If you're using MySQL, you likely have indexes that are powered by B-trees. The B-tree is a powerful data structure, and is frequently used to construct indexes in relational databases. If you are using the InnoDB storage engine, it is the only choice for your index, save for spatial indexes. However, MySQL has a secret weapon for making lookups with these types of indexes even faster: the Adaptive Hash Index, or AHI. Before jumping into how this works, let's take a few moments to review B-trees, the InnoDB buffer pool, and how these work together during index lookups.
B-Tree indexes
The B-tree data structure has been used by computer systems for decades. It is particularly useful in the context of file system and data storage applications, due to the fact that each node can store many values. This is useful in algorithms that interface with storage systems, as the size of each node can be set to work well with the unit(s) of storage, for example aligning with the page size of a hard-drive disk.
As its name suggests, a B-tree is a specific type of tree structure, but differs in several ways, including:
- Each node contains up to N values, rather than just one
- Each node can have up to N+1 children
- All elements are stored in-order for a left-to-right traversal
- All leaf nodes are on the same level of the tree
Let's look at an example B-tree build using first names from a database:
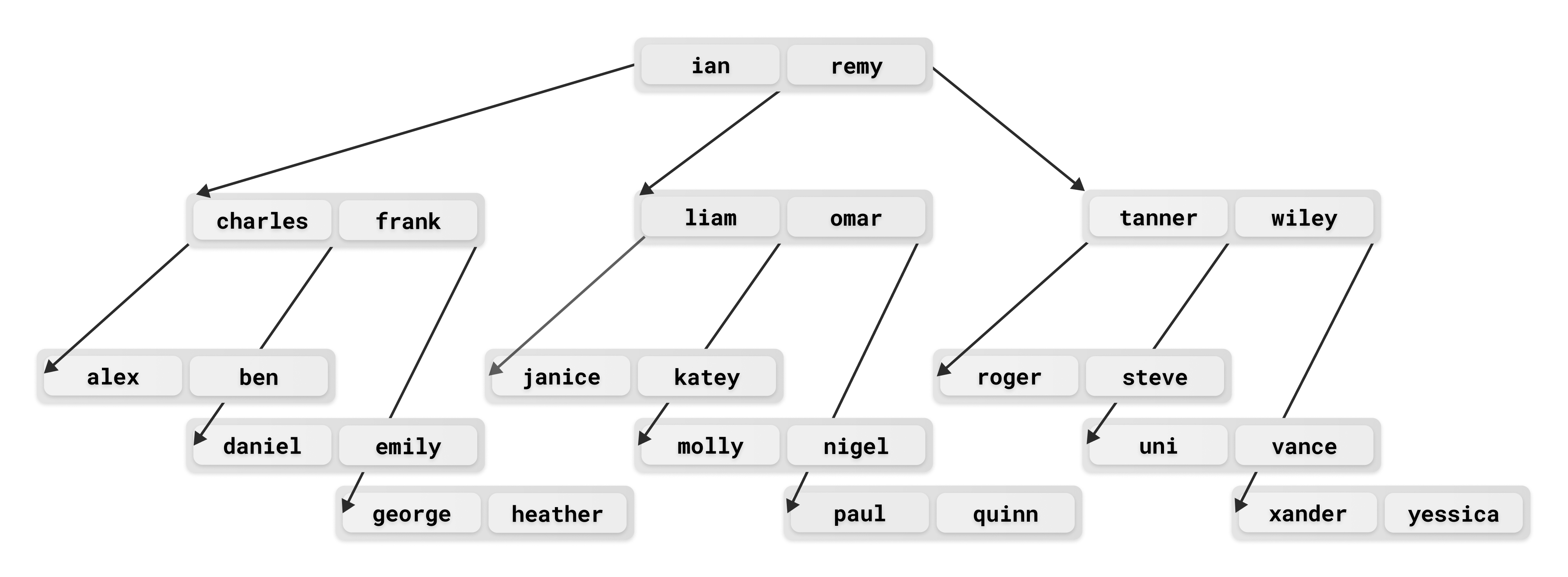
In this example, N = 2, and all of the value slots in all of the nodes are full. For InnoDB B-tree indexes, N is usually much larger, as it is determined by how many values can fit within an InnoDB page (this defaults to 16k). In addition to this, nodes are often left with some buffer of extra space to allow for faster future inserts.
When you create an index on an InnoDB table, MySQL constructs a B-tree containing the values from the indexed column. The child pointer before any given value points to another node containing values that are less than it, and the pointer after contains ones that are greater. Thus, a left-to-right traversal of this structure should visit all of the data elements in order.
