You and your team have worked tirelessly on finding and hiring the best software engineers around, but are they as productive as they want to be? More and more organizations are focusing on how to improve developer productivity, and we believe it starts with your database. This guide will walk through what slows developers down, why it matters, and how a better database can unlock developer productivity — and ergo, innovation — for your organization.
What slows developers down?
You can hire the most talented engineers out there, but if your processes and tech stack are inefficient and outdated, it’s going to slow the team down.
Technical debt is going to be a part of any company, but too much of it — and a lack of clear guidelines around how your team is tackling it — can waste precious engineering hours.
Friction between teams responsible for different parts of the stack can stick code in limbo. Waiting on a DBA to approve schema changes or run a migration is costly.
Inefficient processes for building, testing, and deploying code can waste engineering time on things that aren’t building customer-facing features.
Clunky tools can require extra time to create something that would be much faster and easier with modern, streamlined tooling.
This guide focuses on a specific, often unsung culprit of lost engineering productivity: your database. You might be surprised to see precisely how impactful it can be when your database and the processes around it prevent your developers from spending their time on what matters.
Your database might be the problem
If you look at most of the things that slow developers down, there’s a theme: they can (and usually do) relate to your application database. Your team just wants to ship code, but a majority of the time, that requires interacting with your database. And this significantly slows down the pace of your team.
Interfacing with a separate team
In sufficiently large organizations, an independent team of DBAs manages the database, reviewing and tuning every desired change from engineers. That separation of responsibilities makes sense — at a certain size, the database becomes too complex for a single engineering team to understand intimately — but completely slows down any momentum for features your engineers are building. 49% of organizations report a lengthy process for database review and approval cycles:
Planning for massive scale while also rapidly iterating on our feature set was a demanding place to be. PlanetScale delivers world-class operations, a scalable platform, and the flexibility the business needed.
The ongoing management and deployment of database changes is by far the slowest and riskiest part of the application release process.
Why? Most of these changes are performed manually by database administrators (DBAs) who spend countless hours to create, review, rework, and deploy database changes in support of rapid application delivery. This creates a huge bottleneck for the overall release process, as database changes happen every day.
More than half (57%) of code changes end up requiring an accompanying database change. Waiting weeks for a DBA team to approve and adjust your code significantly slows your developers’ productivity.
Genuine fear around schema changes
For smaller organizations without a dedicated team to manage the database, you have the opposite problem: Engineers are well aware of how delicate the database is and are cautious (perhaps overly so) about making any changes. 48% of organizations say their database change process has several steps that can fail.
Chances are, your developers have been stung by downtime or data loss before, but the extra caution around making database changes significantly slows down how quickly you can ship code.
Ongoing monitoring and improvements
Effective organizations have performance and scalability built into their testing processes from the start, but it’s impossible to predict the future. Your team might ship a new feature that loads quickly and works well initially, but that begins to change as the underlying table grows in size and complexity. When your app becomes slow and your users complain, developers start working on rewriting queries, refactoring application code, modifying the schema, and even caching (good luck). Whatever works, it’s yet another task your team is spending time on instead of working on new features.
The way we build, test, and deploy software has changed massively over the past decade, but the way we interact with the database has stayed largely the same.
What if your database made you more productive?
For as long as software engineering has been around, the database has existed outside the scope of DevOps. Our application code is tightly version controlled, reviewed, tested, and deployed, but we still make schema changes manually and hope for the best. The solution is to bring the database into the DevOps cycle and create a dedicated workflow for managing changes.
