Scaling a database presents challenges. As you grow, you might begin having trouble handling ever-increasing throughput or data size. You might find that query latency is getting worse. You might be pushing the limits of your hardware. When this happens, a classic option is vertically scaling your database by getting better hardware, but is there a better way? And what happens when you reach the vertical limits?
This is where horizontal sharding comes in. In this article, we'll cover some common indicators that your database may be ready for horizontal sharding. We'll also look at some measures you can implement until then. Let's dig in.
Signs your database is hitting its scaling limits
There are lots of different limits that you can run into when you're scaling up. At the database level, you might be maxing out CPU, memory, disk space, or IOPS.
Running into these limits can have real consequences for your business. Database operations like schema changes will start taking longer, making it harder to ship new features. Query latency will increase, leading to sluggish responsiveness. As things get worse, hitting these limits leads to incidents and you start facing outages.
What are your options for scaling your database?
Before you begin to think about sharding, let's make sure you've first exhausted some of the other options.
After a single server is maxed out, you need to spread the load across more nodes. There are several approaches that you can use.
Option 1: Scale reads with replicas
A tried-and-true method for scaling MySQL or Postgres is using replicas for reads. In addition to setting up the replicas, this involves application changes to split reads and writes to different connection strings. Most web applications are very read-heavy, and this method allows you to continue scaling reads by adding more replicas.
Option 2: Reduce load with vertical sharding (data segmentation)
After that, another strategy is adding more clusters by segmenting logical groups of tables. This means taking all of the tables used by a certain service or product area (for example, users or notifications) and separating them into a new cluster. We sometimes call this vertical sharding or vertical partitioning.
The diagrams below show what it would look like to break a cluster containing users and notifications tables down into vertical shards by moving notifications to a separate cluster. 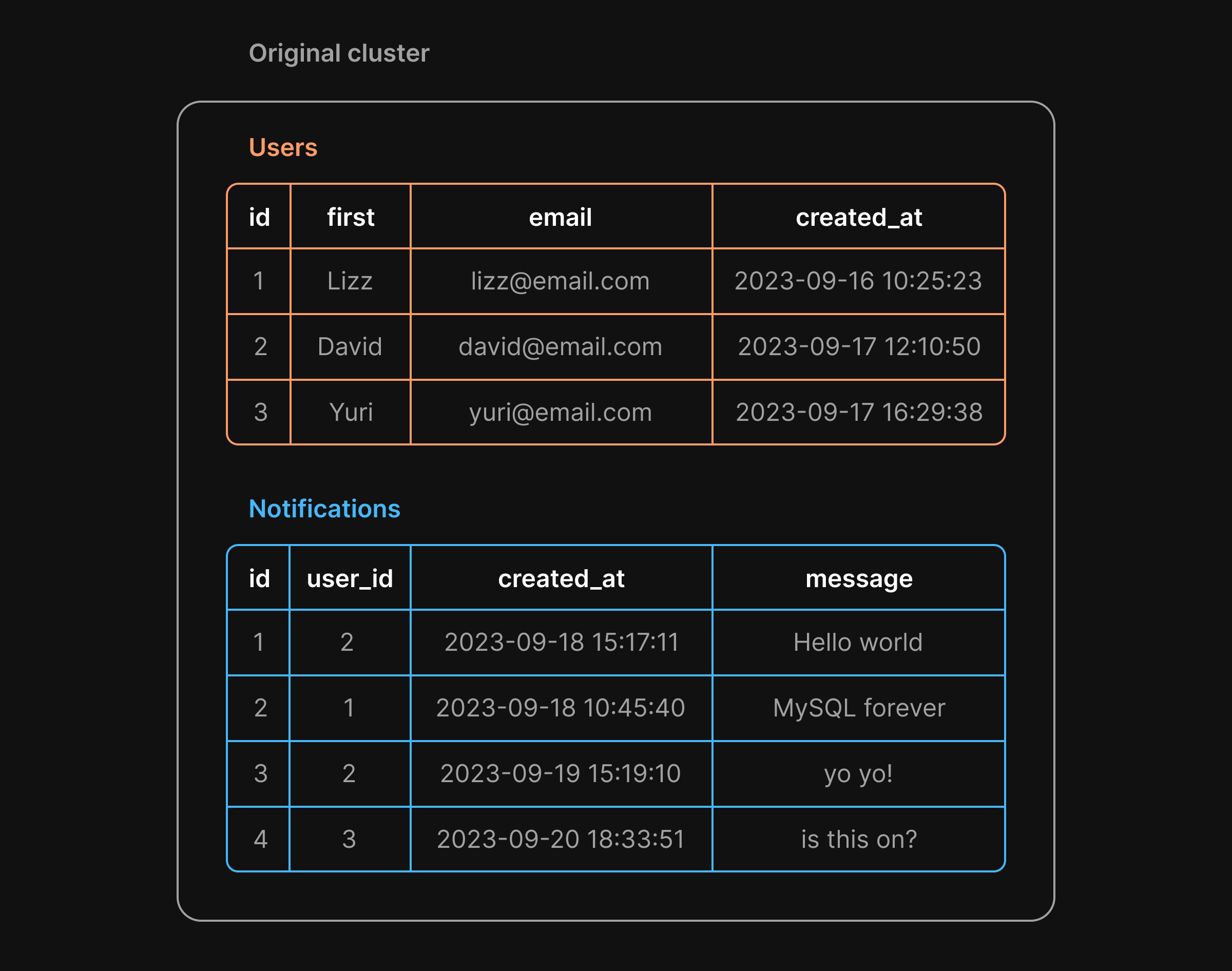
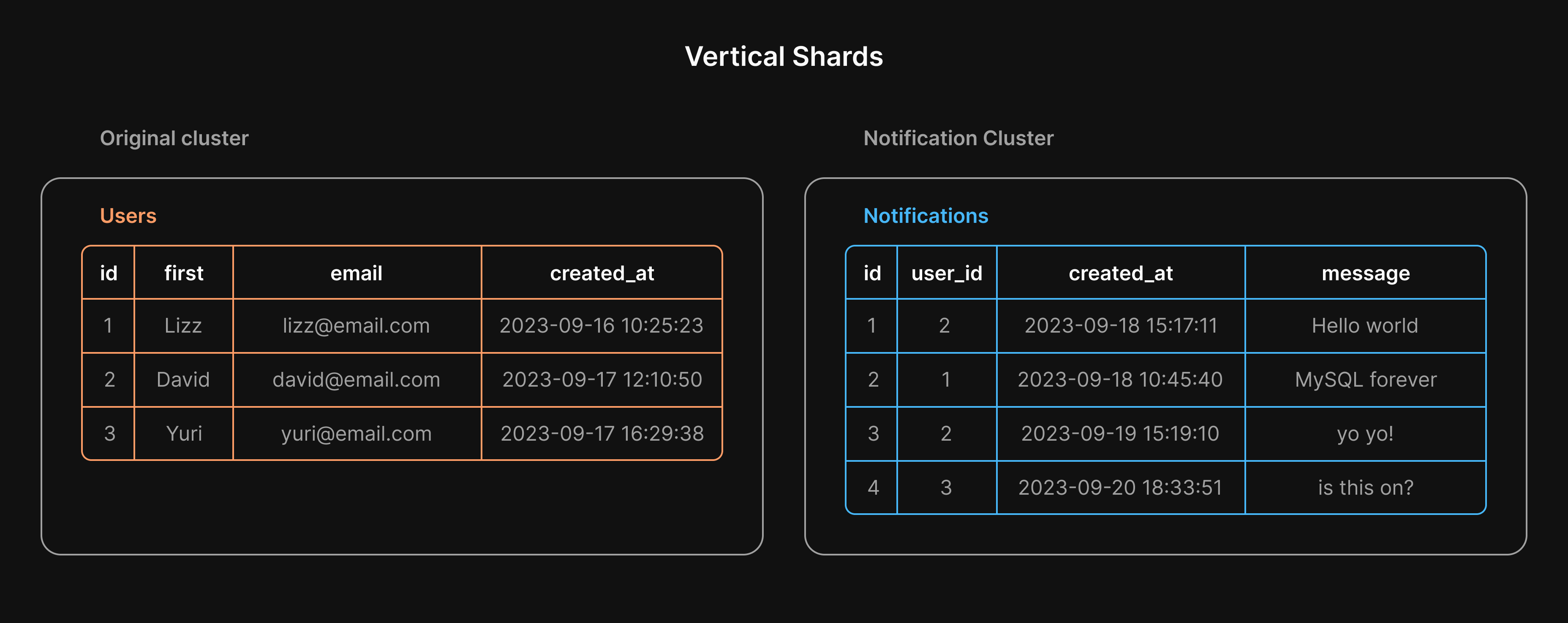
While vertical sharding is a viable option, it does come with some downsides. In addition to the application changes required for these new connection strings, there may be more complex changes to account for the fact that, without a framework like Vitess, you would be unable to perform JOINs between tables that now live on different servers.
Having broken down your databases into their smallest logical groups of tables, you may find yourself in a bit of a jam when one of those clusters starts hitting limits. This is where horizontal sharding comes in.
