Introduction
In this blog post, we will discuss an example of a change to the Vitess query planner and how it enhances the optimization process. The new model focuses on making every step in the optimization pipeline a runnable plan. This approach offers several benefits, including simpler understanding and reasoning, ease of testing, and the ability to use arbitrary expressions in ordering, grouping, and aggregations.
Vitess distributed query planner
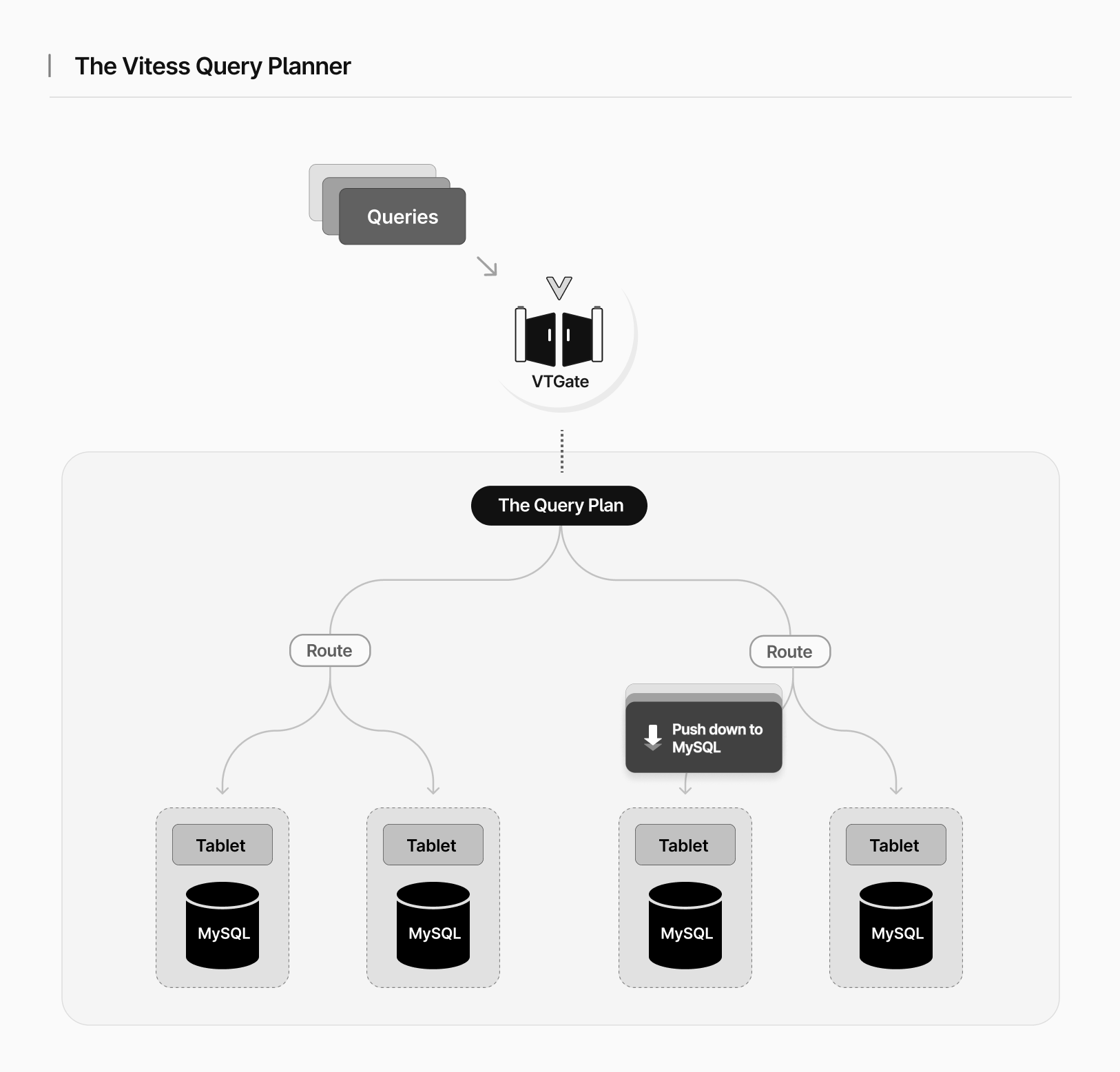
VTGate is the proxy component of Vitess. It accepts queries from users and plans how to spread the query across multiple shards and/or keyspaces. The leaf level of the VTGate query plans are "routes," which are operators that will send a query to one or more shards.
When something can be pushed into the route, it means that MySQL will do the work, and we don't have to do much work on the VTGate side. The aim is always to push as much as possible down to the much faster MySQL process. This approach helps to offload processing to MySQL and keep the VTGate layer efficient. This also reduces the risk of compatibility differences between Vitess and plain MySQL, since MySQL is doing most of the work.