In the general case, the size of a B-tree node can be set to whatever the programmer desires. In InnoDB, index nodes are set to match the InnoDB page size. This is pretty large, so each node can potentially store hundreds of values.
Say we want to search for the name paul in this B-tree.
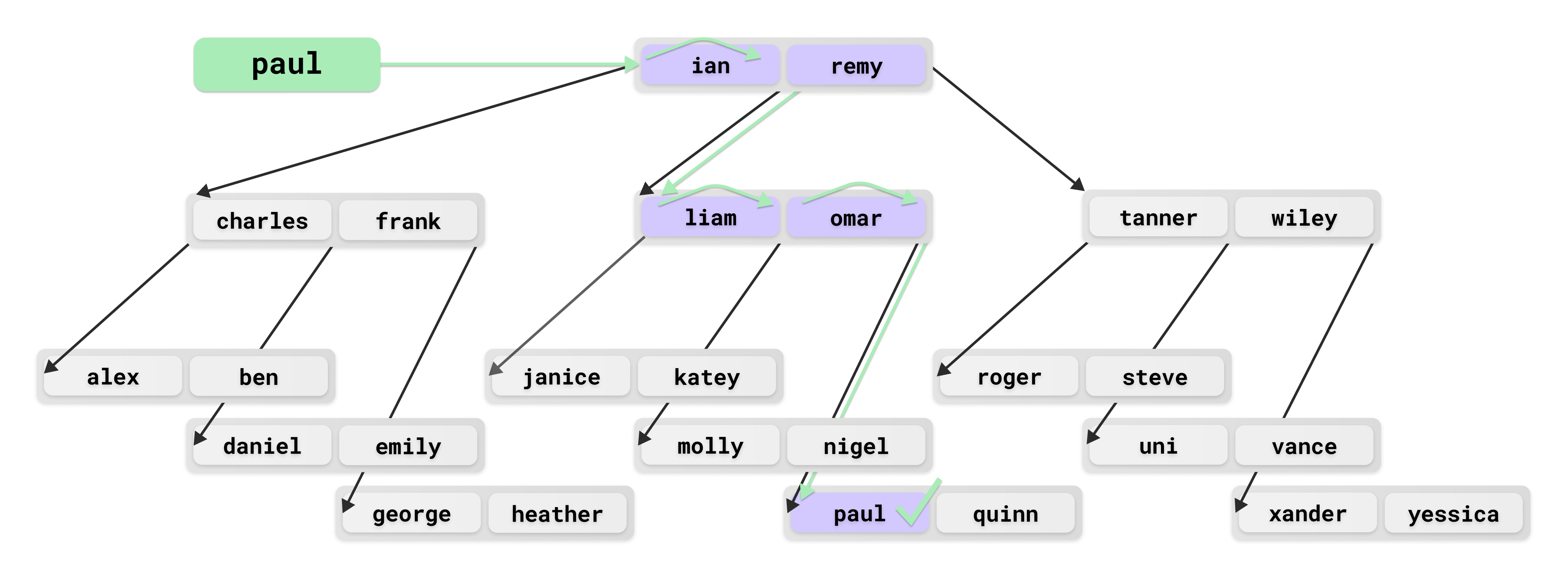
The steps to accomplish this are:
- Compare
paulandian, determineian<paul. - Check and see that
paul<remy, so traverse down middle pointer. - Compare
paulto firstliamand thenomar. It is greater than both, so traverse down third pointer. - Discover
paulas the first element in the leaf node.
Doing this is much faster than a linear scan of all elements would have been. However, a search operation is not quite O(1), as multiple comparisons and page loads are typically needed for a single lookup. With only two values per node and a small data set, the benefit of a B-tree compared to a linear search is less apparent. But the benefits are huge for large data sets. InnoDB B-tree indexes rarely need to go beyond, say, 5 levels, even for tables with millions of rows.
There's lots more that could be said about B-trees. However, the important take-away is that B-trees provide ultra-fast lookups for queries that utilize the index. Yet they are not quite a constant-time operation, and require multiple page reads and comparisons.
The InnoDB buffer pool
When using InnoDB, all of your data, including any and all indexes you have on your columns, are stored in pages on disk. As MySQL executes and fulfills queries, it needs to be able to load subsets of this data into RAM for faster access. In MySQL, the region of memory MySQL use for storing InnoDB data is known as the buffer pool, and its size is configurable using the innodb_buffer_pool_size configuration option. As MySQL runs and reads rows and indexes, it grabs pages (16k by default in InnoDB) from disk and puts them into this region of RAM.
