Today, PlanetScale announced support for foreign key constraints.
This has been in the making for quite a while — around a year in fact. So, what was the problem? Why did it take so long? It's something that any and every database supports, right? Yes and no. To support foreign key constraints is one thing. To do so while still delivering Online DDL, gated deployments, online imports, and eventually cross shard support, is another.
When we launched PlanetScale, we refrained from supporting foreign key constraints, first and foremost because we could not make them work with branching and Online DDL. It was a realization that came while we were building the product, and we took it as a fact of life, something we’d have to work around. Around a year ago, we decided to really dive in to see what it would actually take to support them.
It turns out, we had to overcome challenges in almost every single layer of the product: some due to MySQL limitations, some due to how we want to incorporate foreign key support with PlanetScale’s (through Vitess) Online DDL, and some due to branching and schema analysis logic. As you will see in this post, these are all closely intertwined.
Branching and Deploy requests
The first challenge we had to deal with was handling branching and deploy requests. With PlanetScale branching, the user works in a development environment where they’re free to make schema changes. Once they’re ready to deploy those changes, they submit a Deploy request, which lets them review the schema changes they’ve made before deploying them to production.
The Deploy request page shows the user the semantic diff between the main (base) branch and their own (head) branch. PlanetScale uses three-way merge to determine the diffs.
Supporting the foreign key constraint schema definitions is relatively simple, and is but a matter of understanding the SQL syntax involved. However, the semantic analysis is much more involved. Consider that in MySQL (or in InnoDB, rather, as we will discuss later on), the following rules must apply for any foreign key constraint definition:
- A foreign key constraint is a relationship between a parent table and a child table. As a special case, a table may reference itself as its parent.
- The referenced (parent) table must exist.
- The foreign key reference columns in the parent table must exist.
- The referenced columns in the parent must be indexed in-order. There has to be an index covering the referenced columns in the same order they’re referenced by the constraint. Optionally, the index may proceed to cover more columns.
- The child’s columns must match the referenced parent columns in count and in data type. An
INTcolumn on the child may not reference aBIGINTcolumn on the parent. Interestingly, it’s okay forVARCHAR(32)vsVARCHAR(64)in child and parent.
These rules are strongly enforced by the MySQL server (assuming FOREIGN_KEY_CHECKS=1; things get less consistent when FOREIGN_KEY_CHECKS=0), which means that by the time the user submits their Deploy request, it should be safe to assume that the branch adheres to those rules. However, when PlanetScale evaluates a Deploy request, it not only computes the diff between branches, but also the path towards converting one branch (base) into another (head). That path is a valid sequence of steps which maintain the schema in a valid state at all times. Moreover, it evaluates whether, and how, these steps may be deployed all at once.
Foreign key constraints introduce a new complexity to that evaluation. In the simplest form, they may require a specific order of deployment. As a trivial example, suppose we were to create a parent-child pair of tables, such as these (simplified):
create table parent (id int primary key);
create table child (id int primary key, parent_id int, constraint parent_id_fk foreign key (parent_id) references parent (id));
The deployment plan must of course first apply the creation of parent, and then the creation of child. The reverse order is invalid because child must reference an existing parent table.
Some changes are eligible to run concurrently. Suppose we have the following:
create table t1 (id int primary key, ref int, key ref_idx (ref));
create table t2 (id int primary key, ref int, key ref_idx (ref));
create table t3 (id int primary key, ref int, key ref_idx (ref));
And, suppose we add foreign key constraints onto t2 and t3, such that the diff evaluates to:
ALTER TABLE `t2` ADD CONSTRAINT `t2_ref_fk` FOREIGN KEY (`ref`) REFERENCES `t1` (`id`) ON DELETE NO ACTION;
ALTER TABLE `t3` ADD CONSTRAINT `t3_ref_fk` FOREIGN KEY (`ref`) REFERENCES `t2` (`id`) ON DELETE NO ACTION;
The two diffs may run concurrently, even though they both affect table t2 (one directly, and one indirectly). More on why this is at all possible when we discuss Online DDL.
Even more complex is a scenario where two migrations cannot execute concurrently. Assume the base schema looks like this:
create table t1 (id int primary key, info int not null);
create table t2 (id int primary key, ts timestamp);
And that our branch schema is:
create table t1 (id int primary key, info int not null, p int, key p_idx (p));
create table t2 (id int primary key, ts timestamp, t1_p int, foreign key (t1_p) references t1 (p) on delete no action);
The diffs are:
ALTER TABLE `t1` ADD COLUMN `p` int, ADD INDEX `p_idx` (`p`);
ALTER TABLE `t2` ADD COLUMN `t1_p` int, ADD INDEX `t1_p` (`t1_p`), ADD CONSTRAINT `t2_ibfk_1` FOREIGN KEY (`t1_p`) REFERENCES `t1` (`p`) ON DELETE NO ACTION;
However, it is impossible to even begin the migration on t2 before the migration on t1 is fully complete. That’s because MySQL strictly requires an index to exist on the parent table’s referenced columns. Assuming the parent table is already populated, we’re looking at a potentially significant time running the first migration before we can begin the second.
Last, and of course this is not strictly limited to foreign key constraints, you can go too far with your branch changes. PlanetScale attempts to reduce the diff to a single change per table/view. If a branch differs so much from base that it takes multiple steps to operate on the same table to get it into base, then the Deploy request is not deployable.
Courtesy of schemadiff, this is all evaluated in-memory at the time a Deploy request is created.
Handling reverts
Within branching, we also had to deal with handling reverts. PlanetScale’s deployments are revertible. If you deploy a schema change, and then realize you made a mistake, we offer you the option to revert that migration while still keeping all the data that may have changed during and after the deployment.
There exist some scenarios where reverts are not possible. For example, if you modify a column from TINYINT to INT, complete the deployment, and populate some row with the value of 256, then that value is outside TINYINT range, and the change cannot propagate back to the original table.
Foreign key constraints create a different limitation. Let’s illustrate with a simple example. Say you have parent and child with foreign key relationship. You choose to drop the child table, meaning there’s now no foreign key constraint. You then proceed to DELETE FROM parent. You then wish to revert dropping child. This is possible, but it creates an inconvenient situation: the restored child table will have orphaned rows, for we have deleted all rows from parent.
The same logic applies to any destruction or editing of a constraint. You can’t trust that the reverted table complies with the constraint, for you may have modified the data in an incompatible way while the constraint was removed.