Here’s what a traditional workflow looks like for making a database change with a DBA team:
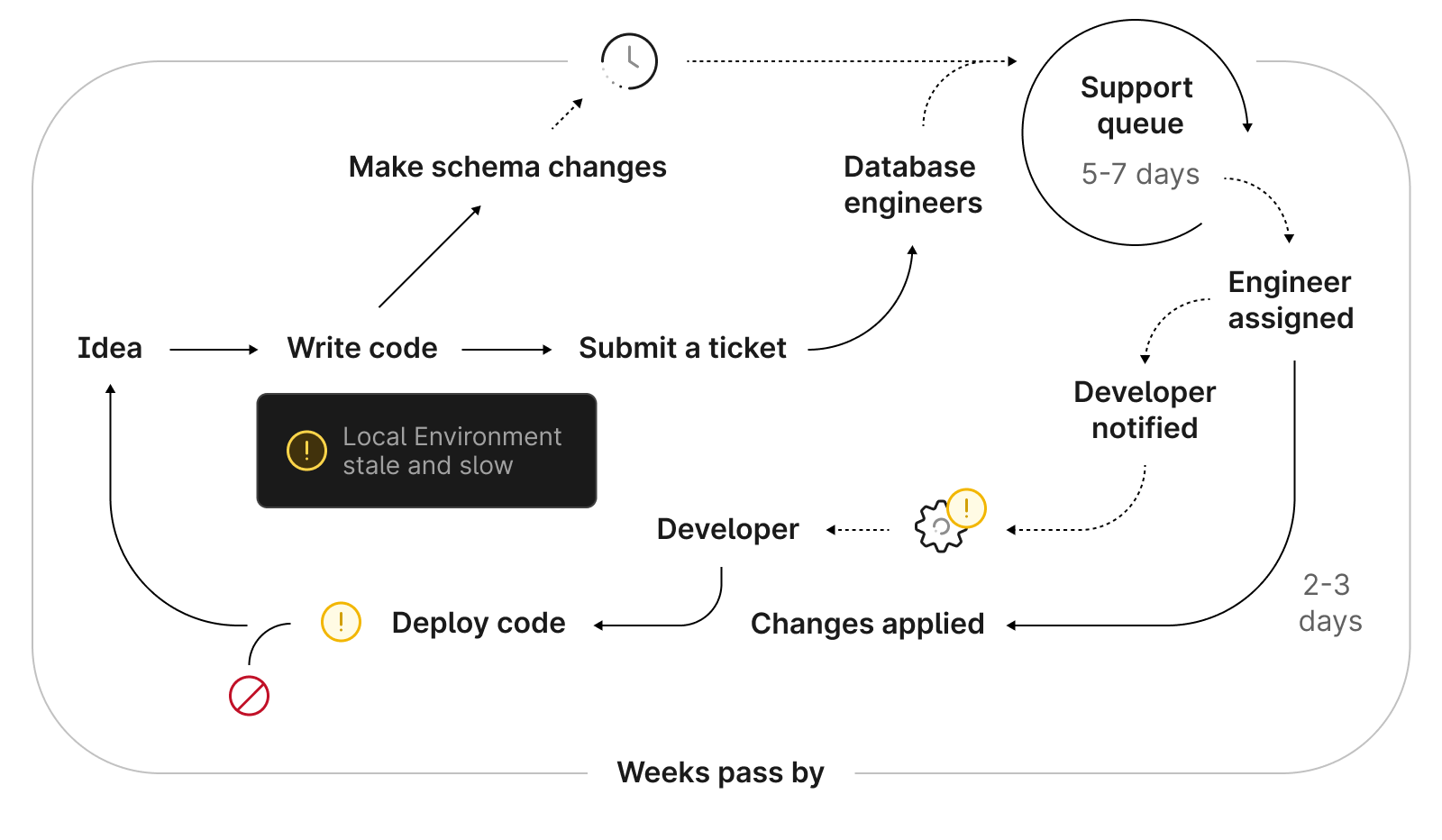
Your workflow to make a schema change starts with a team building a new feature. Most meaningful new features will require a database change. If you have a DBA team, a request gets sent their way to go through their review process. If not, your team does extensive testing before gingerly making the change themselves. If the change goes well, great! If not, you’re faced with the same cycle all over again.
Throughout this entire process, your database itself acts as an almost innocent bystander. We’ve built these clunky, backward change processes around a tool that has stayed roughly the same for the past 20 years, while the way we create and deploy code — and the tools we use to do it — have gotten better by leaps and bounds.
Bringing your database into the DevOps cycle
The database you need has features built in that make change management as simple as a comment and a click, letting you bring it into your DevOps cycle natively. One of the core insights we built PlanetScale on top of is that the databases have been largely untouched by the changes in how we ship software over the past 10 years. It’s time to change that.
Let’s cover a few flagship features that help PlanetScale unlock your developers’ productivity.
