You can now create global replica credentials that will automatically route reads to the nearest read replica from anywhere on the planet.
All PlanetScale clusters are made up of, at minimum, one primary and two replicas in the same region spread across three availability zones. With today's release, it's now much easier to utilize this extra compute by creating a single password dedicated for replica use. Global replica credentials automatically load-balance across the replicas in a region for you.
These new credentials also seamlessly route to the read-only region with the lowest latency without any code changes, even as you add or remove new read-only regions. The underlying architecture, PlanetScale Global Network, also manages this without requiring you to reconnect. This allows you to add a read-only region and start using it immediately.
If you have existing replica credentials for each of your read-only regions, you can now swap them out for a single global replica credential.
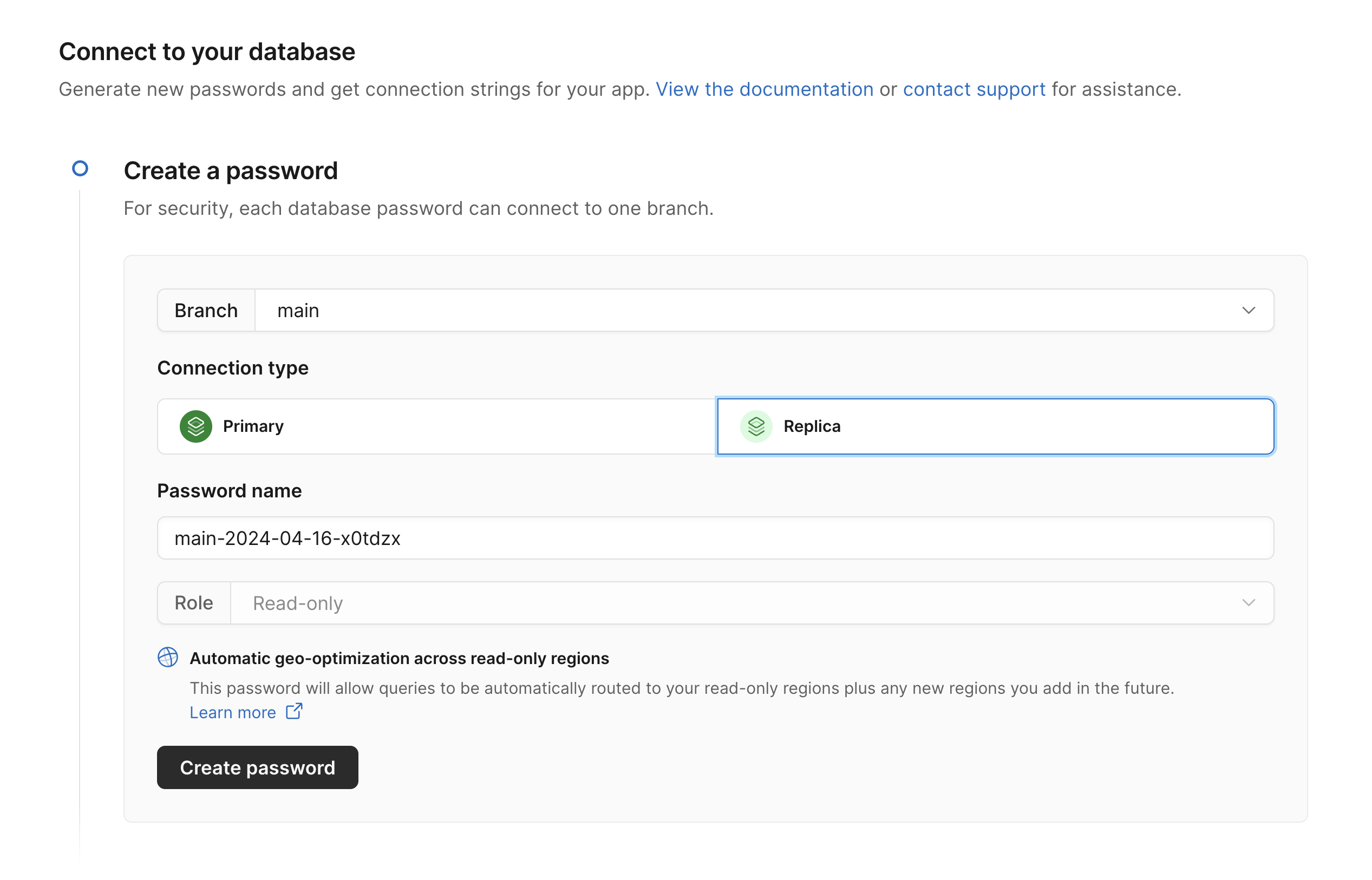
Using global replica credentials is as simple as clicking “Connect” from the PlanetScale dashboard, selecting “Replica”, and generating your new credentials. You can also generate credentials from the CLI or API. If you have the CLI installed and you want to try replica credentials out in a MySQL console, you can run pscale shell --replica. See the Replica documentation for more information.
Building PlanetScale Global Network
For the past few years, we have been quietly building and architecting a database connectivity layer structured like a CDN, this layer we call the PlanetScale Global Network.
This layer is responsible for a few things:
- Terminating every MySQL connection globally.
- Handling our RPC API (to support things like database-js).
- Connection pooling at a near infinite scale.
