In a perfect world, the complex systems we build would run indefinitely without the risk of downtime. Unfortunately, we don't live in that world, so understanding how to recover from failures is necessary when they inevitably happen.
This article will cover some considerations and best practices to ensure you can quickly and efficiently recover your database when disaster strikes.
High availability vs disaster recovery
High availability (HA) and disaster recovery (DR) are two closely related concepts regarding downtime. HA refers to the practice of designing the system in a way that allows it to survive an outage. For example, suppose a primary database server goes offline in a MySQL cluster with data replicated across three servers. In that case, the system can automatically elect a new primary node and reroute traffic within seconds. While some users may notice a brief interruption, most of the user base remains unaffected. This failover process is a benefit of replication, which we'll touch on in more detail later.
On the other hand, DR focuses on recovering from major outages that may have a broader and longer impact on the business. It involves implementing strategies and procedures to restore the database and its associated services after a catastrophic event. Unlike HA, which aims to minimize downtime and ensure continuous operation, DR is concerned with the overall recovery process and restoring normal business operations as quickly as possible.
By combining HA and DR practices, organizations can build resilient database systems that can withstand minor and major disruptions, ensuring the availability and integrity of the data.
Defining recovery goals
Since no system is perfect and will inevitably go down for some reason or another, it makes sense to account for this ahead of time and set recovery goals for your company regarding outages.
What are Recovery Point Objectives?
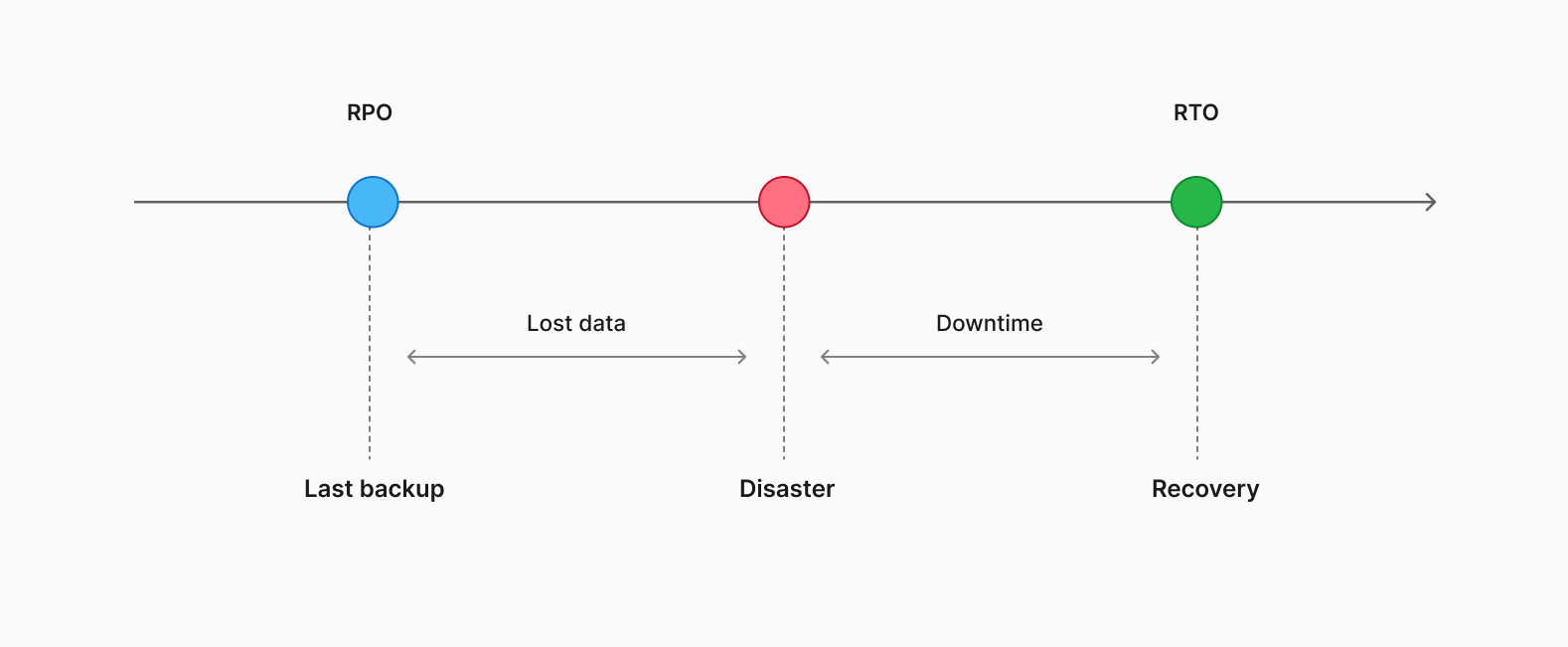
A Recovery Point Objective (RPO) defines the maximum amount of data your business can afford to lose during a disaster. By setting an RPO, you are establishing the expectation that there may be a maximum of N hours, minutes, or seconds of data loss when the systems return online in the event of a catastrophe. It is crucial to align your backup strategy with your RPOs to ensure you do not exceed the acceptable data loss.
For example, if you have daily backups configured for your database and an RPO measured in hours, you may miss your target RPO if the last backup is 23 hours old. Therefore, it is essential to carefully consider your backup frequency and retention policies to meet your RPO requirements effectively.
What are Recovery Time Objectives?
Recovery Time Objectives (RTOs) represent the targeted duration within which a specific outage should be resolved. A shorter RTO implies a more rapid response from your team to restore systems to full functionality. Often measured in hours or minutes, RTOs serve as a crucial metric for evaluating your DR plan's effectiveness and setting expectations for members of the organization.
