As more services shift towards the cloud, many organizations seek microservices to streamline development, improve reliability, and accelerate feature delivery. Developing and deploying microservices can have a hidden complexity. If you are migrating away from a monolithic service that uses transactions to keep data safe and consistent, how do you translate that to a distributed microservices world?
In this blog, the first of a two-part series, we will introduce you to Temporal and PlanetScale DB and demonstrate the advantages of using these two powerful technologies to manage your workflows reliably and with less effort.
What is Temporal?
As an organization and application scale, monoliths tend to become groups of microservices, and developers have to start thinking about how these separate systems work together. If you're a software developer who began your career in the past seven years, you’ve probably already seen a lot of distributed systems concepts through your daily work. Temporal is an open source, distributed, and scalable workflow orchestration engine capable of concurrently running millions of workflows.
Temporal takes care of many distributed systems patterns for you. It allows you to code at a new, higher level of abstraction, where you don’t have to concern yourself with reimplementing these patterns. With Temporal, you get reliability, fault tolerance, and scalability out of the box, and you can focus on just coding your business logic.
Let’s break this down a little by looking at some definitions:
- Workflows — Workflows hold state and describe which activities or tasks should be carried out.
- Activities — Activities are tasks that might fail. For example, calling a service. They’re automatically retried, and execution is distributed via task queues to a pool of workers.
Essentially with Temporal, failure handling is taken off the hands of application developers and handled by the engine. It provides the illusion of infallible, reliable function executions and will tell our code when to run. Registering workflow implementations and the activity implementations this workflow needs to run is critical.
In the figure below, you will find an illustration of a Temporal Cluster, which consists of four independently scalable services. (Source: Temporal.io)
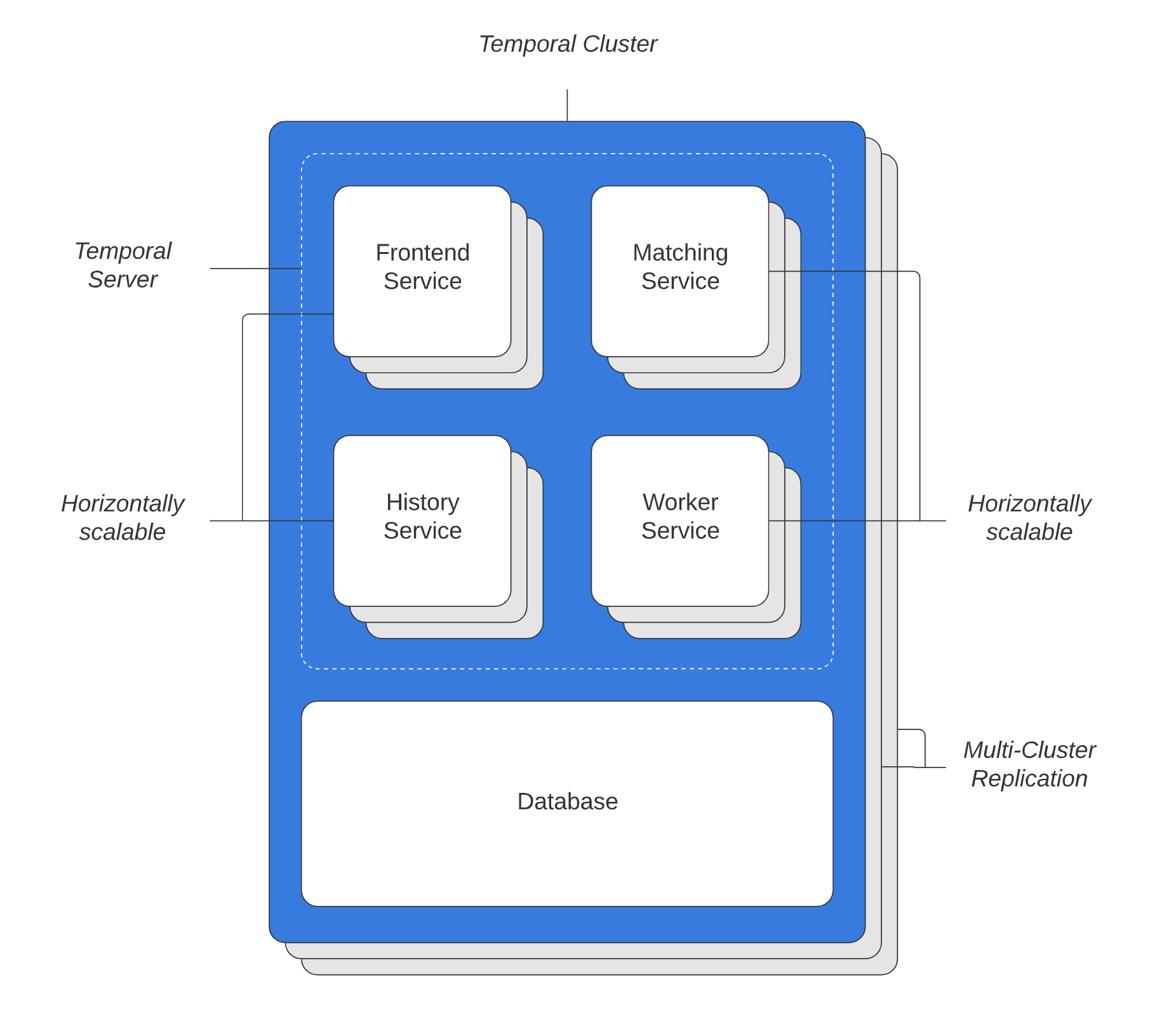
These independently scalable services include:
- Frontend gateway (rate limiting, routing, authorizing)
- History subsystem to maintain data (mutable state and timers)
- Matching subsystem to host task queues for dispatching
- Worker service to handle the internal background workflows
Durability
Temporal captures the progress of a workflow execution (or workflow steps) in a log called the history. In case of a crash, Temporal rehydrates the workflow; that is, Temporal restarts the workflow execution, deduplicates the invocation of all activities that have already been executed, and catches up to where it previously left off. It does all this without requiring anything special for this to happen in the application code, meaning failure handling is entirely outsourced to Temporal.