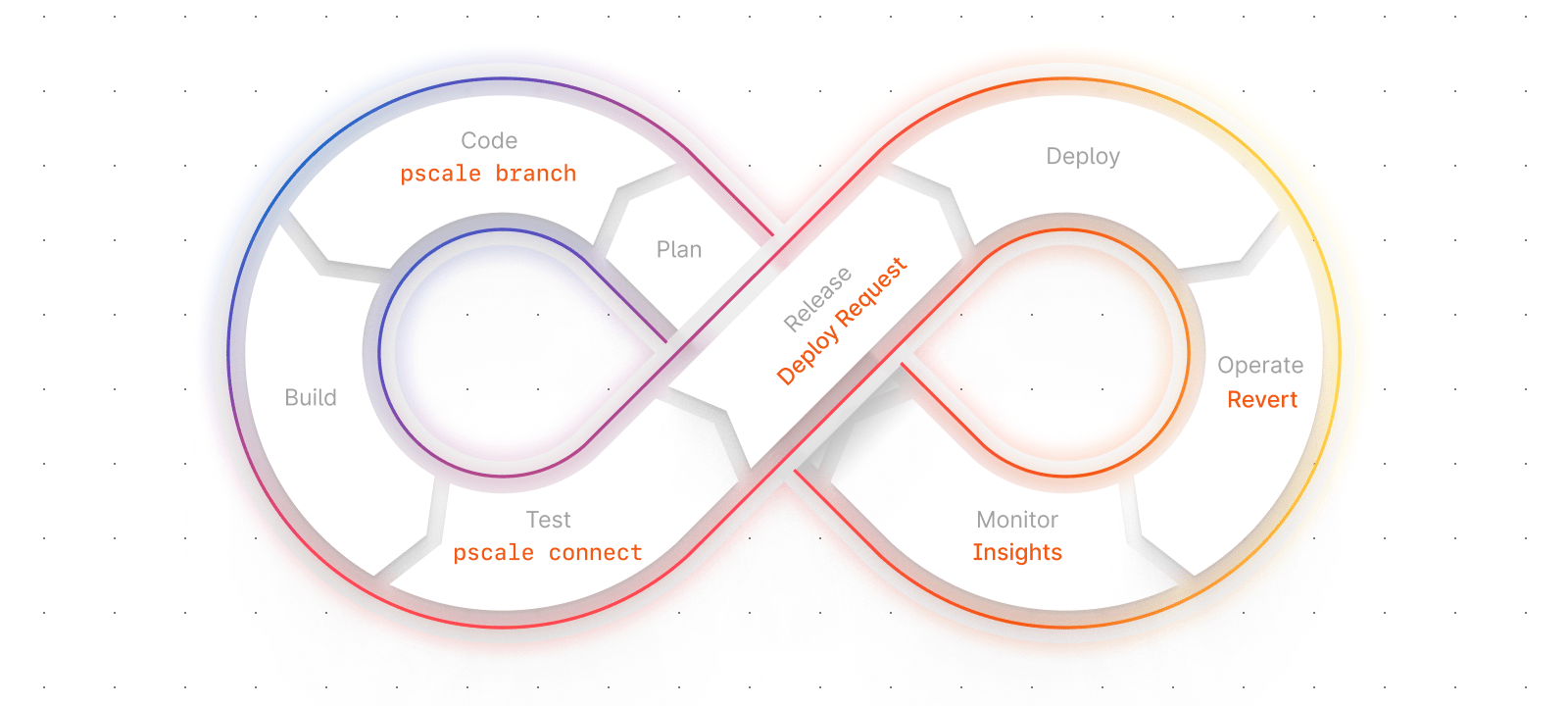
What if your database had branches?
The first thing you do when work starts on a new feature is git checkout -b “new-branch-name” — branching is part and parcel of modern software development and delivery. PlanetScale brings that same functionality to the database, allowing you to create independent, merge-able branches of your data.