PlanetScale will allow you to make such reverts, but we will warn you that the change may not be revertible. The schema will be fine, but orphaned rows are possible.
Query serving
The next challenge we dealt with was query serving. At this time, foreign key constraint support is limited to unsharded/single shard databases. We expect to support shard-scoped foreign key constraints in a multi-shard environment, or even cross-shard foreign keys, but we limit the current discussion to a single shard. This means that a query that uses a table that’s in a foreign key relationship will only operate on a single backend database server.
Vitess, the underlying engine behind PlanetScale, normally optimizes execution of such queries by delegating them to the backend MySQL server. However, a MySQL limitation that affects other critical components of Vitess calls for a different course of action. To understand why, let’s digress and discuss Online DDL. We will then return to complete the query serving story.
Online DDL
Perhaps the largest challenge so far has been with Online DDL. PlanetScale offers non-blocking schema changes, which are very compelling, especially when altering large tables in production. The way they work is depicted in detail in our Online schema change tools documentation, but, in short, altering a table works as follows:
- We create a new, empty table, termed the "shadow" table, with the same definition as the original table.
- We apply the
ALTERstatement to the shadow table. - We copy over all existing data from the original table to the shadow table, taking into consideration the schema difference between the two.
- We follow the changelog on the original table, to capture any ongoing changes, and apply them on the shadow table.
- Finally, when we are satisfied the shadow table is in sync or almost in-sync with the original table, we take a lock to prevent writes to the original table, apply what remaining changelog there may be, and finalize the operation by swapping the two tables. The shadow table takes the original table’s place, and the original table becomes the shadow.
This technique, used by several tools for online schema changes, cannot work with the existing MySQL foreign key constraints implementation. Online DDL has issues with:
- Tailing the binary logs for child table with a cascading (
SET NULLorCASCADE) action. - Finalizing a foreign key parent table, as children’s foreign key constraints migrate with the old table as it is being swapped.
- Backfilling the shadow of a foreign key child table, where as a copy of the child table’s schema, the shadow table itself has a foreign key referencing the same parent.
Each of these limitations calls for a bespoke solution. Let’s break it down.
Tailing the changelog
To backfill the shadow table, Online DDL uses VReplication, one of the most powerful components in Vitess. VReplication is the component behind online imports, materialization, live resharding, Online DDL, and more. It can live stream data from a source (or from multiple sources) to a target (or to multiple targets), while possibly manipulating or aggregating the data in transit.
VReplication works by both reading the existing data on the source table(s), as well as by following the changelog: the live, ongoing manipulation of data. The changelog is available in MySQL as the binary logs. VReplication subscribes as a replica and pulls binary log changes from the source server. This is where a major MySQL limitation hits.
MySQL foreign key constraint support
To the casual MySQL user, MySQL is known to support foreign key constraints. However, this is nuanced. MySQL has a pluggable storage engine architecture. Historically, the company MySQL AB focused on non-transactional storage engines. The MySQL engines did not support foreign key constraints. It was a 3rd party pluggable engine named InnoDB that fast became the engine of choice to most users, offering transactional (MVCC) support, as well as foreign key constraint support. There was some period in time when MySQL began work towards implementing foreign key constraints at the server level, but given how MySQL adopted InnoDB as its primary storage engine (now both under Oracle’s ownership), that effort was dropped.
The most important implication, for our discussion, of MySQL not supporting foreign keys at the server level, is this: any cascading of operations (say an ON DELETE SET NULL or ON UPDATE CASCADE) is only done by InnoDB. If you DELETE or UPDATE a row on a parent table, and that, in turn, affects rows in a child table, those changes to the child are done internally in InnoDB, and are never logged to the binary log.
Those changes are hidden from anyone consuming the binary log. MySQL trusts the replica server’s InnoDB engine to correctly replay those cascaded writes for it to remain consistent with the primary server.
Any Change Data Capture (CDC) tool, that tails the binary log or masquerades as a replica, will be missing data when reading a child table’s events when the child table has SET NULL or CASCADE foreign key actions. You cannot reliably replay events on those tables, and you will end up with corrupt data, or trying to apply an impossible statement. By way of experiment (not on your production environment), try removing the foreign key constraints on a replica server, then see how long it takes for replication to break.
For Online DDL, this means we cannot apply a change to a table that has a CONSTRAINT ... FOREIGN KEY ON [DELETE|UPDATE] [SET NULL|CASCADE].
One way of solving this issue would be to make InnoDB log cascaded statements. PlanetScale maintains a fork of MySQL, and we looked into making these changes in MySQL. However, we ended up choosing to implement foreign key constraint logic in Vitess itself. It’s a trade off, with these considerations:
- The InnoDB codebase is very much detached from the MySQL codebase. There are parallel constructs, parallel entities in MySQL and in InnoDB, which are completely different and do not translate well to one another. Making the necessary changes appears to be a substantial undertaking with high risks.
- Adding the necessary logic to Vitess was also a substantial amount of work. However, our Vitess maintainers are authoritative on the topic and had clarity of the scope of work. The risk was low.
- In the future, we would like to be able to support foreign key constraints in a multi-shard environment. No matter how well we patch MySQL, and even if did provide the necessary cascading changelog, foreign keys would always remain an in-server constraint. There is some technology for running cross-server queries via connectors, but it is subpar (or incapable) in its ability to collaborate inside transactions, or in its ability to apply the correct locking. By implementing foreign key logic in Vitess early on, we pave the way towards multi-shard environments in the future.
- It should come as no surprise that there is a downside to implementing foreign key constraint logic in the Vitess level. It requires more locking and more communication with the MySQL server. Vitess optimizes where it can and delegates some queries directly to the underlying server where possible, but there is a non-zero performance impact to using foreign key constraints with Vitess/PlanetScale.
How Vitess implements foreign key logic is described later on, when we revisit Query serving. In the meantime, let’s proceed to discuss the next Online DDL limitation.
Altering a parent table
Described in more detail in this blog post, if you have a foreign key pair of a parent and a child, and you RENAME TABLE parent TO old_parent, the child’s foreign key constraint follows the parent table onto its new name, old_parent. In the internal InnoDB implementation, the parent table retains its memory address, and, in a way, "following the parent to its new name" really means nothing changes in the children’s foreign key references, as they keep using the same pointers. It’s mostly the external facing schema definition that changes to reflect a FOREIGN KEY (...) REFERENCED old_parent (...).