- TLS termination.
- Routing connections to your database.
At a high level, the first step when connecting to your database is connecting to our Edge network. Where this is like a CDN, is this first hop is nearest to you geographically, or nearest to your application. Whether you are directly in AWS next door, or on the other side of the world, connections begin at our edge network.
Once in our network, we fully terminate the MySQL connection and TLS handshake at the outermost layer, closest to your application. And connection pooling happens here, similar to running an instance of ProxySQL in your datacenter. From this outer layer, connections are able to be multiplexed and tunneled back to your origin database over a small number of long held, encrypted connections that are already warmed up and ready to go.
The net effect of this is TCP and TLS handshake is faster, since there's less network latency and less hops needed. By terminating this closest to you, a handshake can happen faster. By doing this at the MySQL connection layer is what separates us from a traditional CDN or Network Accelerator. Similar to an HTTP proxy, the MySQL connection pooler is able to complete the full MySQL handshake as well closest to you, and keep chatter over a shorter geographic distance.
What's in a Credential?
A Credential to us is broken up into three pieces, the Credential, a Route, and an Endpoint. The Route is shared to every geographic region at our edge, and the Credential remains inside your unique database cluster region. While the Endpoint is the hostname you use to connect to us, typically something like aws.connect.psdb.cloud or gcp.connect.psdb.cloud.
The Route and Credential are stored in etcd which we are able to watch for changes in near realtime and respond to mutations, or deletions as soon as they happen.
The Route
In practice, a Route to us looks like this:
message Route {
string branch = 1;
repeated string cluster = 2;
fixed64 expiration = 3;
...
}
If you notice, this Route contains no authentication information and is not authoritative for auth, it is effectively a mapping of username to a list of clusters. This list of clusters covers where this database branch is running.
In the case of a normal, single Primary credential, this Route may look like:
Route(branch="abc123", cluster=["us-east-1"])
In the case of a Replica credential that has multiple read-only regions, this cluster expands for that list of all of them.
Route(branch="abc123", cluster=["us-east-1", "us-west-2"])
Now we have a single Route with multiple options of where we could go.
The Credential
I'm not going to go into a bunch of detail here since a lot of it is internal implementation, but the Credential is effectively the source of truth for authentication and only exists inside the same cluster as your database.
It relatively looks like this:
enum TabletType {
TABLET_TYPE_UNSPECIFIED = 0;
TABLET_TYPE_PRIMARY = 1;
TABLET_TYPE_REPLICA = 2;
TABLET_TYPE_RDONLY = 3;
}
message Credential {
string branch = 1;
bytes password_sha256 = 2;
psdb.data.v1.Role role = 3;
fixed64 expiration = 4;
TabletType tablet_type = 5;
}
In here, we contain more information about the Credential, including the Role/ACL assigned at creation, the information needed to verify the password is correct, and an additional TabletType which indicates if this is intended for a primary, replica, or readonly database. This is all automatic and is just an internal representation.
While the Route is just a mapping of username -> cluster, the Credential contains the rest of the information needed to fully connect to the underlying database with the correct ACLs and to which TabletType.
The Endpoint
Now the endpoint is where the first bit of magic happens. As you may have noticed in the product, we surface two different hostname options, a "Direct" and an "Optimized". The "Direct" has the form of {region}.connect.psdb.cloud and the "Optimized" is of the form {provider}.connect.psdb.cloud.
The Direct endpoint is the most straightforward, and represents the Edge node in that region explicitly. You can choose really any region you'd like as the first hop to route through and you'll still get to the correct destination, but we give you the endpoint that is closest to the database, not the endpoint closest to you. But really, you can pick any public endpoint in the same provider if you're clever.
The Optimized endpoint is backed by a latency-based DNS resolver. In AWS, for example, this is their Route53 latency-based routing policy. Which is most of the magic to resolve aws.connect.psdb.cloud to the nearest edge region to you. This means whether you're connecting from your local machine with pscale connect or from the datacenter next to your database, you get routed through the closest region to you, which gives us the CDN effect.
Putting this together
With these three bits, we can put together the story for how we can route to any of your replicas geographically.
Starting with the initial connection pool at our edge, this applies exactly the same to a connection over HTTP and MySQL protocol.
Once a connection is established to us, regardless of where your database is located, your connection is terminated at this same edge node in our network. When a new region is added, the underlying Route is mutated to add the new cluster.
Since we maintain warm connections between all of our regions ready to go, we utilize these to measure latency continuously as a part of regular health checking. So, for example, the us-east-1 edge node is continuously pinging its peers, similar to a mesh network and measuring their latency.
Once a Route is seen over the etcd watcher, before it's accessible to being used, we are able to simply sort the list of clusters based on their latency times we already are tracking. We periodically re-sort every Route if/when latency values change. This keeps the "next hop" decision always clusters[0] in practice. In the event if a hard failure (if for some reason this entire region were down), we could go over to the next option if there were multiple choices.
Ultimately, because the connection is already established with us during all of this, the Route is utilized on a per-query basis, thus without needing to reconnect or anything, we can route you to the lowest latency next hop in realtime.
Similarly, when read-only regions are added and removed, we only need to mutate this Route with a new set of what regions your database is in, and we just maintain a sorted list ready to go.