Generally, the larger this pool is, the better the performance of your database will be, up to the point where the pool size = the size of your data set. If the size of the data is larger than the space available in the pool, MySQL will eventually have to evict pages from the buffer pool to make room for new ones to be loaded. MySQL uses a modified Least Recently Used (LRU) algorithm for this.
Due to this structure, when MySQL starts performing B-tree index lookups, initially many pages will have to be loaded from disk, a more costly I/O operation. However, as it processes more and more lookups, many of the these pages may end up residing in the buffer pool, meaning each B-tree node visit and comparison executes faster because it's primarily hitting memory rather than disk. This helps performance, but it still requires looking at multiple pages as the B-tree is used to complete a search.
Hash lookups and performance
Another approach to performing fast lookups on large sets of data is to use hashing. With a hashing approach, we store all of the data (in this case, the first names of our users) in a large table. When performing a lookup for the name paul, we run this through a hash function that generates a repeatable output index. This index can be used to do a direct lookup into the hash table.
In the absence of collisions, a hash table lookup is a O(1) operation. Assuming your hash table data is in memory, this is even faster than a lookup into a B-tree index.
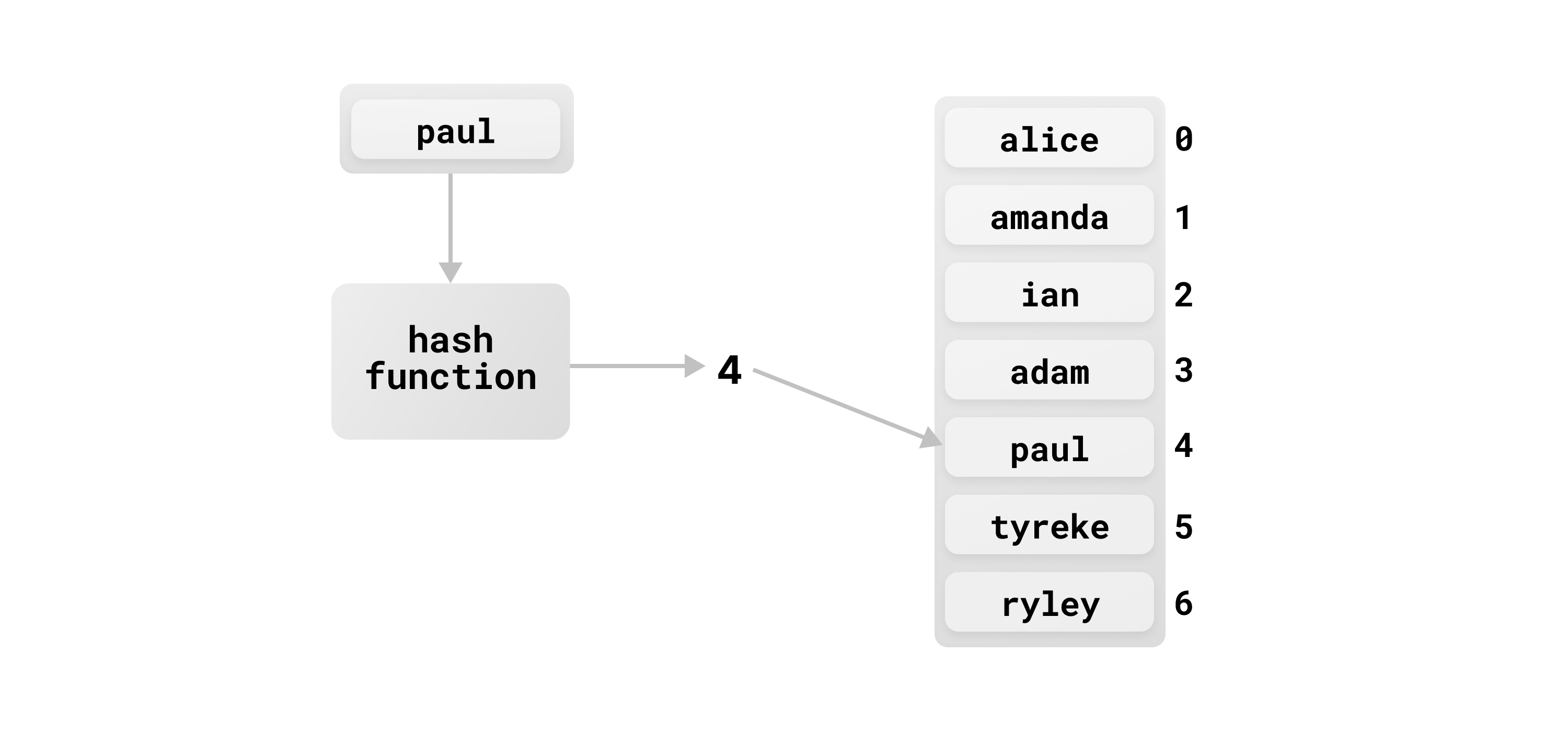
Though MySQL broadly supports both BTREE and HASH indexes, the InnoDB engine actually does not support HASH. If you try to create an index with USING HASH on an InnoDB-powered table, MySQL will instead create a B-tree index.
