Announcing PlanetScale Metal
Metal is the latest iteration of PlanetScale’s scalable cloud OLTP database platform powered by Vitess (MySQL-compatible) and Postgres, and now by fast, local NVMe drives that offer effectively unlimited IOPS to ensure your database is screaming fast, especially when your data doesn’t fit in RAM.
Typical PlanetScale Metal configurations are cost-neutral or less expensive than equivalent PlanetScale or Amazon Aurora configurations. When you consider the performance you get per dollar, there’s no contest.
Metal differs from the PlanetScale you already know well in exactly one way: We’ve substituted Amazon EBS and Google Persistent Disk with the fast, local NVMe drives available from the cloud providers. But this small step for an architecture represents a giant leap for performance and price without having to give up durability, reliability, or scalability.
Why network-attached storage isn’t ideal for databases
Network-attached storage products like Amazon EBS and Google Persistent Disk are a lowest-common-denominator technology that make it very easy to do an OK job of building fairly reliable systems. They can be attached to and detached from virtual machines while retaining the data they’re storing, which makes them convenient. They replicate the blocks they’re storing behind the scenes, making one of these volumes more durable than a single hard drive.
But they suffer from problems inherent with separating storage and compute: They’re high latency and that latency varies wildly. Writes to these network-attached volumes pass through a NIC, network gear, and another machine before landing on a hard drive. No amount of engineering from the cloud providers can mask the physical reality that network-attached storage is very far away.
They’re also lower throughput. Even at the very expensive upper end – EBS io2, for example – the network holds the storage hardware back. A local NVMe drive can often perform an order of magnitude more IOPS than a network-attached storage volume.
Take the EBS performance of an r6i.4xlarge EC2 instance, for example. It can perform 40,000 IOPS if the volume or volumes can keep up. (Some EC2 instance types require striping multiple EBS volumes to achieve their maximum performance.) By contrast, an i4i.4xlarge EC2 instance can perform 220,000 random write or 400,000 random read IOPS using local NVMe SSDs!
Network-attached storage is also expensive – $80 per TB for the slowest configuration to $2,573 per TB for the highest-performance EBS io2 volumes most instances can support. All that extra (hidden) hardware behind the scenes adds up. For example, that same i4i.4xlarge is less expensive than an equivalently sized EBS gp3 volume with only 16,000 IOPS attached to an r6i.4xlarge.
What Metal is for
PlanetScale Metal is for high-I/O databases. It’s for the most demanding, most critical workloads. It’s for databases where microseconds matter. And the powerful hardware that enables Metal to serve the most difficult workloads makes everything else faster and more consistent, too.
Constant, wide-ranging, random reads? Working sets that don’t fit into the InnoDB buffer pool? Metal can help you shrink or even avoid a fleet of read-only replicas. memcached? Leave it in the box.
Massive write throughput? Replicas can’t even keep up with the primary? Metal can make your workload fit on fewer shards or maybe even make sharding unnecessary at all.
Low tolerance for high latency? Metal’s directly-attached NVMe drives offer lower and more consistent read and write latency than any network-attached storage.
Why Metal is fast
The magnetic hard drives that were common when MySQL earned its production stripes could do maybe hundreds of IOPS. They were I/O-bound if you so much as looked at them funny. SSDs, first connected via SATA, then SAS, and nowadays NVMe, changed the equation. I/O latency is lower now because SSDs don’t need to seek and because the interconnects have gotten faster, too. Throughput is higher because the interconnects have higher bandwidth.
And that’s really the secret of PlanetScale Metal: Hardware is really good now. The rest is PlanetScale doing everything it takes to let that hardware shine.
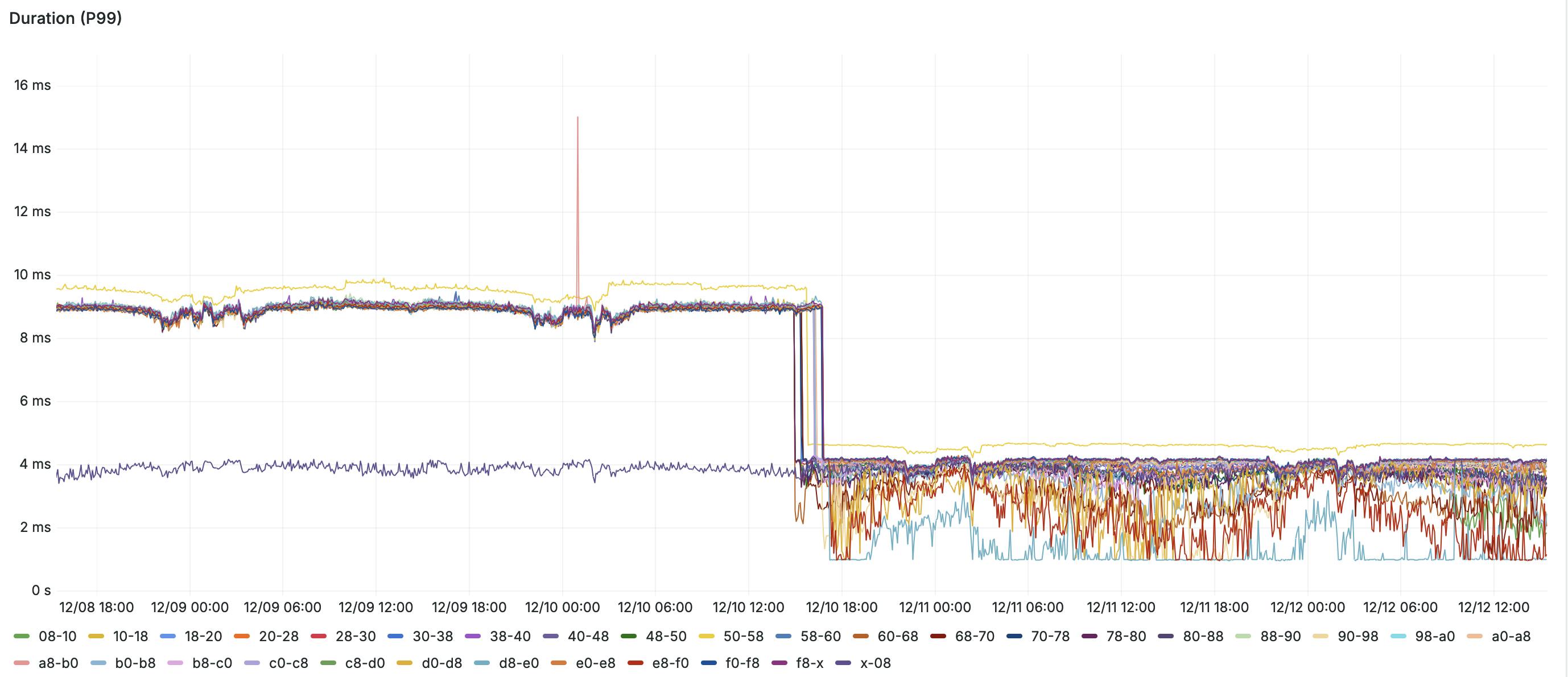
Consider a real, million-QPS, production workload on PlanetScale. Its network-attached storage volumes report I/O latency around 1ms. We recently migrated it to PlanetScale Metal, using NVMe drives with I/O latency on the order of microseconds. As a result, its 99th percentile query latency dropped from 9ms to 4ms.