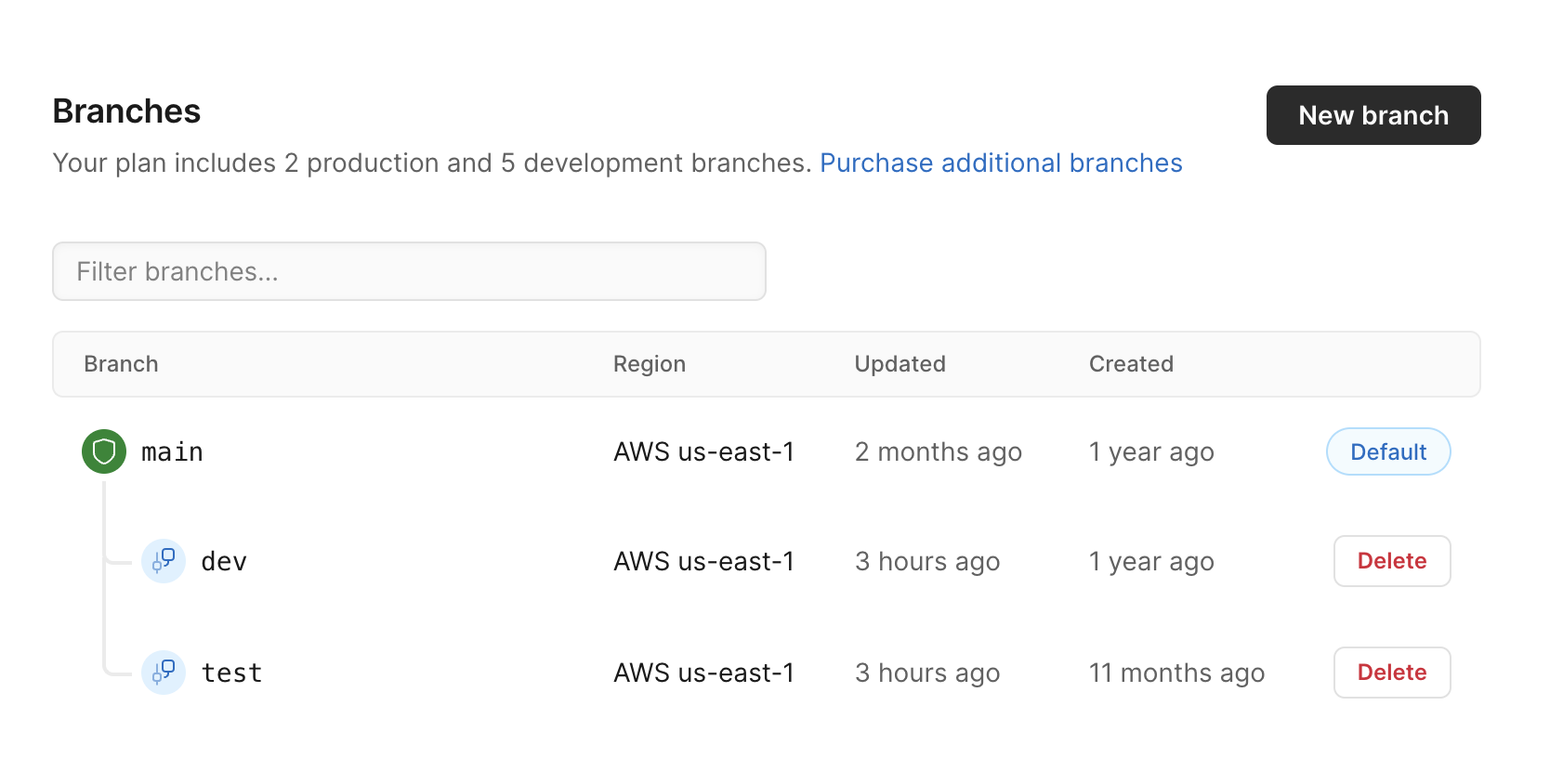
Branches take the guesswork out of schema changes. When you create a branch, an isolated database instance gets initialized (schema only for development) where you can make and test your changes. When you’re ready, you can promote it to main just like you would with code.
Deploy requests and database CI/CD
When your database lives outside your DevOps cycle, changes get made (and reverted) statically and non-collaboratively. PlanetScale’s deploy requests feature brings the database into the cycle by giving your team a singular view of the proposed changes and their impact.
