A powerful feature of serverless computing architecture is the ability to design and horizontally scale individual components of your stack, allowing more computing resources to be allocated on the fly to be used only when you need them. Databases are an essential part of the serverless stack, but people using serverless functions are finding an all too common problem with databases: connection limits. Users are forced to use proxies such as pgbouncer to handle even small workloads. With MySQL, the dreaded “Too many connections” error rings all too familiar for developers who are seeing a sudden surge in users.
A standalone database relies heavily on its ability to compartmentalize memory use to provide the strong isolation guarantees we expect, so it needs to allocate certain memory buffers on a per-connection basis. The more connections we create, the less memory we have available for the overall buffer pool, and so MySQL comes with a max_connections variable built in that acts as a “last resort” safety measure. This setting stops new connections from being established after the configured point, and it’s critical to avoid situations like an unexpected Denial of Service attack causing a memory-related outage on the database level. While it may seem harmless to raise this variable at first (you may not be approaching the instance memory limits quite yet), making MySQL live outside its means (i.e. overcommitting memory) opens the door to dangerous crashes and potential downtime, so this is not recommended.
Application connection pools
Now, establishing and cleaning up connections also takes time and computing resources, so many development frameworks offer built-in functionality like connection pools. Connection pools allow a bulk amount of connections to be established up front and for the application to queue up its database requests on that side. While that works really well as both a performance optimization and safety feature for the database side, application-side connection pools become a similarly challenging area when trying to scale a serverless stack.
PlanetScale connection pooling
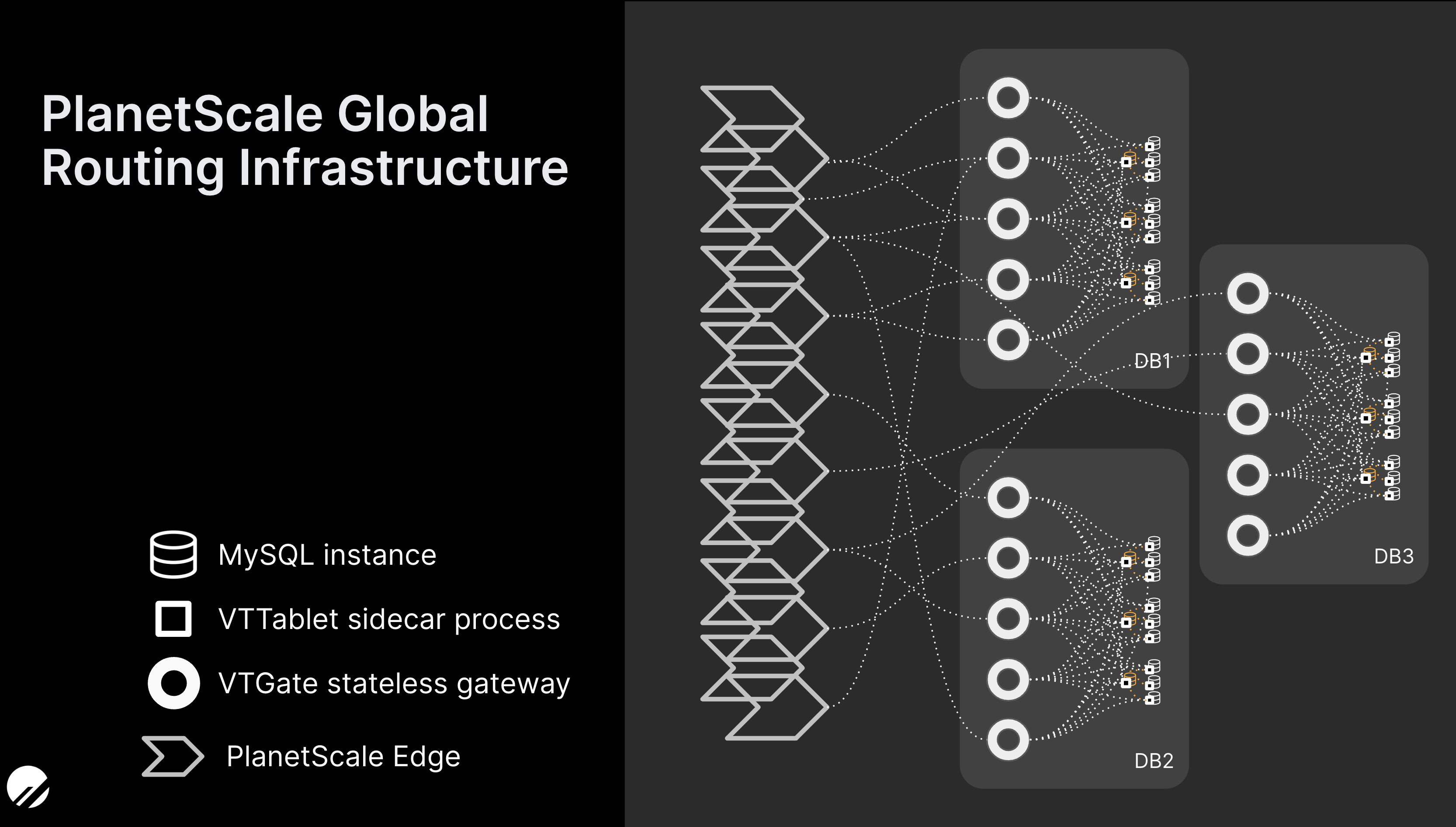
To both safeguard and optimize connection management for MySQL, Vitess and PlanetScale offer connection pooling on the VTTablet level. This scales alongside your cluster, and also allows for connection requests to be queued up there when a sudden application scale-up starts sending queries from a very large amount of horizontally spawned processes. This keeps the underlying MySQL processes safe from a memory management standpoint, and allows you to keep adding workers as needed to scale the application.