Changes in the query planning model
In our query planning model, the optimization process began by determining the join order between the tables. The "join order" refers to the sequence in which tables are joined to form the final result set.
Once the join order is established, the planner proceeds with horizon planning. A “horizon” operator contains the SELECT expressions, aggregations, ORDER BY, GROUP BY, and LIMIT. If we can push the entire operator to MySQL, we don’t need to plan this at all. If we can’t delegate it to MySQL in a single piece, we have to plan these components separately.
In a database query planner where everything is evaluated locally, this part of query planning is straightforward — we add the necessary Sort/GroupBy/Limit/Project operators and we are pretty much done. Naturally, there are additional optimizations one could perform, but these would typically yield only marginal improvements to the performance of the query plan. In a distributed query planner, the cost of transmitting data means that it's essential to push down as much of these operations as possible to the data.
You can read more about how we plan grouping and aggregations while pushing down work in our Grouping and Aggregations on Vitess blog post.
In this new model for our planner, we are still performing the same optimizations as before, but we are going about it in a very different way.
In the old model, we performed the optimization more in a top-down approach — we planned the full aggregation, and all ordering needed to support it, in one go. We would start with the join order tree, and do a lot of logic, and then output a new tree that performed the correct aggregations. In between the two, most of the current state was kept in arguments, local variables, and in the stack.
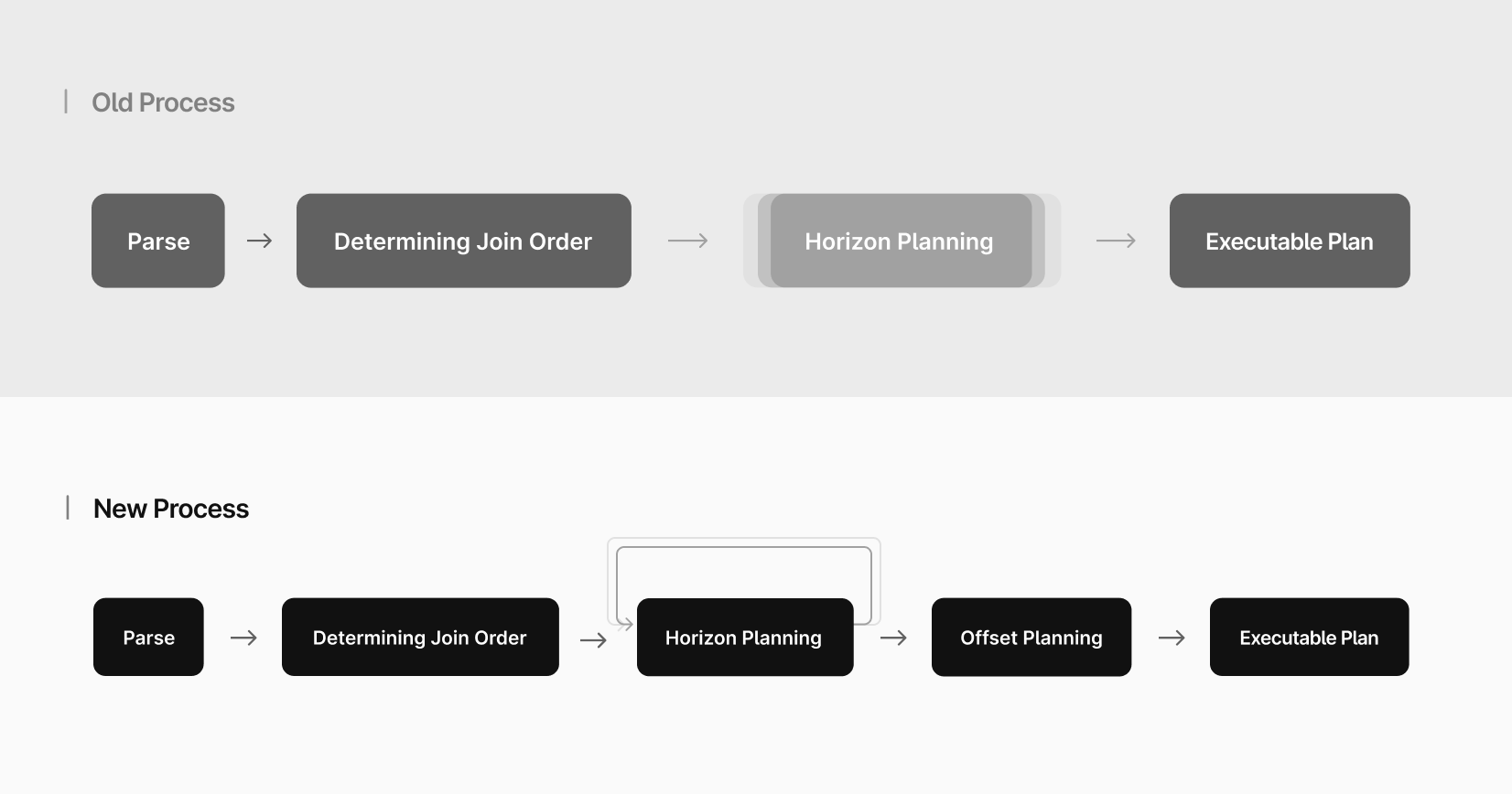
In the new query planning model, every step in the optimization pipeline results in a runnable plan. This means that developers working on the planner can inspect the plan at any stage, allowing for a better understanding of the optimization process at each step. By having runnable plans at every step, it becomes easier to identify potential issues, inefficiencies, or areas where further optimization is possible.