Running Online DDL on a parent table, we want to swap the parent table and its shadow. We want the children to be oblivious to the swap. We want them to point to the parent table name. Of course, we need to take it upon ourselves to ensure the replacement table, the shadow table, is compatible with the existing foreign keys. Imagine swapping in a shadow table that doesn’t have the expected referenced column(s)!
In this patch to MySQL, we introduce a new server variable, rename_table_preserve_foreign_key. When set to 1, a RENAME TABLE preserves the foreign key definition on the children by pinning it to the name of the table.
Altering a child table
Suppose we alter a foreign key child table. Say we just modify some column from INT to BIGINT. The foreign keys that exist on the table should be reflected in the shadow table. For the duration of the Online DDL operation, however, the shadow table is incomplete. It it not in sync with the original table, and may be missing rows that exist in the original table, or may contain rows that do not exist anymore in the original table. But if this shadow table has a foreign key constraint pointing to the same parent as the original table’s parent, then that parent is affected by the very existence of the shadow table. It’s possible for a DELETE on the parent to be rejected due to a matching row existing in the shadow table, even if that row does not exist in the actual child table.
When backfilling the shadow table, we may choose to SET FOREIGN_KEY_CHECKS=0, but the application and users of the database will naturally expect to work with FOREIGN_KEY_CHECKS=1.