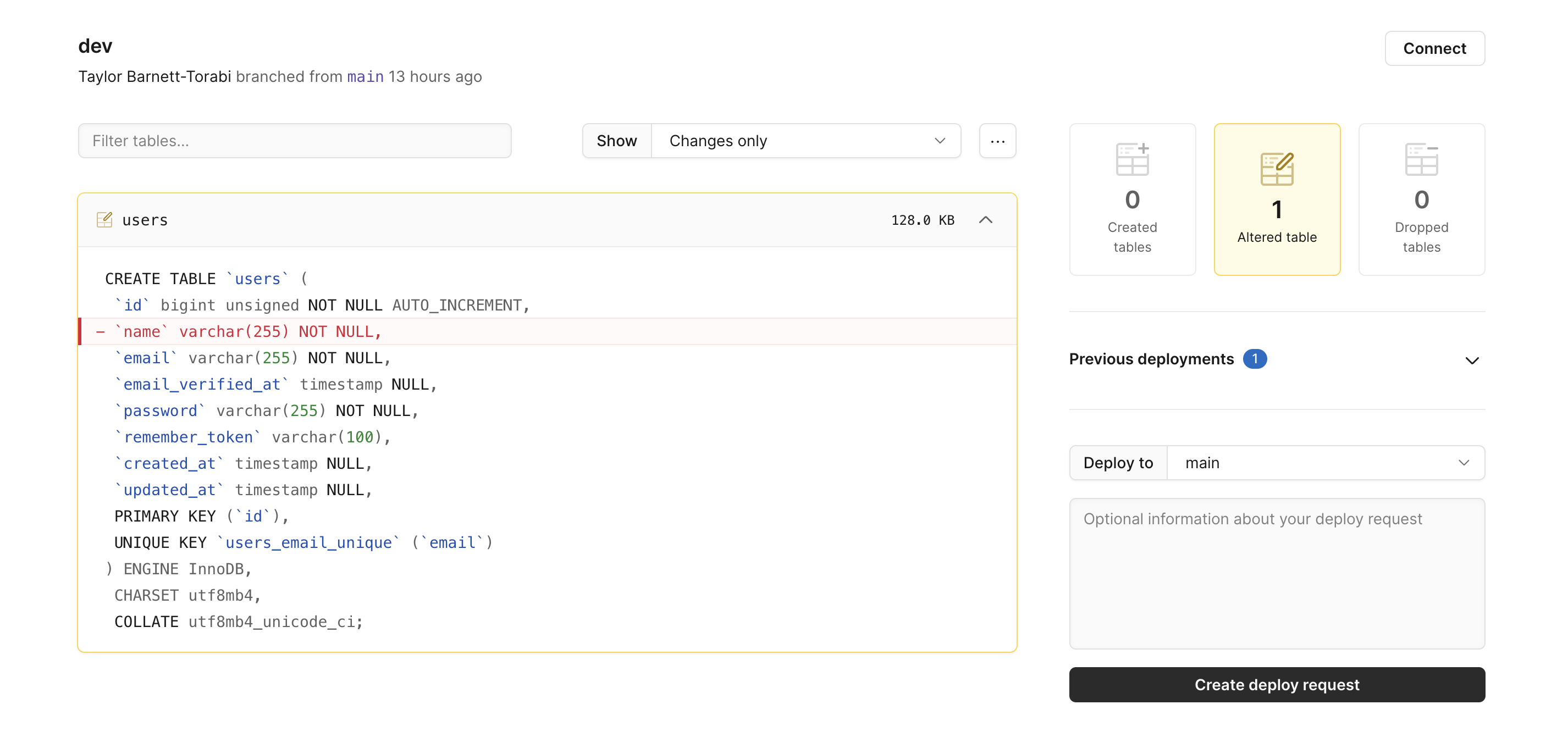
After reviewing your request and the impact it will have on tables, your admin can merge the request and promote it to production (all of which is stored in history, by the way) — just like a Pull Request on GitHub. It’s like a review process for your database, built right in.
Reverting schema changes easily
In a perfect world, development would mirror production identically and schema changes that were tested properly would work every time. In the real world though, no matter how smoothly your database handles changes, you’ll need to revert one every now and then. PlanetScale makes that process criminally easy: You can one-click undo a schema change with no downtime or data loss.
Insights and automated monitoring
So you’ve used branching and deploy requests to seamlessly get your database change into production. The next step is monitoring your changes and making sure that the query you wrote that utilizes the new data is performant, keeping your users happy. PlanetScale Insights gives you a remarkably granular view of query performance, all built-in natively to the database.
