We're excited to announce that PlanetScale vector search and storage is now available in open beta! With PlanetScale vector support, you can store your vector data alongside your application's relational MySQL data — eliminating the need for a separate specialized vector database.
What sets PlanetScale vector search and storage apart?
When we decided to add vector support to PlanetScale's MySQL fork, we knew it would be a long journey to ensure the solution met our high standards for performance and scalability.
A crucial piece of this was architecting a search algorithm that allows for both fast performance and large scale. PlanetScale's vector search is based on two innovative research papers from Microsoft Research: SPANN (Space-Partitioned Approximate Nearest Neighbors) and SPFresh. We did additional work to fully integrate our solution with InnoDB and Vitess, which allows us to support transactional operations, ensure data consistency, and efficiently manage vector indexes at terabyte-scale. This makes our vector search solution ideal for large-scale databases.
On top of that, we wanted to make sure our implementation supports the following:
- Pre-filtering and post-filtering
- Full SQL syntax — including
JOIN,WHERE, and subqueries - ACID compliance
Our base implementation checks all of these boxes, and we will continue to improve performance leading up to GA.
Choosing a vector search algorithm
There are a few different algorithms commonly used to implement vector search: Hierarchical Navigable Small Worlds (HNSW) and DiskANN being two of the most popular. These algorithms, however, make technical trade-offs that we deemed inadequate for our implementation.
HNSW has very good query performance, but struggles to scale because it needs to fit its whole dataset in RAM. Most importantly, HNSW indexes cannot be updated incrementally, so they require periodically re-building the index with the underlying vector data. This is just not a good fit for a relational database. DiskANN scales well, but suffers from worse query performance, and while it can be modified to allow incremental updates, these are not particularly efficient and are hard to map to transactional SQL semantics.
Because PlanetScale is designed to support incredible performance for databases at massive scale, we knew these implementations wouldn't work for us. So we set out to find a better solution.
PlanetScale vector search is based on a novel implementation of two state-of-the-art papers from Microsoft Research: SPANN (Space-Partitioned Approximate Nearest Neighbors) and SPFresh. SPANN is a hybrid vector indexing and search algorithm that uses both graph and tree structures, and was specifically designed to work well for larger-than-RAM indexes that require SSD usage. SPFresh extends the design of SPANN with a set of concurrent background maintenance operations that allow the index to be continuously updated without losing recall or query performance.
For our implementation, we have extended SPFresh by adding transactional support to all its operations and fully integrating it inside InnoDB, MySQL's default storage engine. This means that inserts, updates, and deletes of vector data are immediately reflected in the vector index as part of committing your SQL transaction, and follow the same transactional semantics, including support for batch commits and rollbacks.
Since the indexes are fully managed and stored on-disk by InnoDB, they are always in-sync with the vector data in your tables, they survive process crashes with strong consistency guarantees, they do not need to be periodically rebuilt, and they scale all the way into terabytes, just like any other MySQL table. Together with Vitess, PlanetScale's sharding layer, this allows the construction and efficient querying of huge vector indexes that are fully integrated with all the relational data in your database and can be used with JOINs and WHERE clauses while the underlying vector data is continuously updated.
Note
For a comparison of some of the common vector algorithms and indexes, see our Vector database terminology and indexes documentation.