Option 3: Scale writes and storage with horizontal sharding
Horizontal sharding differs from the vertical sharding described previously. Instead of splitting up a cluster by moving whole tables elsewhere, with horizontal sharding, each underlying cluster shares the same schema and has different rows distributed to it.
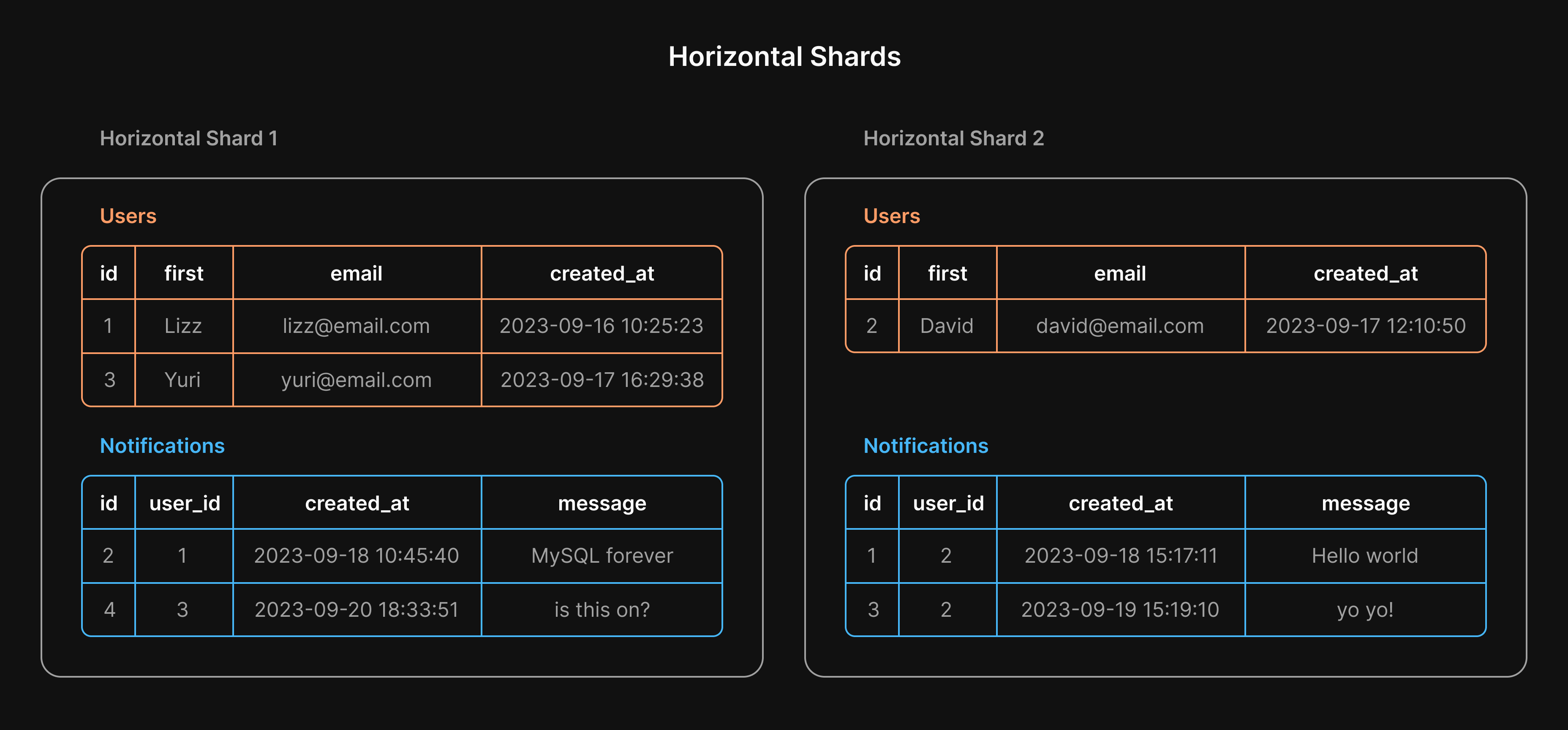
Note
For a more in-depth guide about what sharding is and how it works, check out What is database sharding and how does it work on our blog.
Historically, you needed to be one of the largest webscalers in the world to require sharding, and when you hit those limits, you had to build it yourself. Examples of these include TAO at Facebook, Gizzard at Twitter, and Vitess at YouTube. Sharding was a last resort after you'd exhausted all other options and still needed to handle growth.
When should you shard your MySQL or Postgres database?
Today, we think about it differently. Since its creation at YouTube in 2011, Vitess has become a widely adopted open source solution that has made sharding much more accessible. Sharding is no longer a last resort, and in fact, if adopted earlier, can help you avoid other larger application changes.