“Long-running” Workflow examples
To clearly illustrate what it’s like to program with Temporal, it’s worth discussing long-running workflows and some business use cases relevant to developers and infrastructure teams. Long-running isn’t really about some arbitrary cutoff in time — it can be short or infinitely long. A workflow might be something you already have implemented in a single service or application. Below are two examples I found helpful from Temporal’s blog:
- Box uses Temporal for orchestrating file update operations. Although this can take hours for large transfers, most of these feel instantaneous to users. Ideally, we want one solution to scale from the smallest to largest use cases with no more visible latency than necessary. Box uses Temporal more for transactional and reliability guarantees around microservice orchestration, and the words "Long Running" were never even mentioned.
- Checkr uses Temporal for coordinating background checks. This is a multi-staged process with a vast range in processing times, ranging from pinging a database search API to dispatching a court researcher to a courthouse, followed by analyzing each record and potentially escalating to manual QA. The process could take days, and Temporal solves this by persisting event histories as a source of truth, solving for both observability and reliability in one fell swoop.
In practice, this means you can write infinitely long-running Workflows. For example, you could use this for various e-commerce cases such as:
- Coordinating actions like loyalty rewards
- Subscription Charges
- Setting up reminder emails over the entire lifetime of your relationship with the customer.
Where does PlanetScale fit in?
A Temporal cluster is a Temporal Server paired with a persistence layer (i.e., the data access layer). All the workflow data—task queues, execution state, activity logs—are stored in a persistent Data Store. Temporal offers two storage options:
- A SQL option (namely, MySQL and PostgreSQL)
- A No-SQL option (namely Cassandra)
If you choose SQL, you trade operational simplicity for scalability. If you decide on No-SQL, you trade scalability for operational complexity. If you choose PlanetScale, you get both: operational simplicity and scalability.
The database stores the following types of data:
- Tasks to be dispatched
- The state of Workflow Executions
- The mutable state of Workflow Executions
- Event History, which provides an append-only log of Workflow Execution History Events
- Namespace metadata for each Namespace in the Cluster
- Visibility data, which enables operations like "show all running Workflow Executions”
At the core of PlanetScale, we are MySQL with Vitess as a middleware.
Vitess was built in 2010 to solve scaling issues at YouTube. Since then, the open source project has continued to grow and now helps several companies like Slack and Square handle their massive data scaling needs.
This means that we are built for heavily distributed applications experiencing a high load. A PlanetScale database completes the simplest Temporal deployment diagram.