How to enable vector support
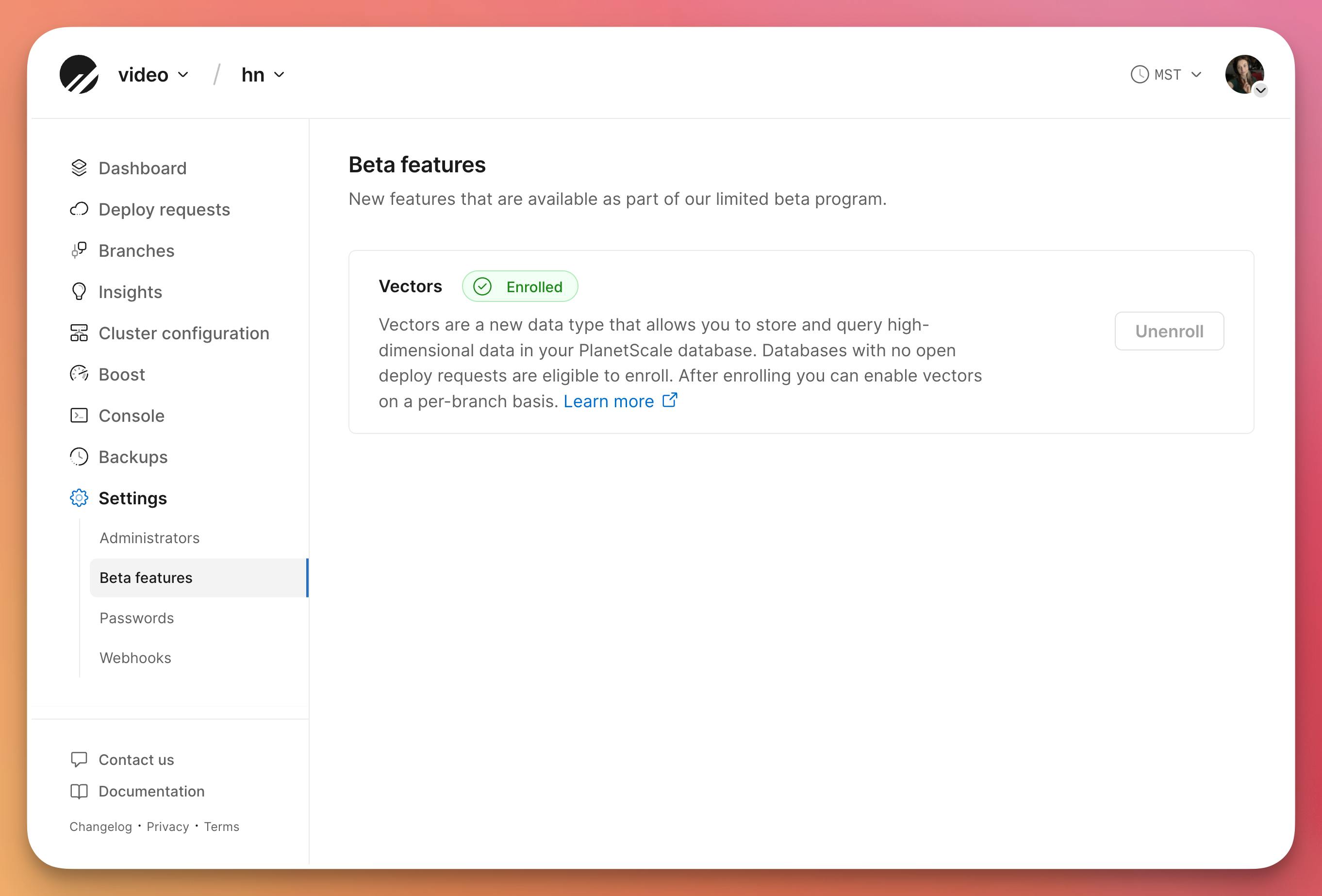
To get started, go to your database settings page, click "Beta features", find Vectors and click "Enroll". Vector support is enabled at the branch level, so choose the branch you wish to enroll into the vectors beta. Click the gear icon on the branches page, and click the toggle next to "Enable vectors".
More resources
To learn more about vector embeddings, check out our YouTube video:
You can check out the following documentation:
- PlanetScale vectors overview
- Vector database terminology and concepts
- Common use cases for vector search
- PlanetScale vector usage with ORMs
- Vector type and index reference
Your feedback is extremely valuable during this beta period, so don’t hesitate to reach out. You can submit a support ticket to relay any feedback or issues. We also have a vectors channel in our Discord where you can ask questions, share feedback, or chat about use cases.