Moreover, even if we somehow manage to pull through and swap the tables, what happens now with the old child table? It becomes stale, as production traffic keeps changing the new table. But it still keeps the foreign key constraints to the parent. Again, preventing legitimate queries from executing on the parent. If only it were possible to create the shadow table without foreign key constraints, and just add them at the time of the final swap. Alas, in MySQL, foreign key constraint definitions are created in the scope of a child table. To add a foreign key constraint, or to remove a foreign key constraint, is a full table rebuild operation, locking and blocking; the very thing Online DDL was designed to overcome.
In our patch to the MySQL server, we introduced the notion of internal operations tables, something already well established within Vitess. Essentially, we tell MySQL: ignore any foreign key checks for these special tables. Do not try and validate row data. Do not attempt to cascade anything. It’s as if we SET FOREIGN_KEY_CHECKS=0 for specific tables, even while the transaction otherwise applies foreign key logic to other tables.
This way, MySQL/InnoDB completely ignore our shadow table. It can be out of sync, the parent table won’t mind. And as we swap away the original table, MySQL ignores it under its new name. It will not affect production traffic.
Query serving, revisited
Earlier, we discussed the reasoning behind Vitess owning foreign key logic. What does it mean for Vitess to own that logic?
VTGate is the Vitess component that handles all query serving. It is a proxy between an app and the underlying database, which intercepts queries and creates concrete execution plans, sent to the backend databases. For example, in a multi-sharded environment, VTGate analyzes which shard or shards should be queried for a given SELECT and possibly combines results from multiple shards before returning them to the app.