These targets are those goals that can be set so your teams are on the same page when it comes to disaster recovery. They should be as small as realistically possible, but the keyword in that statement is “realistically.” It's important to understand that the smaller the RPO and RTO, the more complex and expensive the disaster recovery solution. It's a balancing act between the cost of the solution and downtime.
Databases are stateful, and code is not
Statefulness refers to a condition where the usage and functionality of a system depend directly on the previous actions taken on that system. Code is stateless, meaning that the processes that run the code don't necessarily rely on any specific underlying data to run. So, if your web application server hits a snag and goes offline, you can smoothly switch to another server, reroute the traffic, and get back to business as usual.
Now, databases operate differently. They're stateful because the data within the database results from the many transactions issued against the database from the time it was first built. If the server hosting your MySQL database crashes, you can't just swap it with a fresh MySQL server. Your application may come back online, but it's useless if your users lose all their data. The statefulness of the system is why handling database disasters requires careful planning and attention, a step up from the more agile nature of fixing application issues.
MySQL functionality used for disaster recovery
MySQL replication
Replication allows your data to replicate across multiple MySQL servers. It is crucial not only for keeping your database highly available but also for handling disasters. If your primary database location has issues, having a replicated copy in another availability zone or region lets you get things back up and running quickly. In a typical setup, one server accepts both read and write workloads (the primary or source), and the others (replicas) are for read-only workloads.
MySQL gives you two replication modes: asynchronous and semi-synchronous. In the default semi-synchronous mode, the primary server commits transactions and waits for at least one replica to confirm it got the message. On the other hand, asynchronous mode has the primary node committing the transaction and responding to the client immediately without waiting for replicas.
Semi-synchronous mode works well in low-latency situations, like servers in the same region, while asynchronous mode is better for longer distances. Using asynchronous replication over distances might mean the data in the remote region is a bit behind since network traffic is slower to respond, and the primary does not wait for those replicas to acknowledge that they've seen the transaction.
Still, it's usually a fair tradeoff, as waiting for the primary region to come online may not be the most practical option. This fact is especially true when you consider the RTOs and RPOs we discussed earlier and the fact that the data in the remote region is still available, even if it's not the most recent.