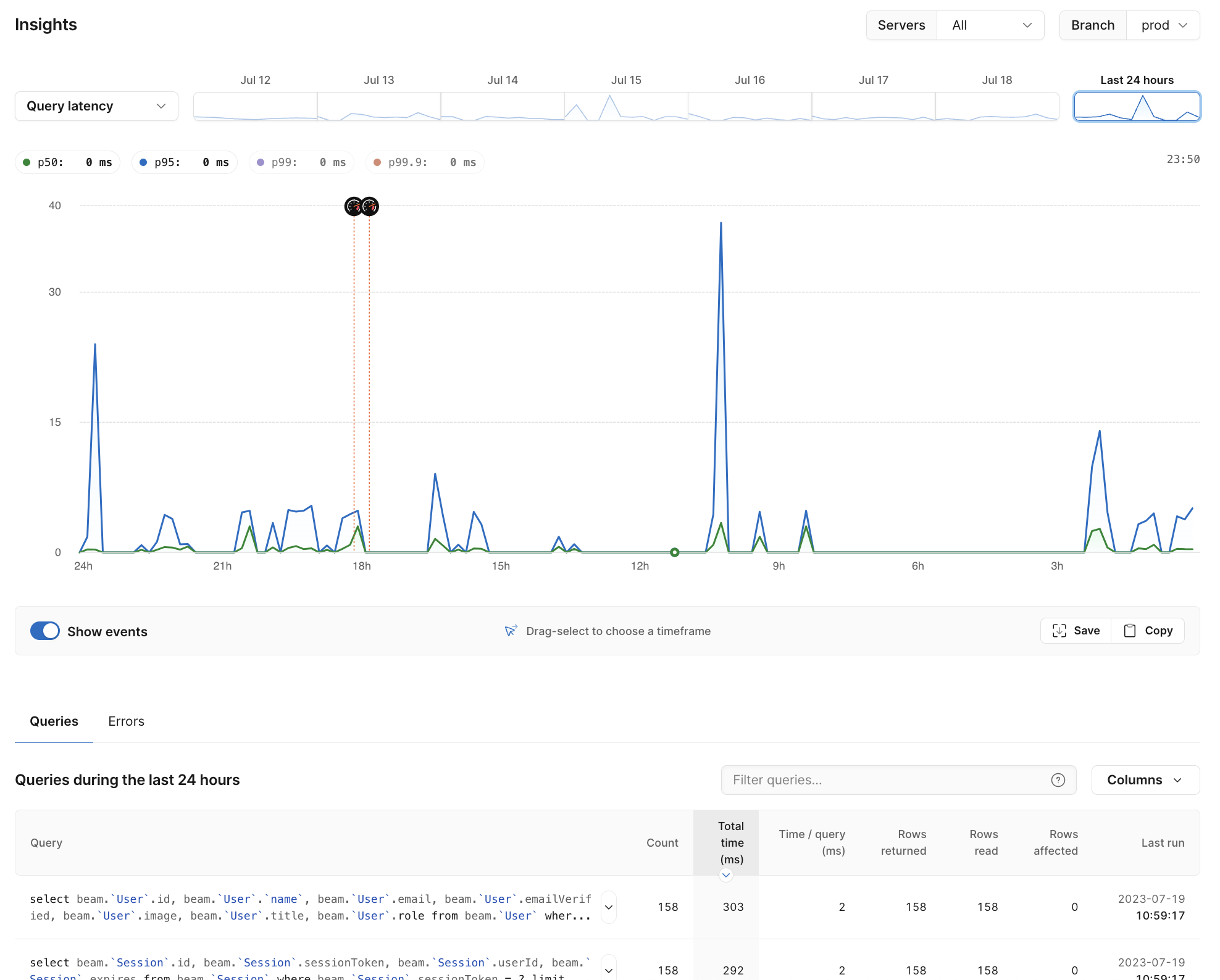
You can choose from metrics like rows read, query latency, number of times a query has run, etc. Seeing your recent queries, how they performed, and any errors they ran into in a single place makes it easy for your developers to quickly analyze and make adjustments on the fly.
Don’t just take our word for it
We built PlanetScale because we were frustrated with the database being the bottleneck for moving customer-facing features forward. Developers at organizations across the globe, from startups to Fortune 500 companies, are using PlanetScale features like branching, deploy requests, and insights to unlock developer productivity and ship things faster.
Planning for massive scale while also rapidly iterating on our feature set was a demanding place to be. PlanetScale delivers world-class operations, a scalable platform, and the flexibility the business needed.
We used to check the AWS dashboard nightly, now we never think about PlanetScale. We don’t want to be DevOps experts and we don’t need DevOps database work. We want to always focus on making our product better.
Having Insights where it captures 100% of queries scratches an itch like nothing else can. You can get the complete picture.