VTGate can make various optimizations based on the fact that it knows the structure of the underlying schema, the sharding scheme, and the production traffic patterns. It can cache, lock, buffer or altogether modify queries. It is now also aware of foreign key constraints and the specific rule actions. We will limit the discussion to unsharded or single-shard (the two look the same to the app) environments.
Starting with the simplest scenario, an ON UPDATE RESTRICT ON DELETE RESTRICT foreign key can be simply handled by the underlying MySQL server, with no additional planning required from VTGate. A RESTRICT (aka NO ACTION) rule means if you’re deleting or updating a parent row, and such an action would invalidate a child’s row, then the action is rejected. There’s no cascading effect: either your query is rejected, or is accepted and only modifies the parent table. Since there’s no cascading effect, we do not need to account for missing entries in the binary logs.
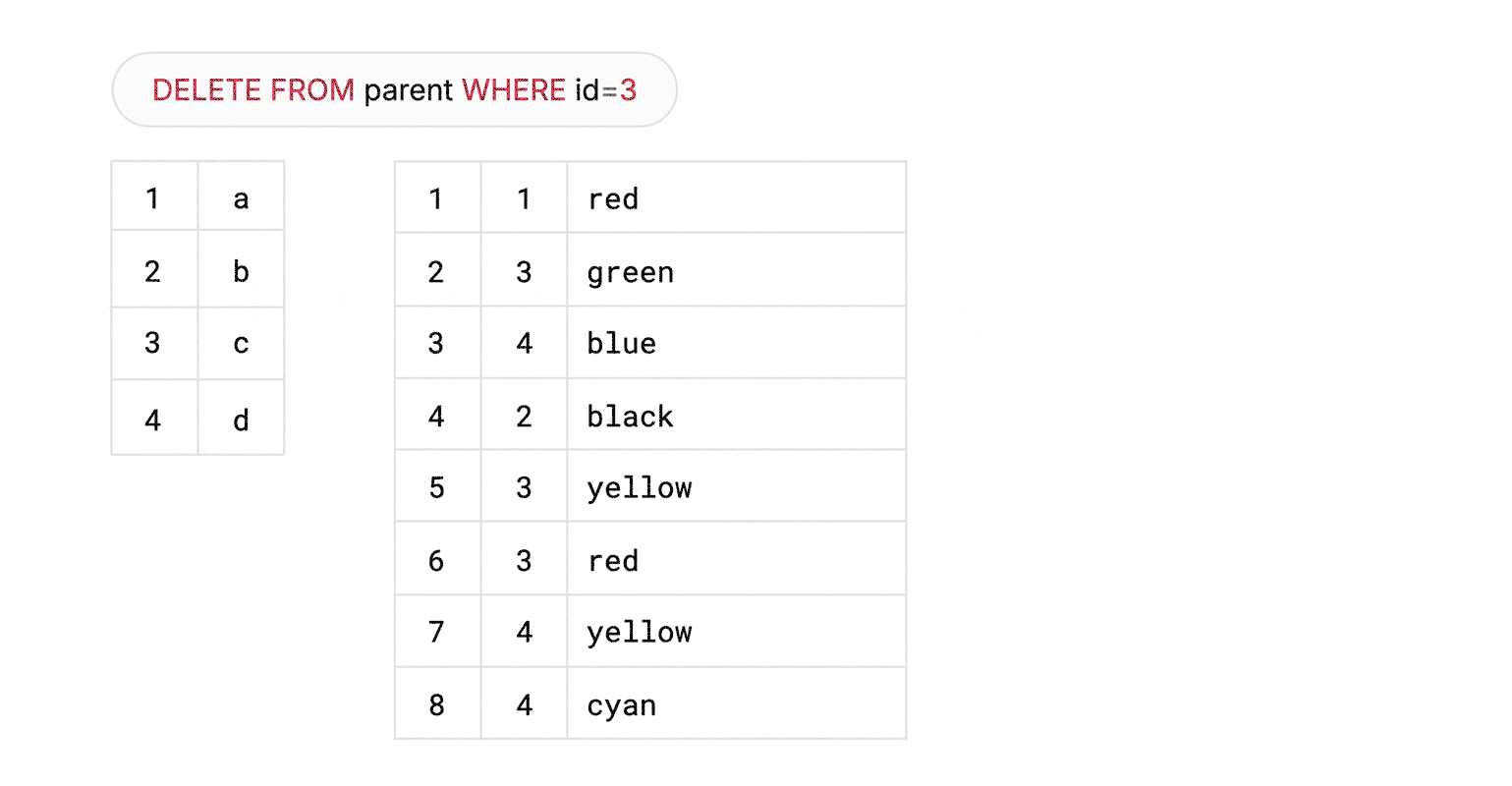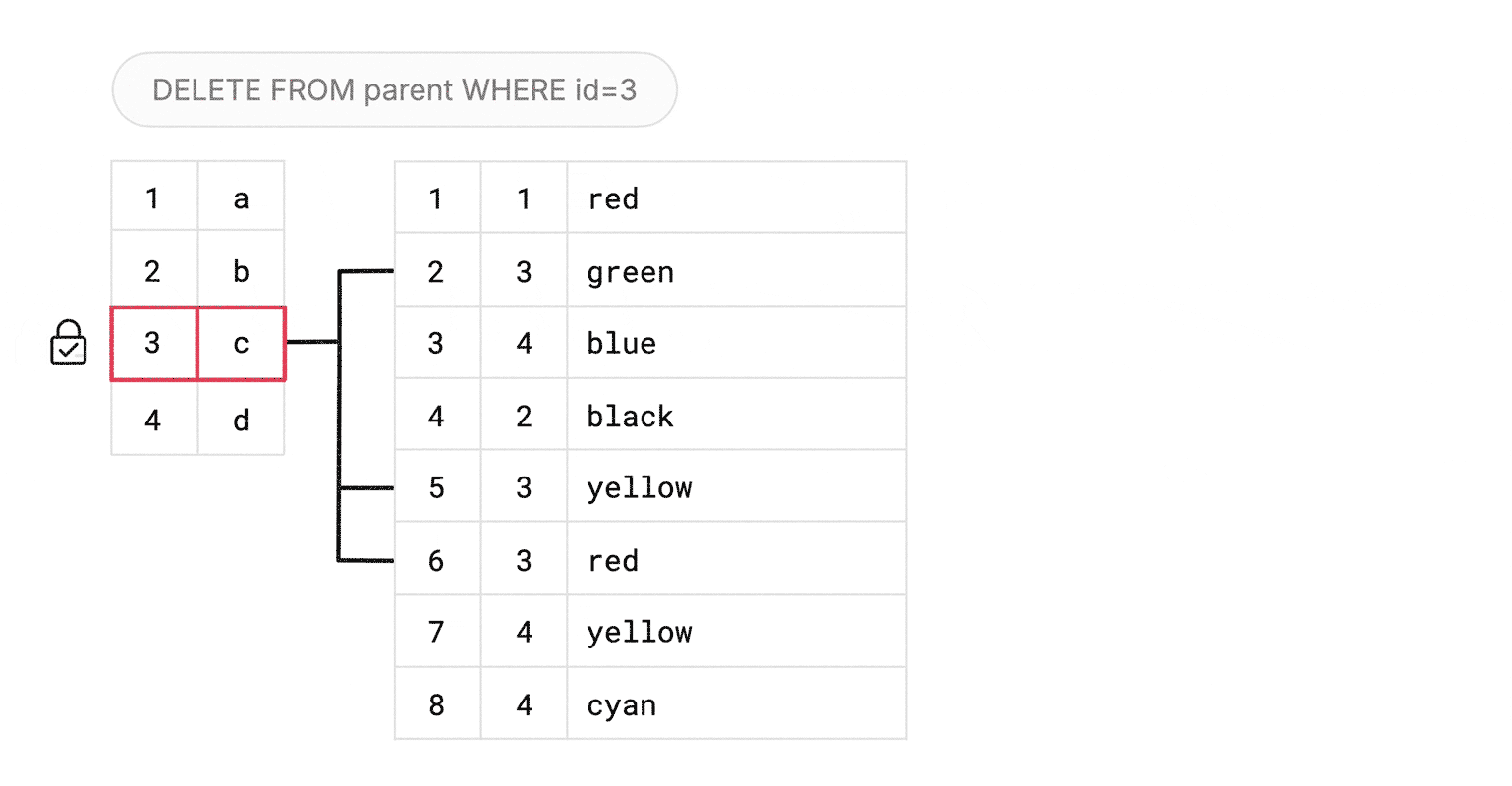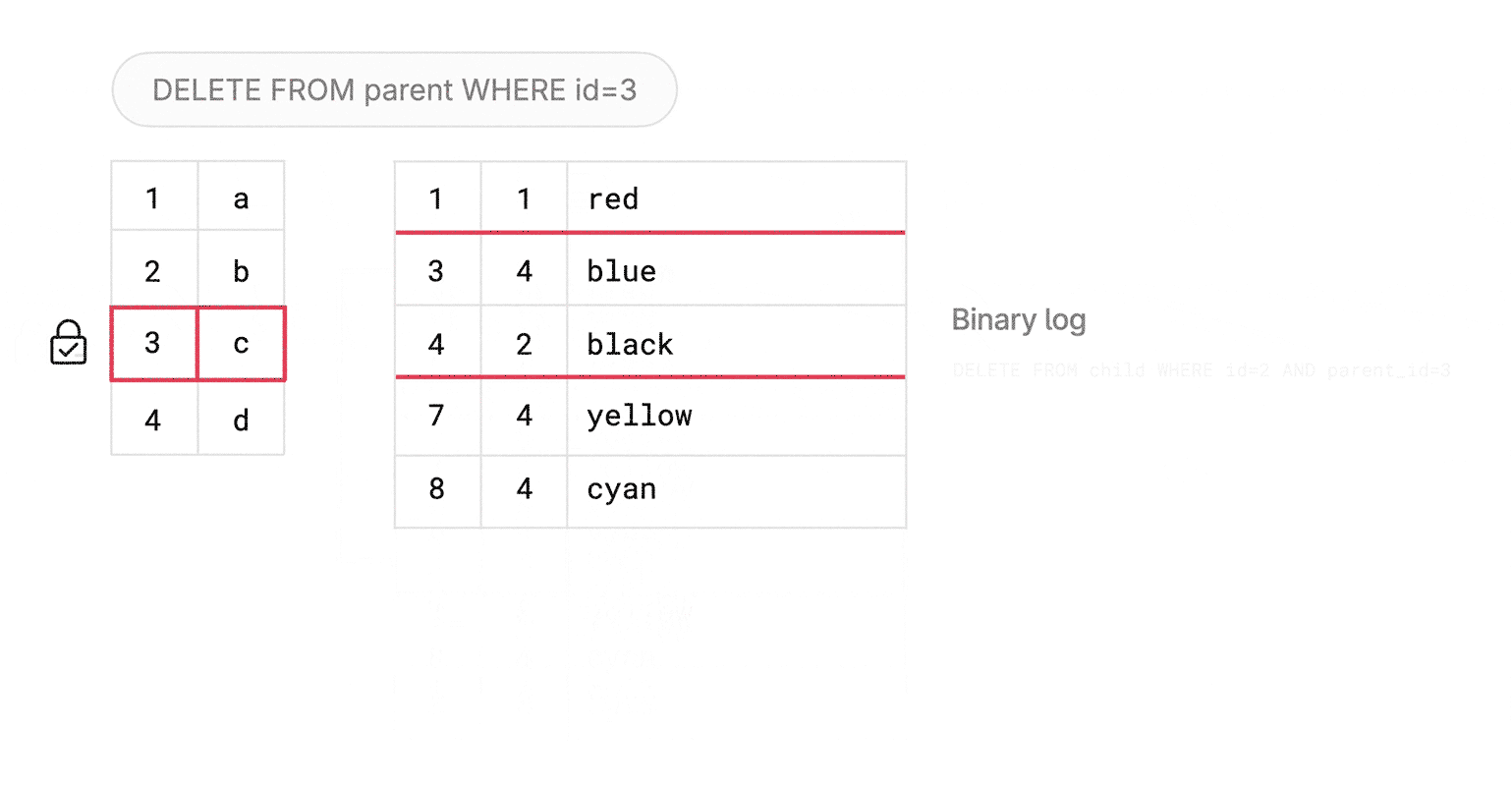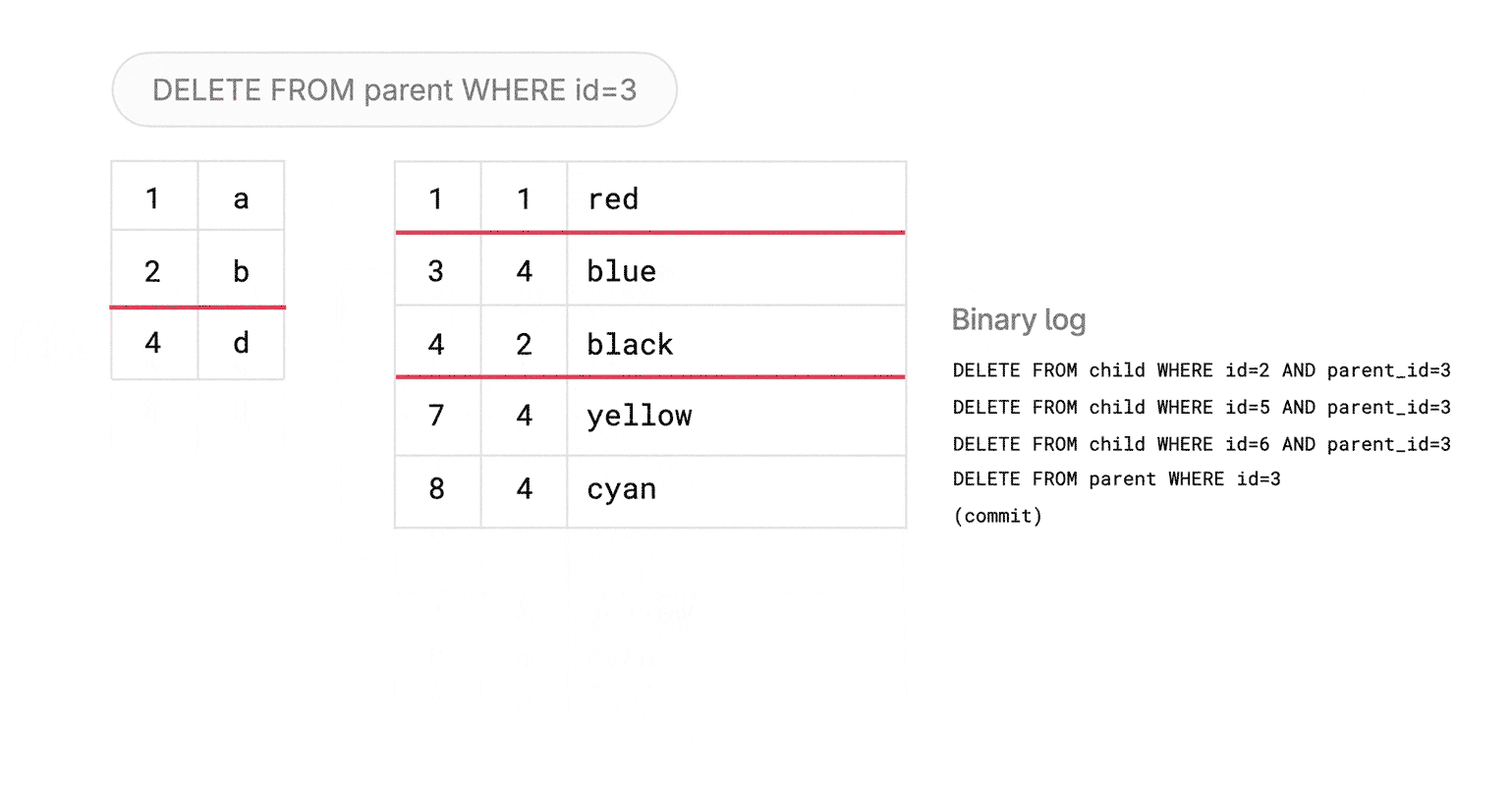
Let’s now illustrate the case for an ON DELETE CASCADE. A user issues a DELETE FROM parent WHERE id=7. There could be entries in a child table with matching parent_id=7. If we ran the query directly in MySQL, it would only apply the DELETE on parent, letting InnoDB take care of deleting whatever matching rows are found on child. But those deletes will not be visible in the binary logs. Vitess, therefore, has to take control.