Note
To learn more about MySQL replication, check out our blog post, where we dive into the details of replication and the best practices for setting it up.
Database backups
A robust backup strategy is crucial for effective disaster recovery. There are two types of backups: logical and physical. Logical backups consist of SQL statements that can recreate the database from scratch, while physical backups are copies of the actual files stored on disk. In either case, both types represent the database at a specific point in time.
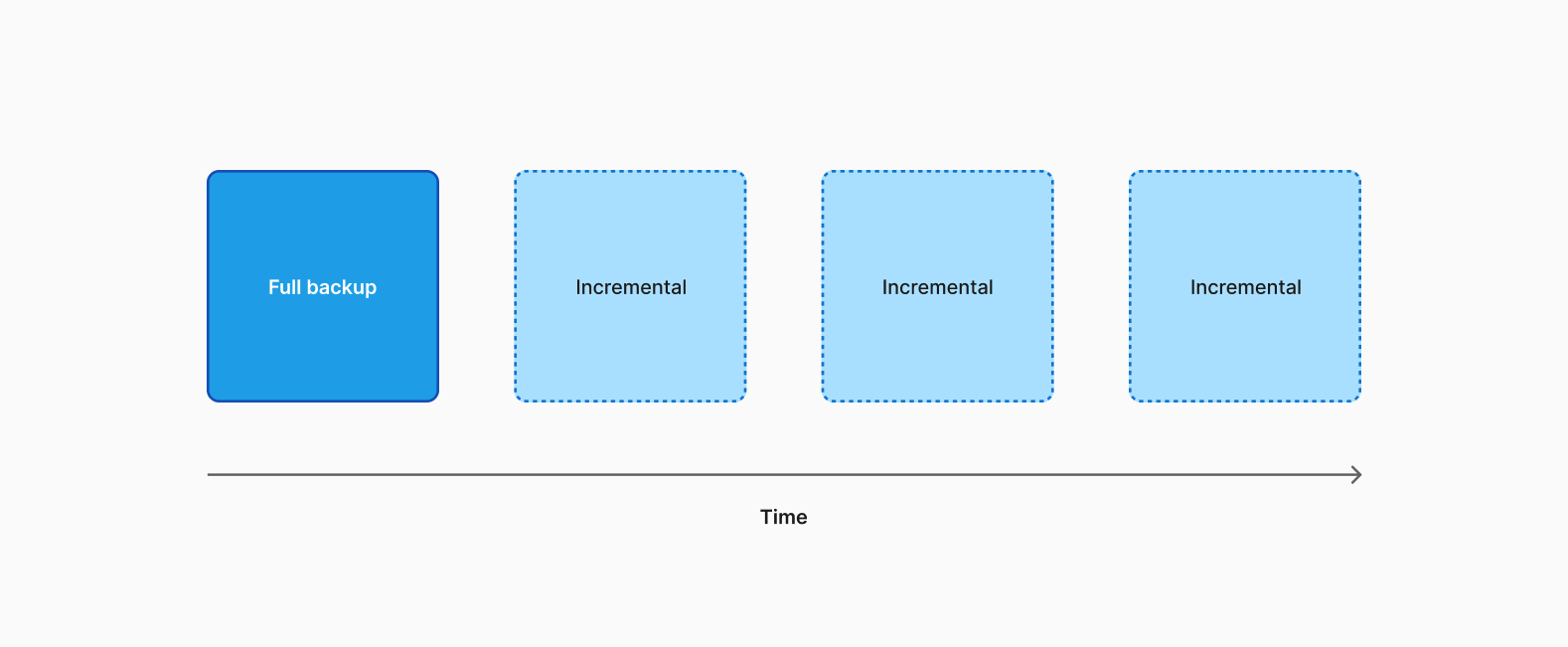
You'll also have to consider when to take full backups instead of incremental backups and when each is appropriate. Full backups, as the name suggests, are complete representations of the database from when the backup was taken. In contrast, incremental backups represent the changes to the database that have occurred between two points in time. Incremental backups use the binary log for their backups, and they need to be restored in the order they were taken to get a complete version of the database.