For instance, doing the following works without error:
mysql> CREATE INDEX alias_index ON user(username) USING HASH;
Query OK, 0 rows affected, 1 warning (0.79 sec)
Records: 0 Duplicates: 0 Warnings: 1
However, the information_schema tells us that it really is a B-tree index that was created:
SELECT table_name, index_name, index_type
FROM information_schema.statistics
WHERE table_schema = 'quiz'
AND table_name = 'user';
+------------+-------------+------------+
| TABLE_NAME | INDEX_NAME | INDEX_TYPE |
+------------+-------------+------------+
| user | alias_index | BTREE |
| user | PRIMARY | BTREE |
+------------+-------------+------------+
2 rows in set (0.00 sec)
It is a bit unfortunate that InnoDB does not support building on-disk, hash based indexes, as this type could be useful and more performant than a B-tree in some instances. However, this lack of support does not mean that hashing is not used at all for index lookups.
The adaptive hash index
Though InnoDB does not support on-disk hash indexes, MySQL has a feature to do in-memory hash lookups for indexing. This is known as the adaptive hash index. This feature can be used to speed up already-fast B-tree lookups, accelerating the performance of the queries that utilize these indexes as a part of their query plan. This acts as a layer that sits between the execution of MySQL and the in-memory buffer pool.
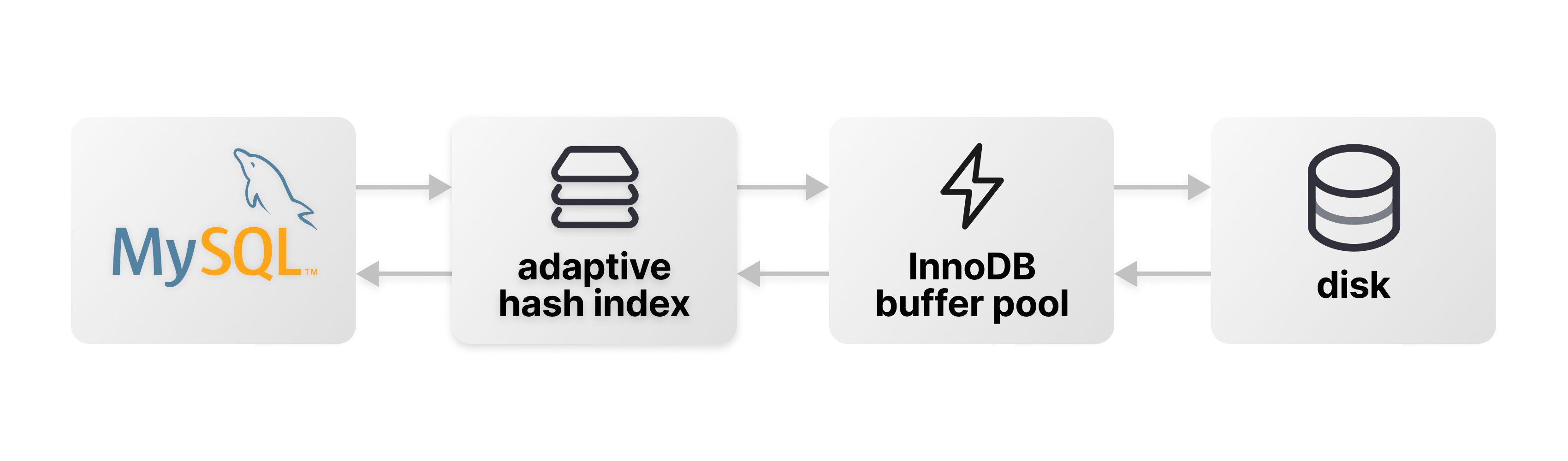
As its name suggests, the adaptive hash index (AHI) is constructed at runtime, and its usage adapts to the characteristics of your workload. If MySQL observes that a particular value is getting repeatedly looked up in a B-tree index, an entry in the AHI can be created either with the full value, or a prefix of the value. For future lookups of this same value (which are likely, since MySQL observed its repeated use) it will use the AHI instead of the B-tree. The keys of the AHI are the values (or value prefixes) of the underlying index. The values are pointers, referring to where the data for this value lives within the InnoDB buffer pool.