It must first explicitly DELETE FROM child WHERE parent_id=7 — thereby ensuring that any affected rows are recorded in the binary log — and only then issue a DELETE FROM parent WHERE id=7. When faced with this latter DELETE on parent, InnoDB still checks for matching rows in child, but finds none, because Vitess had already purged them.
At least, that’s the naive outline. The implementation is more complicated:
- The
DELETEs onparentandchildmust be part of the same transaction. The changes made by the statement should be atomic, i.e. all or none are applied. - While we
DELETE FROM child, we must acquire a write lock onparent, specifically for rowid=7. - To do that, we must first issue a
SELECT col FROM parent WHERE id=7 FOR UPDATE. - Using the
foreign key columnvalues from the parent select, execute theDELETE FROM child WHERE col in (parent_column_values). - The child table could itself be a foreign key parent for another table, and let’s say it also has an
ON DELETE CASCADEchild. The same logic is applied recursively: lock the relevant rows onchild,DELETEfrom the grandchild, then delete fromchild, and then back toparent.
As you can see, this implementation introduces more back-and-forth communication between VTGate and the backend MySQL server, as well as having additional locking for correctness.
To show how weird things can get, let’s also illustrate an ON UPDATE CASCADE scenario. Let’s assume we issue a UPDATE parent SET id=8 WHERE id=7. This is a generalized example; as a rule of thumb, one should avoid modifying PRIMARY KEY values, but foreign keys do not necessarily need to refer to PRIMARY KEY columns, or even to UNIQUE values.
Similarly to the DELETE scenario, we want to ensure the cascaded updates appear in the binary log. InnoDB won’t do it for us, so we have to do it ourselves. We want to first issue an UPDATE child SET parent_id=8 WHERE parent_id=7, and only then update the parent table. However, we cannot run that update on child, because there is yet no parent row where id=8!
In this scenario, Vitess must turn off FOREIGN_KEY_CHECKS for the update. This leads Vitess to take responsibility for the integrity of the data, as disabling FOREIGN_KEY_CHECKS leads to MySQL/InnoDB skipping all the foreign key validations for child and parent. Any ON UPDATE RESTRICT for the grandchild or existence of foreign key value in a different parent table needs to be handled by Vitess.
More complex scenarios involve self-referencing tables or statements with non-literal values. They all take a great amount of attention. Later on, we will explain how we test all the above and what gives us confidence that we aren’t missing anything.
Database imports
PlanetScale lets you import your data from an external MySQL environment, and without interruption to that environment. Like Online DDL, Imports utilize VReplication. The external MySQL servers are outside PlanetScale's control, and, of course, will not include any of the changes discussed above. In light of that, how can PlanetScale use VReplication to import a database that has foreign key constraints, specifically with SET NULL or CASCADE actions?
Normally, VReplication moves data from a source (or multiple sources) to a target (or multiple targets) by alternating these two operations:
- Transactionally reading existing rows from the source table(s) and copying them over.
- Tailing the changelog (binary logs) and applying them to capture ongoing changes.
VReplication takes a surgical approach where it keeps track of per-transaction GTID (global transaction IDs, also known as positioning). When it reads existing rows data, it marks the GTID value that applies to the read transaction. That read will take a while on large tables, and during that time, new events will modify the tables. When VReplication switches to applying the changelog, it only evaluates events occurring as of the last read transaction. A third, "fast-forward" smaller phase then glues the next read transaction with the remaining changelog events up to that transaction. VReplication is also able to entirely skip changes to rows that it has not copied yet, by way of reducing unnecessary work.
With cascading foreign key rules, information is lost. VReplication may attempt to import a child table that has, for example, FOREIGN KEY ... ON DELETE CASCADE. As parent rows get deleted, so do matching rows on the child. However, those deletes on the child never make it to the binary logs. VReplication cannot trust that the binary log is complete.
In closer examination, if the DELETE on the parent makes it to the binary log, and is captured by VReplication and replayed on the target server, won’t the InnoDB engine also replay the cascade on the target server? Yes — assuming the relevant row is already in position on the target, but that’s not guaranteed. At any given time, only parts of any certain table will have been copied. You cannot apply the DELETE to row 1000 on the target, if you’ve only copied rows 1..500.
The solution for database Imports is to import the existing table data in a single, large bulk, followed by tailing the changelog. The two do not alternate. For people familiar with MySQL operations, this is not dissimilar to a point-in-time recovery method, where you first restore a full snapshot of the database, followed by applying a long sequence of binary logs. In this approach, all replayed events necessarily operate on existing data. And while there are still no events for some of the child table changes, we can trust the InnoDB engine on the target side to replay them appropriately.
It’s worth noting that Imports is not expected to work in conjunction with other VReplication operations, i.e. we won’t be running, in PlanetScale, an Online DDL on a table that is being imported. This distinction is important because the import process relies on InnoDB to apply cascading changes, which in turn means some changes are missing in the target’s changelog. In the future, and because some of Vitess’ workflows do integrate with each other, we can expect VReplication to apply changes to foreign key tables through the query serving mechanism discussed above.
Testing foreign key constraint support
These changes call for rigorous testing. We use multiple testing techniques, from unit testing to end-to-end (e2e) testing, from planned to unplanned scenarios. Here, we illustrate two specific test suites:
- Application-oriented e2e stress tests with Online DDL.
- Fuzzer stress tests, comparing Vitess to MySQL behavior.
Application stress tests
In this test suite, we create a hierarchical foreign key structure of tables, and emulate an app that writes to those tables. The app keeps tracks of the changes it makes and the response it gets from the (Vitess) database. At the end of the test, we compare the app’s expectations with the actual table data.