The backup process can be resource-intensive and impact the server it is being performed on, which can negatively affect the responsiveness of the application using the database. This impact is greater for larger databases as they take longer to back up. Since replication allows you to create replicas, they are perfectly suited to handle read-only workloads. Backups are often performed on replicas to reduce the load on the primary server.
At PlanetScale, we use read-only replicas to perform backups of our database, but we go a step further and restore the most recent backup of a database to a backup-dedicated replica before allowing replication to catch it up and take another backup. This process has the added benefit of validating backups on our system to ensure our customers have a reliable backup to restore from in the event of a disaster.
Building a database disaster recovery plan
No disaster recovery plan looks the same between businesses, so here are a few things to remember when building a plan for yours.
Define your RPOs and RTOs
As we discussed earlier, defining your RPOs and RTOs is important. Doing this will help you understand what you need to do to meet these targets and the cost of doing so. This part of the process should be done in conjunction with business leadership, as they will need to understand the cost of downtime. Having other key members of the organization involved in this process will also help ensure that everyone is on the same page regarding disaster recovery, which reduces the friction between teams due to the outage.
Use cross-region replication to speed up recovery
Rerouting traffic to a live database server in a different region will always be quicker than restoring your entire database from a backup. There's also a pretty good chance that the data loss incurred from replication lag (the delay between when the primary writes traffic and replicas write it) will be less than the data loss from having to restore a full backup that is several hours old or even an incremental backup that could be a few minutes old.
Prioritize what needs to be restored
Not all infrastructure or applications are created equal. Some systems are more important than others, including their associated databases. Defining what parts of your infrastructure are most or least important can help you understand what needs to be restored first and what can wait. Categorizing your infrastructure will help you prioritize your recovery efforts and ensure that the most important systems are back online as quickly as possible. You might even spin out separate RTOs and RPOs for different systems based on their importance to the business.
Use loss of revenue as a metric
The systems built for businesses ultimately do one of two things: save money or make money. When building your disaster recovery plan, it's important to understand the cost of downtime in terms of lost revenue. This metric should be used when defining your RPOs and RTOs and helping prioritize which systems would cost the business the most and, therefore, need to be restored quickly. If you're in the beginning stages of building a plan, using revenue loss will also help you to make a more compelling case for the resources you need to build a robust disaster recovery plan.
Automate your recovery process
Humans make mistakes, more so even when they are under pressure to recover critical business systems. It's important to minimize the possibility of human error when it comes to disaster recovery. Automating your recovery process can help ensure that the process is repeatable and can be done quickly and efficiently. This will also help to ensure that the process is done the same way every time and that it can be performed by anyone on your team, not just the most experienced members.
Test the plan regularly
The best way to ensure that your disaster recovery plan works is to test it regularly. Testing consistently will help you to understand how long it takes to recover your systems and what the impact of that recovery is on the business. It will also help you understand if your RPOs and RTOs are realistic and if they can be met with your resources. Regular testing will also help you understand if the plan needs to be updated and if any new systems need to be included in the plan.
Validating backups is also a critical aspect of a disaster recovery strategy. It is not enough for backup software to report successful backups. After all, backups are only as good as their ability to be recovered. Corrupted or misconfigured backups can lead to devastating consequences during a crisis, which can ultimately ruin a business.
By automating and regularly testing your recovery process, you can also be confident that your backups can be restored when they are needed most. Amazon calls these events "game days" where a failure is simulated to test the recovery process.
Conclusion
Disaster recovery is a crucial aspect of database management, and it is important to have a plan in place to ensure that your business can recover from an outage. Having a plan that is communicated across the organization and can be easily executed can significantly impact the downtime your business may incur whenever a disaster inevitably hits.