In addition to that, PlanetScale’s Global Routing Infrastructure provides another horizontally scalable layer of connectivity, which we put to the test recently to help us prepare for the broader rollout of our serverless driver.
One million MySQL connections
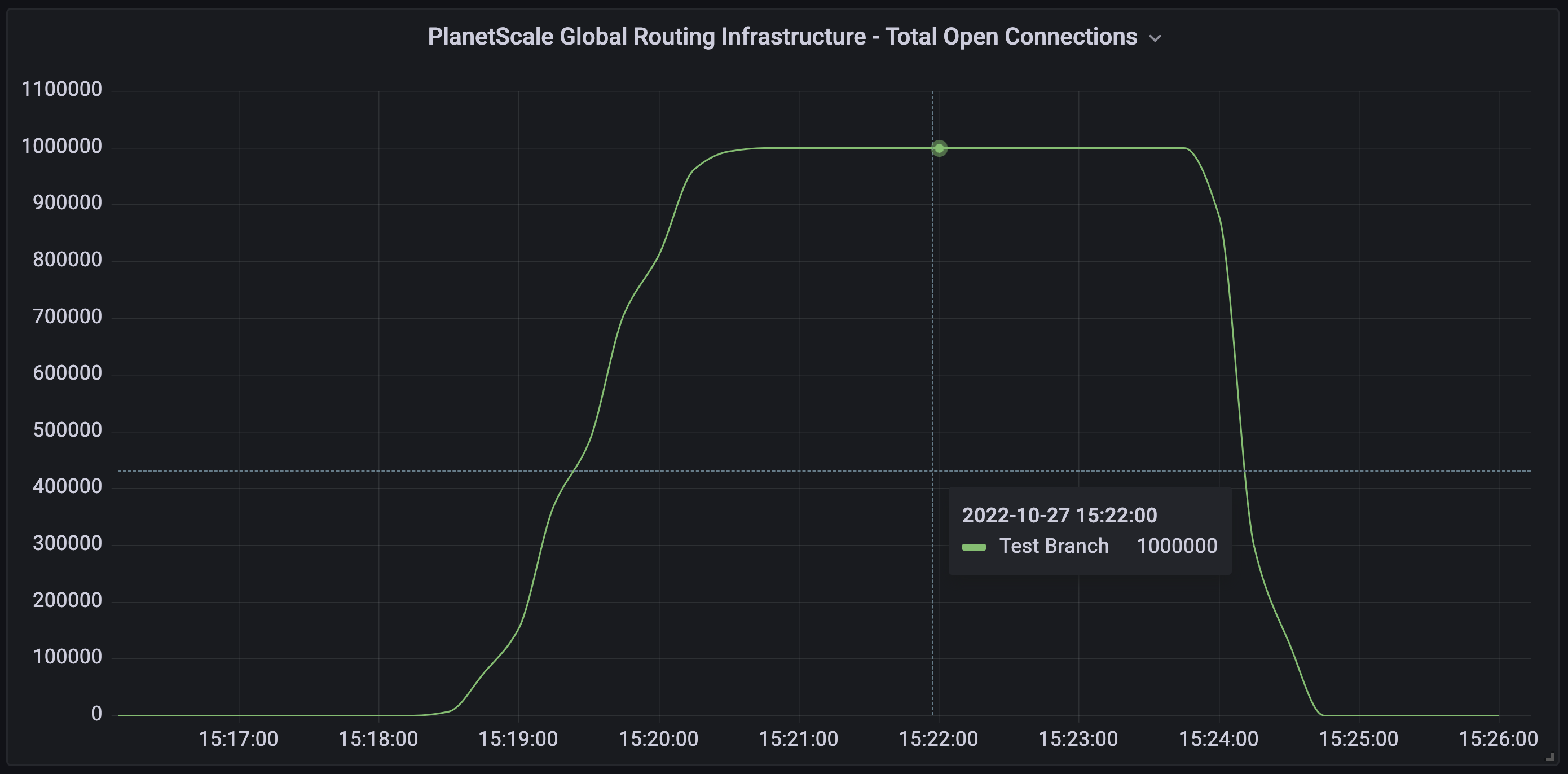
This combination of Vitess connection pooling and the PlanetScale Global Routing Infrastructure enables us to maintain nearly limitless connections. We decided to put this to the test by running one million active connections on a PlanetScale database. Keeping with our “One million” blog theme, the target itself should be considered no more than an arbitrary number. After all, our architecture is designed to keep scaling horizontally beyond that point. However, it’s high enough to serve most of our users’ needs and illustrates the capabilities of the architecture.
To isolate our connection layer, we devised a test environment that makes use of AWS Lambda, using a fan-out pattern to run a simple Go executable that uses the go-sql-driver to establish a number of parallel connections.
Interesting fact we ran into here: by default, the Lambda runtime environment has a hard open_files limit of 1024 and a function concurrency limit of 1000. As such, we configured our test to run a total of exactly 1000 “worker functions”, each of which established exactly 1000 connections, so we could stay within the Lambda runtime limits.
Each worker loop executes the following:
- Opens a new connection to MySQL
- Once established, sends a simple query to verify we can talk to the underlying database.
- Waits for the other loops to finish creating their connections.
Once we reach the desired concurrency, all workers are instructed to wait an extra few minutes with an open connection before closing out, so we can easily observe the stable parallelism in monitoring. We were able to scale up to maintain a total of one million open connections in under two minutes.
The PlanetScale Global Routing Infrastructure is ready for your serverless function workloads. Sign up to try it out yourself, or reach out to talk to us if you’d like to learn how to make our scalability work for your application.