That’s just the high level description. The suite also:
- Sets up a variety of foreign key situations, with one parent, two children, and one grandchild table.
- Ensures high concurrency of writes.
- Ensures high contention writes take place on all tables. Changes made by different connections are highly likely to collide and conflict.
- Tests all foreign key rules:
ON DELETE NO ACTION / SET NULL / CASCADEandON UPDATE NO ACTION / SET NULL / CASCADE. Cascading (SET NULLandCASCADE) rules add to the write contention even more. - Runs the stress tests first without, and then with, Online DDL, on each of the hierarchy tables.
- The underlying database cluster uses MySQL replication, with foreign key constraints completely removed on the replica.
Let’s take a look at some deeper impact of this test design.
The four table structure showcases a parent-only table, two child-only tables, one table which is both parent and child, and a multi-child scenario. This hierarchy does not represent all possible variants of foreign key relationships (for example, it does not depict a multi-parent setup, or a self-referencing table), but does have enough variance to cover the MySQL fork changes, as well as the fundamental VTGate logic and locking scenarios. We use a classic foreign key relationship: child tables reference the PRIMARY KEY of the parent. This is to assist with expectation management. For other scenarios, see fuzzer tests discussion, below.
The app emulation uses classic INSERT, UPDATE, and DELETE statements, randomly generated. The app does not know in advance what end result it generates. However, it intentionally limits the range of affected rows to a small enough scope, that, with concurrency and with many cycles, creates high contention on all table rows. Some of the app’s auto-generated queries will have no effect and will go to waste. For example, the app may randomly attempt a DELETE FROM stress_parent WHERE id=7 AND updates=1. Possibly, id=7 row does not exist, and the statement affects zero rows. In high volumes, however, many queries will have actual effect. The app records the success and effect of any of its statements, and is able to finally conclude how many rows it expects to find in the table, and what actual data should be there.
We run a test where ON DELETE has NO ACTION rule, and a test where ON DELETE has CASCADE rule, etc. We run combinations of rules. In a CASCADE scenario, it is difficult, or impossible, given the random nature of the query design, for the app to know what data to expect in children tables following a DELETE on a parent. How can we verify that VTGate has made the correct choices, and has cascaded the DELETE correctly? This is where MySQL replication comes in handy.
As we illustrated before, VTGate implements a ON DELETE CASCADE by first applying the DELETE on children (and, recursively, first on grandchildren) before applying on the parent. As we mentioned, by the time InnoDB sees the DELETE on the parent, there’s nothing for it to cascade. We expect the binary logs to fully represent our cascading logic. As mentioned above, we use a MySQL replica, and on that replica we actually strip away all foreign keys on all tables via ALTER TABLE ... DROP FOREIGN KEY. MySQL allows that. However, the InnoDB engine on the replica now has no knowledge of foreign keys, and will not attempt to replay/reproduce any InnoDB cascading logic made on the primary server. That might break replication! At the very least, it will cause data drift between parent and child, and due to the high contention nature of the test this will soon lead to an unresolved inconsistency.
If VTGate does everything right, though, the data will remain consistent. If VTGate leaves nothing for the InnoDB engine to cascade on the primary server, then no binlog events will be missing on the replica. The replica will be able to replay VTGate’s explicit cascaded operations and to remain consistent with the primary server. The test suite does exactly that, and validates not only that replication is unbroken at the end of each test, but also that both primary and replica report the same data metrics.
Foreign key constraints in MySQL introduce more locking, by nature, and, as we’ve seen, Vitess adds even more locking scenarios. These workloads ultimately run into locking scenarios. The test ensures we are still able to make progress and that we don’t end up in a complete lock down. It goes without saying that any database can be overwhelmed by too much traffic or by too many connections, and it’s always possible to shoot yourself in the foot by introducing extremely contentious scenarios. The test suite keeps load under reasonably contentious control.
Some of the tests suffice with the above workload, and some add an Online DDL operation on top. While the workload runs, and under high contention, we pick any of the tables and run Online DDL, wait for the cut-over to complete, and, only then, give the green light to complete the test. This tests the changes in the MySQL server under load. We verify that no rows are lost when the original and shadow tables are swapped. We verify that no child table ends up with orphaned rows. We verify none of the shadow tables, or the aftermath artifact tables, has any logical effect on the app’s traffic.
Fuzzer tests
We initially started with adding tests for individual cases and queries as we went along adding support for them. But we soon realized that with the amount of possibilities of CASCADEs, SET NULLs, RESTRICTs and their interactions with each other, we would have to add a lot of tests to ensure everything worked. So, instead, we tried a different approach. We started with a set of 20 tables having foreign key relations amongst each other, such that we had good coverage of all the different possibilities. We ensure that we had cases like having a cascade rule on a child that has another cascade rule, having a restrict on a child that has a cascade rule, amongst others. Then, we wrote a fuzzer to generate different DML queries to hammer the database and verify we do the right thing in Vitess.
We introduced two distinct types of tests. The first type involves single concurrency tests, where we initiate a Vitess cluster alongside a separate MySQL instance. Both instances are initialized with identical schemas, and we execute the same queries on both through a single thread. This approach guarantees deterministic output, serving as a validation that Vitess and MySQL exhibit consistent behavior for all DML queries supported by Vitess.
The second type of tests encompasses multi-concurrency scenarios. In this case, we exclusively establish a Vitess cluster and initiate multiple threads, each executing DML queries concurrently. This particular test is designed to ensure that Vitess implements adequate locking mechanisms, preventing any correctness issues when numerous concurrent DML queries are executed. The primary goal is to ascertain that the database remains consistent throughout this concurrent operation.
As we added support for different query types, we kept expanding the fuzzer’s range of generated queries to ensure the correct implementation of each addition. Adding fuzzer tests to our suite was incredibly useful. They helped uncover issues that would have been hard to find using manual queries alone. Let’s take a look at some problems identified by the fuzzer and how we fixed them.
Updating a child table with CASCADE foreign key and grandchild RESTRICT foreign key
Our first test failure came when updating a table that has a child with CASCADE foreign key and a grandchild with RESTRICT foreign key, such that the update doesn’t cause an actual row change on the child.
Clearly, from the length of that header, we are talking about a very specific scenario!