Why Metal databases are durable
The basis for any distributed system’s durability claim is replication. PlanetScale and PlanetScale Metal are no different. The replication that matters here is semi-synchronous, row-based, MySQL replication from a primary to two replicas distributed across three availability zones within a cloud region.
Semi-synchronous replication ensures every write has reached stable storage in two availability zones before it’s acknowledged to the client. Row-based replication integrates logically into transaction processing which allows readable replicas and backups.
PlanetScale databases, Metal or not, are backed up at least daily. More importantly, each and every backup taken is tested by actually restoring it and starting up MySQL. This allows us to automatically and quickly replace failed replicas.
Notably absent from the basis for PlanetScale’s durability is the replication built into network-attached storage products like Amazon EBS and Google Persistent Disk. These volumes fail, or get slow, to a significant enough degree that they simply aren’t good enough as a basis for the durability of a production database.
However, when one of the virtual machines serving one of the three replicas has a fault, the ability to re-attach a storage volume is a significant advantage over having to restore a backup, purely in terms of wall-clock time. In order to quantify the difference, we made some assumptions that were unfair to Metal to see where it stacks up. First of all we assume that 1% of Amazon EC2 instances will fail within 30 days; this is far more often than we observe in production. Then we assume it takes five minutes to detach an Amazon EBS volume, launch a new EC2 instance, and attach that volume to it; we think this is on the fast side of fair. Finally, we assume it takes five hours to restore a backup; this is wildly conservative compared to restore times we see in production for even terabyte-scale databases.
The first failure scenario of note is losing write availability. This requires losing two of the three replicas within the amount of time it takes to re-attach a volume or restore a backup. Given these assumptions, the probability of a PlanetScale Metal database losing write availability due to hardware failure is about 0.000001%.
The second failure scenario is losing all three replicas – data loss. Given these same assumptions, the probability of a PlanetScale Metal database losing data due to hardware failure is about 0.00000000003%.
Durability through replication, backup, and restore is powerful.
This performance comes cheap
Typically, if you want performance and durability you’re expecting to have to compromise on price. As it happens, because coaxing serious performance out of network-attached storage often costs 30 times what the basic network-attached storage costs, local NVMe drives end up being the high-performance and low-dollar option. In fact, a high-performance network-attached storage volume capable of even 20,000 IOPS usually costs more than the virtual machine it’s attached to.
As a concrete measure of how cost effectively PlanetScale Metal delivers performance, consider these ratios of IOPS per dollar for a variety of configurations running in AWS on r6a and i4i instance types:
| IOPS / $ (On-Demand price) | xlarge | 2xlarge | 4xlarge |
|---|---|---|---|
| r6a with EBS gp3 (3,000 IOPS) | 3.35 | 1.68 | 0.84 |
| r6a with EBS gp3 (16,000 IOPS) | 13.2 | 7.57 | 4.11 |
| r6a with EBS io2 (20,000 IOPS) | 3.80 | 3.18 | 2.40 |
| r6a with EBS io2 (40,000 IOPS) | 4.45 | 3.99 | 3.31 |
| i4i with instance storage | 58.41 | 58.48 | 58.50 |
In pure dollar terms, many configurations of PlanetScale Metal in AWS are less expensive even than configurations using Amazon EBS gp3 with 16,000 IOPS.
But that’s not all. Amazon EBS cannot be discounted by either Reserved Instances or Savings Plans but the instance storage that comes with the instances PlanetScale Metal uses can be. PlanetScale Managed customers that adopt Metal can realize even greater savings while still achieving performance network-attached storage can’t touch.
Start using Metal today
PlanetScale Metal is available today in both AWS and GCP. Visit your PlanetScale dashboard to create a new Metal database, migrate an existing PlanetScale database to Metal (online, naturally), or import a database from elsewhere straight into PlanetScale Metal.
Contact us to learn more about Metal.