The pointers in the adaptive hash index only point to data within the buffer pool. Thus, the buffer pool needs to be sufficiently large for the AHI to kick in. If it is small and there are a lot of evictions taking place, it is not worth using it. Thankfully, MySQL is able to automatically adjust its use of the AHI based on the behavior it observes in the buffer pool. If conditions are not right for its use (few repeated lookups, small buffer pool, etc), MySQL will reduce or eliminate its use.
Though it can speed up queries, there is a bit of overhead to maintaining this special hash index. The feature can be enabled or disabled via the innodb_adaptive_hash_index configuration option. It is typically enabled by default, but if you have a workload that you know will not benefit from it, it can be disabled using innodb_adaptive_hash_index=0 in your configuration file.
Testing performance of the adaptive hash index
Let's run a few tests to see how the adaptive hash index can help a workload. We'll start with something very simple. I'll execute the following query 500k times in two different scenarios: with and without the AHI enabled.
SELECT user_id, username, bio FROM user WHERE username = 'willpeace1';
This is executing against a users table with a little over 390 million rows in it. With it disabled, we get the following timing:
$ python3 same_query.py 500000 1
starting query load
completed in 35.6 seconds
QPS = 14043.57
This goes fast, because I have a B-tree index already set on the username column. While this workload was running, I executed SHOW ENGINE INNODB STATUS \G;. This command provides information about what is going on with the InnoDB storage engine. You can inspect the INSERT BUFFER AND ADAPTIVE HASH INDEX section to see if and how much the adaptive hash index is being used.
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 11826, free list len 13206, seg size 25033, 8599 merges
merged operations:
insert 52823, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 276707, node heap has 0 buffer(s)
...
0.00 hash searches/s, 418334.67 non-hash searches/s
The key line to observe here is the last one, which indicates that no hash lookups are occurring. This is expected, since we have disabled the feature.
Now after enabling the adaptive hash index and restarting the server, let's try again:
$ python3 same_query.py 500000 1
starting query load
completed in 29.94 seconds
QPS = 16701.1
We achieved about a 16% speed up. This is a small, but still quite useful performance boost. B-tree index lookups are already very fast, but we have layered an additional optimization on top to make it even faster. I grabbed information about the buffer pool while this ran, and this shows that the AHI was being used:
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 11445, free list len 13587, seg size 25033, 1881 merges
merged operations:
insert 11507, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 276707, node heap has 3 buffer(s)
...
350953.05 hash searches/s, 50985.01 non-hash searches/s
Now, many hash searches are occurring. There are still some non-hash searches happening as well, which makes sense since the query still needs to access the actual data in the row, not just the index value.
Let's try another workload. This time, we'll re-use the same query, except instead of always searching for the same username, on each execution we'll randomly select one username from a pool of one thousand. Though this specific workload is unrealistic, this can be thought of as a database and workload with a large amount of cold data, and a small amount of hot data.
Without the adaptive hash index disabled, we get:
$ python3 load.py 500000 1
---
starting query workload
completed in 54.16 seconds
QPS = 9231.62
With it enabled, we instead see:
$ python3 load.py 500000 1
---
starting query workload
completed in 43.24 seconds
QPS = 11562.05
In this workload, we got a 20% performance improvement.
These tests were executed on on a table with over 390 million rows:
mysql> SELECT count(*) FROM user;
+-----------+
| count(*) |
+-----------+
| 398748007 |
+-----------+
Even with such a large data set, the B-tree index for the username column was only 4 levels deep (this was checked with the help of innodb_ruby). Running these types of workloads on tables with smaller indexes, and therefore shorter B-tree indexes, may result in less noticeable speedup. On the other hand, workloads using deeper B-tree indexes may see even more performance improvement.
Conclusion
When dealing with large, multi-terabytes databases and workloads with hundreds of thousands of queries per second, even small improvements like this can have a big impact on query latency and database server infrastructure needs. The adaptive hash index provides such improvements for already-fast B-tree index lookups, helping certain types of workloads get a boost in performance. Whether or not the AHI will help your workload depends heavily on data access patterns and the size of your InnoDB buffer pool.