Consider the scenario where you have the following schema:
create table parent(id bigint, col varchar(10), primary key (id), index(col)) Engine = InnoDB;
create table child(id bigint, col varchar(10), primary key (id), index(col), foreign key (col) references parent(col) on delete cascade on update cascade) Engine = InnoDB;
create table grandchild(id bigint, col varchar(10), primary key (id), index(col), foreign key (col) references child(col) on delete restrict on update restrict) Engine = InnoDB;
We initially have the following data in the three tables:
insert into parent (id, col) values (1, 3), (2, 2);
insert into child (id, col) values (1, 3), (2, 2);
insert into grandchild (id, col) values (2, 2);
Now, if you run a query like update parent set col = 2, it succeeds on MySQL. But Vitess was failing this query with a Cannot delete or update a parent row: a foreign key constraint fails error.
Upon diving further in, we found out the issue. When Vitess receives a query that requires cascades, we issue a SELECT query on the parent to lock the rows that are being updated, and then update the child first. As stated before, this update would fail on MySQL if we don’t run it with foreign key checks off. But, because we are running the query with foreign key checks turned off, it falls on Vitess to validate the RESTRICT foreign keys as well.
The update we construct for the child table looks like update child set col = 2 where col in (2, 3). To validate that none of the rows in the grandchild would prevent the updates from going through, Vitess was running a JOIN query to ensure that none of the rows being updated had a foreign key constraint with matching rows.
The SELECT query we used for validation looked like this:
select 1 from grandchild
join child on grandchild.col = child.col
where child.col IN (2, 3)
limit 1
From the outset, this looks correct. We are trying to find if there are any rows in the grandchild table that match the col of the child table for the rows being updated.
But here is the kicker. The row (2,2) is not actually resulting in any update! So, MySQL still allows the update to go through, because it doesn’t cause the data in grandchild to become orphaned!
The fix wasn’t too hard once we understood the problem. All we had to do was also exclude the rows that weren’t actually changing in the SELECT Vitess was running for verification.
So, we updated the query to look like this, and then everything worked as intended:
select 1
from grandchild
join child on grandchild.col = child.col
where child.col IN (2, 3)
and child.col NOT IN (2)
limit 1
This case illustrates just how powerful the fuzzer is and how good it is at finding cases that are rare enough that we wouldn’t have written manual tests for.
Arithmetic operations on a VARCHAR column causing 0 vs -0 problems
Consider the scenario where you have the following schema:
create table parent(id bigint, col varchar(10), primary key (id), index(col)) Engine = InnoDB;
create table child(id bigint, col varchar(10), primary key (id), index(col), foreign key (col) references parent(col) on delete cascade on update cascade) Engine = InnoDB;
And let’s say we initially have the following data in the three tables:
insert into parent (id, col) values (1, -5);
insert into child (id, col) values (1, -5);
Now, if you run a query like update parent set col = col * (col - (col)), then Vitess would end up with inconsistent data in the database:
select * from parent;
+----+------+
| id | col |
+----+------+
| 1 | -0 |
+----+------+
select * from child;
+----+------+
| id | col |
+----+------+
| 1 | 0 |
+----+------+
After investigation, we found out that the problem was coming from the part where we are doing arithmetic operations on a varchar column.
Vitess first runs a SELECT query to get the final updated values for non-literal updates. Vitess runs SELECT id, col, col * (col - (col)) from parent. It then uses the output of this query to cascade the update onto the child. The problem was that the result of col * (col - (col)) evaluation is a value -0 of type FLOAT.
This caused Vitess to issue a query like update child set col = -0 where col IN ('-5'). MySQL, however, interprets 0 and -0 as the same values and ends up setting the col to 0 causing inconsistencies.
Once we realized the issue, the fix was again not too difficult. All we had to do was type cast the expression into the type of the column. Now, Vitess issues a query like SELECT id, col, CAST(col * (col - (col)) AS CHAR) from parent and this in turn causes the update to look like update child set col = '-0' where col IN ('-5'), thus fixing the issue.
It is valuable to appreciate that the problem only surfaces when the arithmetic expression evaluates to -0. If it evaluates to any other value, it doesn’t cause any issues. This case illustrates just how useful the fuzzer is in running so many queries that it is eventually able to find cases that only happen in very specific scenarios requiring multiple conditions to be met.
Parent table unique key locking issue
While adding REPLACE INTO support for foreign keys and making adequate changes to fuzzer, we discovered that select queries executed for foreign key cascade were not able to acquire an adequate level of lock on the unique key due to missing gap locks. This led to incorrect results, and further, plan execution would result in missing cascading rows, leading to incomplete data in the binary logs.
Let’s look at a simple example:
drop table if exists some_table;
create table some_table (
id bigint,
col varchar(10),
primary key (id),
unique index(col)
) ;
insert into some_table(id, col) values (3, null), (4, 5);
-- Session 1
begin;
select col from some_table where col in (5) or id in (3) for update;
-- Session 2
begin;
select col from some_table where col in (('5')) for update;
-- This should block
-- Session 1
delete from some_table where col in (5) or id in (3) ;
insert into some_table(id, col) values (3, 5);
commit;
-- Session 2
-- Unblocked but returns 0 rows
select col from some_table where col in (('5')) for update;
-- This repeatable query in Session 2 now returns 1 row
rollback;
As a solution, we went ahead using the NOWAIT lock to promptly acquire the lock for cascade selection. NOWAIT ensures immediate lock acquisition or failure, which may result in more foreign key-related DMLs failing, necessitating query or transaction rollback.
This approach, however, effectively addresses the problem of lock waiting and prevents incorrect results.
Foreign key constraints support limitations
There still exist some limitations in our support of foreign key constraints. Many have been touched on throughout this article, but we will recap them here:
- While self-referencing tables are supported, cyclic foreign key references between different tables is not allowed.
- Foreign key constraints names change on every deployment. This is largely due to the MySQL limitation (compatible with ANSI SQL specification) where constraint names must be unique to the schema.
- Foreign key constraints are currently only supported in unsharded environments.
- There are some scenarios where schema reverts can create orphaned rows.
For a full list of limitations, see our foreign key constraint documentation.
Summary
In summary, we faced several challenges in supporting foreign key constraints in Vitess and PlanetScale, but are extremely pleased with where we landed.
If lack of foreign key constraint support has been a barrier to you trying PlanetScale in the past, we welcome you to enable foreign key constraint support in your database settings page, and give PlanetScale a try. If you have any questions, don’t hesitate to reach out to us.