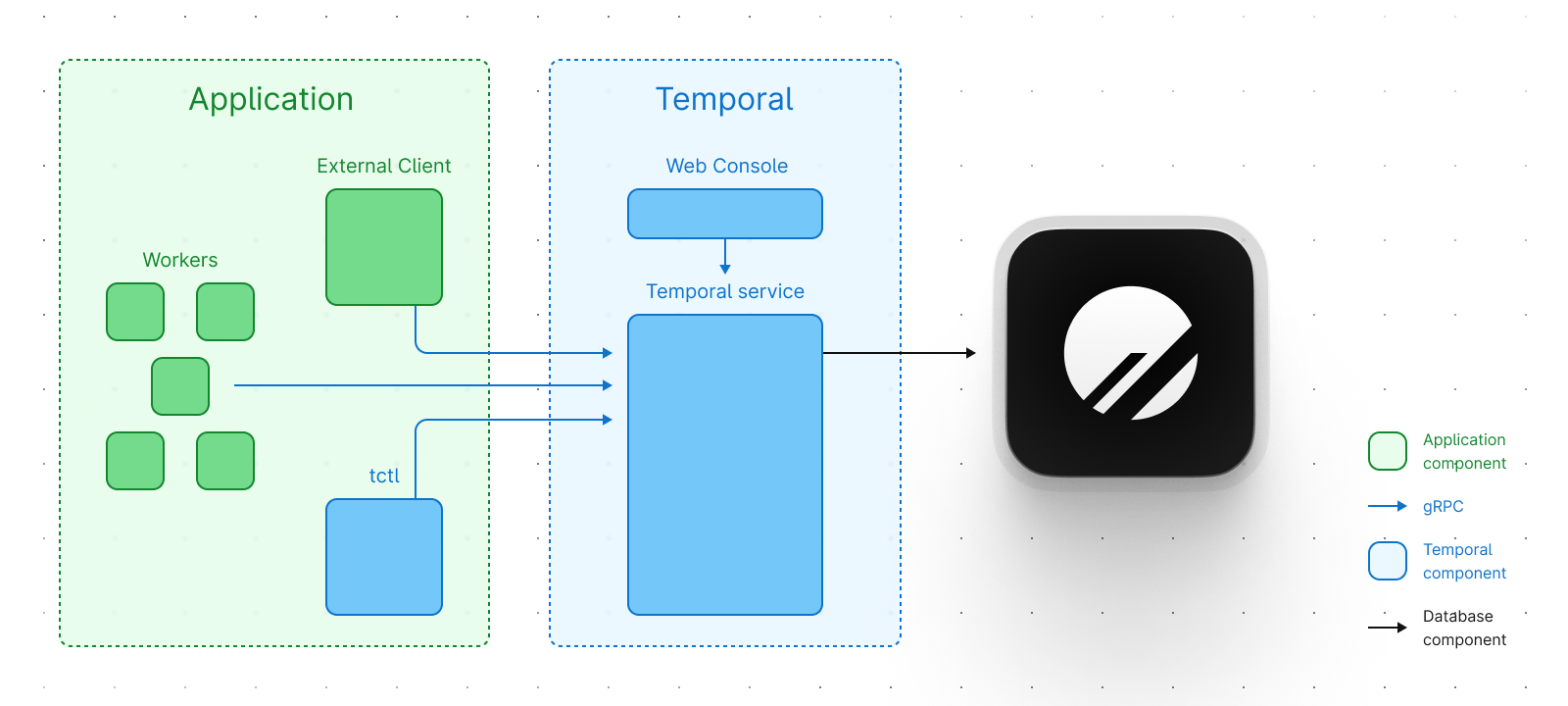
PlanetScale horizontally scales by combining an arbitrary number of MySQL instances and by horizontally partitioning your data over these clusters according to a customizable partitioning strategy. Since Temporal also uses horizontal partitioning (more information can be found here), Temporal maps effortlessly onto PlanetScale and can take full advantage of PlanetScale’s scalability improvements over a single MySQL instance.
Getting started with Temporal
There are four ways to install and run a Temporal Cluster quickly:
- Docker: Using Docker Compose makes it easy to develop your Temporal Application locally.
- Render: Our temporalio/docker-compose experience has been translated to Render's Blueprint format for an alternative cloud connection.
- Helm charts: Deploying a Cluster to Kubernetes is an easy way to test the system and develop Temporal Applications.
- Gitpod: One-click deployments are available for Go and TypeScript.
Temporal does not recommend using any of these methods in a full (production) environment, so we’ll only use these for development. To use PlanetScale with Temporal, you can use docker-compose and manually create temporal and temporal_visibility tables in PlanetScale.
In the next blog, we will walk you through setting up your docker-compose files to run in PlanetScale using this example.