So, how do you know when to shard your database? Some good indicators that it may be time to consider sharding are when you've started to max out data size, write throughput, and/or read throughput. Let's walk through each of these categories.
Shard when: data size strains memory and operations
One of the original reasons to shard was because disks were not large enough to hold all of your data. These days, that's not the problem. For example, Backblaze purchased over 40,000 16TB drives!
Data size can still be a driving factor for sharding though. One thing to consider is how large your working set is, and how much of that fits into RAM. As less of your active data fits in memory and more queries need to read from disk, query latency will increase.
Other database operations are also affected by the data size of a single MySQL or Postgres cluster. The larger the database, the longer backups (and restores!) take. The same is true for other operational tasks like provisioning new replicas and making schema changes. This is the logic behind guidelines Vitess has made for shard sizing. Smaller data size per shard improves manageability.
Shard when: write throughput maxes out your primary
Another reason to consider sharding is when you've maxed out the write throughput of your cluster. This can show up in a couple of ways.
When the primary is maxed on IOPS, writes will become less performant. Usually before that, however, replication lag becomes a problem. While there have been significant improvements in replication within MySQL clusters, there will always be a small amount of delay between the time the data is written to the primary and that same data is written to a replica. You may be depending on replicas being up-to-date for disaster recovery, or you may be using replicas to scale out your reads as discussed earlier. When replicas fall behind the primary, this can look like inconsistent or stale data to your users, and may also result in errors if your application expects to be able to read data that it has just written.
Note
With PlanetScale Metal, write throughput is significantly less of a concern. Unlike other solutions such as RDS and CloudSQL that separate storage and compute, Metal keeps them together on the same hardware. This reduces network hops and provides better hardware, delivering substantially higher IOPS. If you're on Metal, you can often delay sharding and continue scaling vertically much further (into the several TB range) than traditional cloud database architectures allow.
When you're hitting your write throughput limits, other database operations like schema changes and batch jobs will be slower as well.
Shard when: read throughput outpaces your replicas
While running out of read throughput capacity can be solved through read-write splitting and the addition of read replicas, that isn't without its own challenges. As mentioned in the previous section, replication lag can make this complex or lead to a poor experience for your users.
Typically, this is earlier than we often think about sharding. However, by scaling read capacity through horizontal sharding instead of by using replicas, application code does not need to account for the potential replication lag or that multiple connection strings need to be managed and utilized depending on the data set you are trying to access. Plus, sharding at this stage sets you up for future growth and you don't have to come back and shard later when write throughput or data size would otherwise become an issue.
Operational benefits of horizontal sharding
Sharding can and should be considered as a solution not just for scaling large data sizes, but also for scaling throughput of reads and writes.
In addition to being able to handle larger workloads, sharding provides other benefits, including:
- Better cost optimization as you scale.
- Increased parallelization leading to faster backups, restores, and schema changes.
- Better SLAs by reducing the blast radius of various failure domains to a single shard.
- Predictable horizontal scalability.
If you're unsure whether or not you're ready to shard, don't hesitate to contact us. We'd love to hop on a call to discuss your workload and scaling options.
FAQs
What is database sharding?
Database sharding is an approach to horizontally scaling a MySQL or Postgres database by splitting data across multiple database instances (called shards), each holding a subset of the total data. Sharding allows you to scale beyond a single server. It improves performance because queries only hit one shard, rather than scanning a massive single table. Finally, it provides fault isolation, since a problem with one shard doesn't necessarily take down others.
When should I consider sharding my database?
You should consider sharding when a single MySQL or Postgres instance can no longer handle your data volume or query throughput, even after optimizing indexes, queries, and adding read replicas. A common signal is when your dataset grows into the hundreds of gigabytes or terabytes and write performance degrades, since read replicas only help with reads. You might also consider it when you hit connection limits or when table locks and contention become a bottleneck that caching alone can't solve. That said, sharding adds significant operational complexity, so exhaust simpler scaling options first.
Does sharding require changes to my application code?
It depends on your approach. If you implement sharding at the application level, yes — your code needs to determine which shard to route each query to, manage multiple connection strings, and handle cases where data spans shards. However, using a sharding layer like Vitess abstracts much of this away: your application talks to a single endpoint and the routing happens transparently, significantly reducing the code changes required. Either way, you'll want to be thoughtful about choosing a shard key early, as changing it later is costly and disruptive.
What solutions are available to implement horizontal sharding?
PlanetScale offers a sharded MySQL option through Vitess, which handles query routing for your shards at the proxy layer so there is no sharding logic in your application code. We're also currently building Neki, our Vitess for Postgres solution for horizontally sharding Postgres.