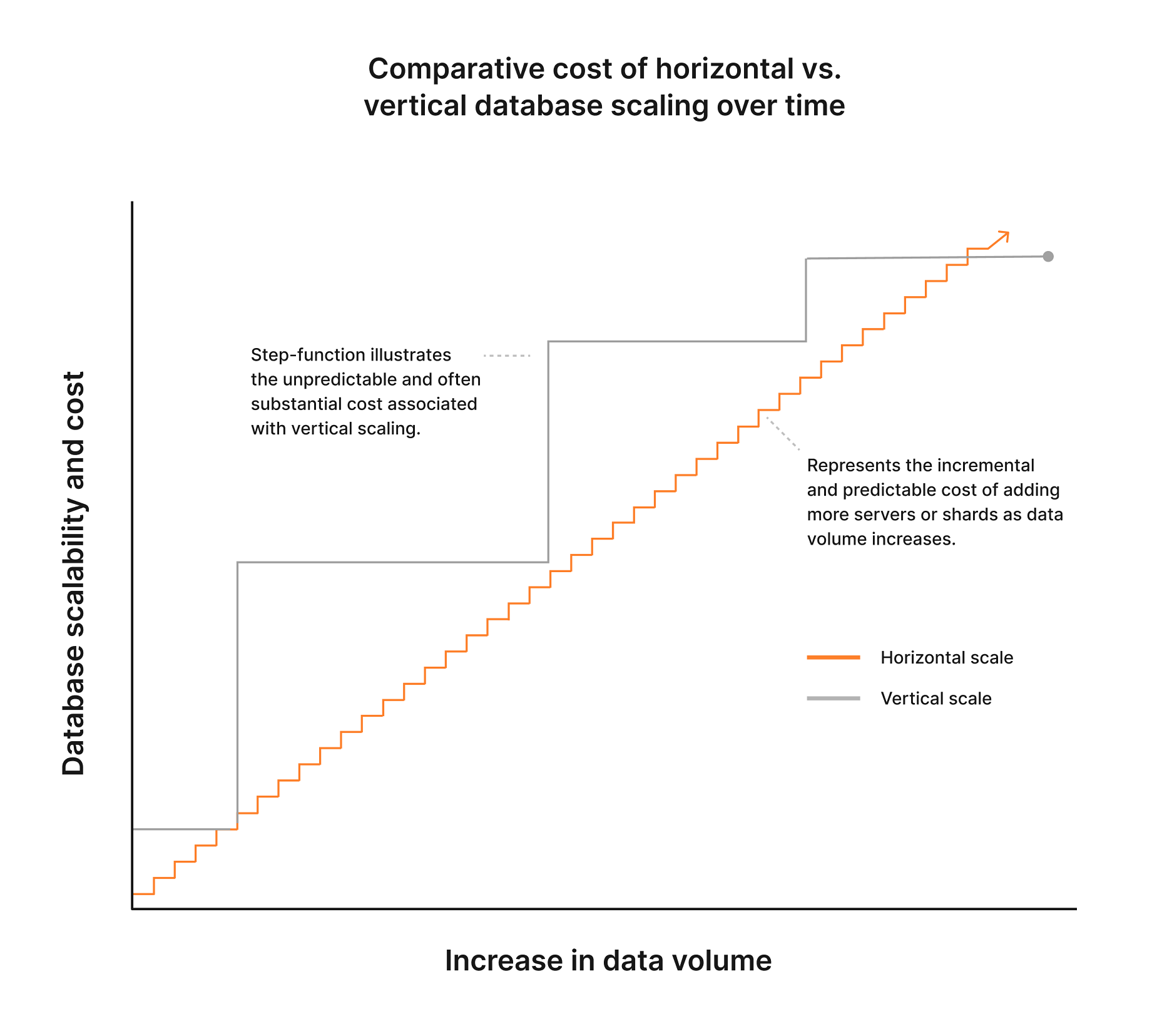
Let’s first consider the vertical scaling approach. When you provision a server, you need enough resources (CPU, memory, IOPS) to run whatever it is you are trying to run, as well as the necessary overhead to accommodate usage spikes. As the application scales, you’ll eventually start reaching the limits of your server and need to bump resources along with even more overhead to support the service.
This cycle continues, resulting in you always paying for more than you actually use.
Now consider a world where you have a database that’s sharded across five servers as shown earlier in this article.
Whenever the load exceeds what the allocated resources can handle, you add another server into the environment with the same specs and rebalance the load across those servers. There may still be some overhead, but it's significantly lower than what's required when scaling vertically. Plus, since you are adding another server with the same specs, the overall cost increases more linearly and predictably, something your finance team will appreciate.
Another way that sharding can save you money is by utilizing commodity disks in cloud infrastructure.
As your database is used more and more, it increases the demand on the underlying storage in the form of more required IOPS. Lower-cost virtual disks often have a set limit to the amount of IOPS granted to them before you have to select a more costly option. This can creep up on cloud architects if it’s not accounted for.
By sharding your database across multiple, lower-cost disks, you can save money by avoiding the additional costs of their more expensive counterparts.
Conclusion
As a database grows, so do many of the struggles that are associated with databases in general, not only data contention. After reading this article, you should now have a better idea of several other key benefits of sharding beyond additional throughput.
If you’ve sharded your database, what other benefits have you found that might not be provided here? Share it on X and tag us @planetscale!