Each step is also simpler — it's a tree transformation taking two operators as input, one being the input of the other, and producing a new subtree that replaces the two inputs.
This improvement not only simplifies the optimization process but also enhances the ability to reason about the impact of each optimization step.
Other benefits of the new process
Visualization improvements
Compared to the old model, the new query planning model offers better visualization of the optimization steps. In the old model, the current optimization state was kept in the stack and local variables, making it harder to visualize and understand the process. With the new model, each step is represented as a full query plan, which provides a clearer picture of the optimization process.
Testability
Another benefit of this model is the possibility of running both the unoptimized plan and the optimized version and comparing their results. It should not matter if we have to evaluate a WHERE predicate on the VTGate side with our excellent evalengine support for most MySQL expressions, or if we can delegate it to the underlying database. The result should be the same.
Flexibility with expressions
The new query planning model allows for arbitrary expressions to be used for ordering, grouping, and aggregations. This provides greater flexibility when crafting complex queries and enables developers to write more efficient and optimized queries. In comparison, the old model had limitations in terms of the expressions that could be used in these operations.
Example query and optimization steps
To illustrate the benefits of the new query planning model, let's examine the optimization steps while planning a query. This is done using a so-called fixed point rewriter — the planner will continue rewriting the plan tree until it stops changing.
Let’s look at an example query:
SELECT u.foo, ue.bar
FROM user u JOIN user_extra ue ON u.uid = ue.uid
ORDER BY u.baz
Step 1
In the first step of planning, we have an operator tree that looks like this:
Horizon
└── ApplyJoin (u.uid = ue.uid)
├── Route (Scatter on user)
│ └── Table (user.user)
└── Route (Scatter on user)
└── Filter (:u_uid = ue.uid)
└── Table (user.user_extra)
Everything under a route will be turned into SQL and sent to MySQL.
Step 2
In the next step, we decided that we can't push the Horizon and instead need to expand it into its components.
Ordering (u.baz asc)
└── Projection (u.foo, ue.bar)
└── ApplyJoin (u.uid = ue.uid)
├── Route (Scatter on user)
│ └── Table (user.user)
└── Route (Scatter on user)
└── Filter (:u_uid = ue.uid)
└── Table (user.user_extra)
The Horizon is split into an Ordering and a Projection operator.
Step 3
We continue to push things down — the Projection is split and pushed to both sides of the join, and the Ordering is sent to the left side of the join.
ApplyJoin (u.uid = ue.uid)
├── Ordering (u.baz asc)
│ └── Projection (u.foo)
│ └── Route (Scatter on user)
│ └── Table (user.user)
└── Projection (ue.bar)
└── Route (Scatter on user)
└── Filter (:u_uid = ue.uid)
└── Table (user.user_extra)
Step 4
Finally, we are able to push both Projection and Ordering into the Route on the LHS of the join.
ApplyJoin (u.uid = ue.uid)
├── Route (Scatter on user)
│ └── Ordering (u.baz asc)
│ └── Projection (u.foo)
│ └── Table (user.user)
└── Route (Scatter on user)
└── Projection (ue.bar)
└── Filter (:u_uid = ue.uid)
└── Table (user.user_extra)
So the VTGate plan is ultimately just a join. One query will be sent to the left-hand side, and for each row we get from those results, we will issue a query on the right-hand side of the join.
The two queries are:
-- LHS
SELECT u.foo, u.uid, u.baz, weight_string(u.baz)
FROM `user` AS u
ORDER BY u.baz ASC
-- RHS
SELECT ue.bar
FROM user_extra AS ue WHERE ue.uid = :u_uid
Conclusion
The new query planning model in Vitess brings several advantages over the previous model, making it easier for us to understand and work with one of the most complicated parts of Vitess. With runnable plans at every step, improved visualization, and increased flexibility with expressions, we hope that this will form a design that we can grow with.
As Vitess continues to evolve, we can expect even more enhancements and optimizations to its query planning capabilities.