On the surface, you might look at PlanetScale's Vitess product as a drop-in replacement for your database, and you wouldn't be wrong. Our primary focus is providing a simple and cost-effective way to create a performant MySQL configuration so you can focus on writing code instead of also wearing the DBA hat. But our service goes well beyond a traditional MySQL server. In this article, we'll take a look at all the individual software and infrastructure components that PlanetScale can replace.
MySQL with Vitess
Let's start with the most obvious one: MySQL. If you've ever had to manage a MySQL environment, you probably know it's not a trivial task. If you were to set up a performant and reliable MySQL environment in a data center, you'd have to consider far more than just a server running the service. For starters, you'd have to know how to set up a MySQL cluster with multiple physical or virtual servers to address inevitable outages. You'd also need to understand the right kind of storage to hold the databases so they aren't limited by the IOPs of the underlying disks. Considering the servers also need to talk to the outside world, as well as each other, you can't skimp on networking gear either.
Crafting and maintaining a database environment for a production service is no joke. PlanetScale's Vitess clusters provide an environment that automatically configures the compute, storage, and networking, as well as the necessary components to handle failovers in case a node goes offline within our environment. On top of the orchestration provided by Vitess, the environment automatically load balances connections to provide a single endpoint for applications to connect. The same component that routes queries within the environment also manages connection pooling, eliminating the need for tools like ProxySQL.

Online schema changes
One of the most challenging things to manage in the development cycle is syncing the schema between two databases. A common scenario where this might need to occur is when working on separate environments within the same application. Given the example of a development and production environment running side by side, developers will often make changes to the database schema in a development environment to coincide with the new features they are building. When the time comes to go live, there needs to be a way to apply the changes from the development database schema to the production schema without bringing the entire application down.
You might explore tools like gh-ost or pt-online-schema-change to address this need, but PlanetScale handles this automatically with our Branching and Deploy request workflow. Every database can have one or more branches, which would be used in place of the development environment in the scenario above where separate databases are used. Developers would make any necessary schema changes to that branch during the development phase.
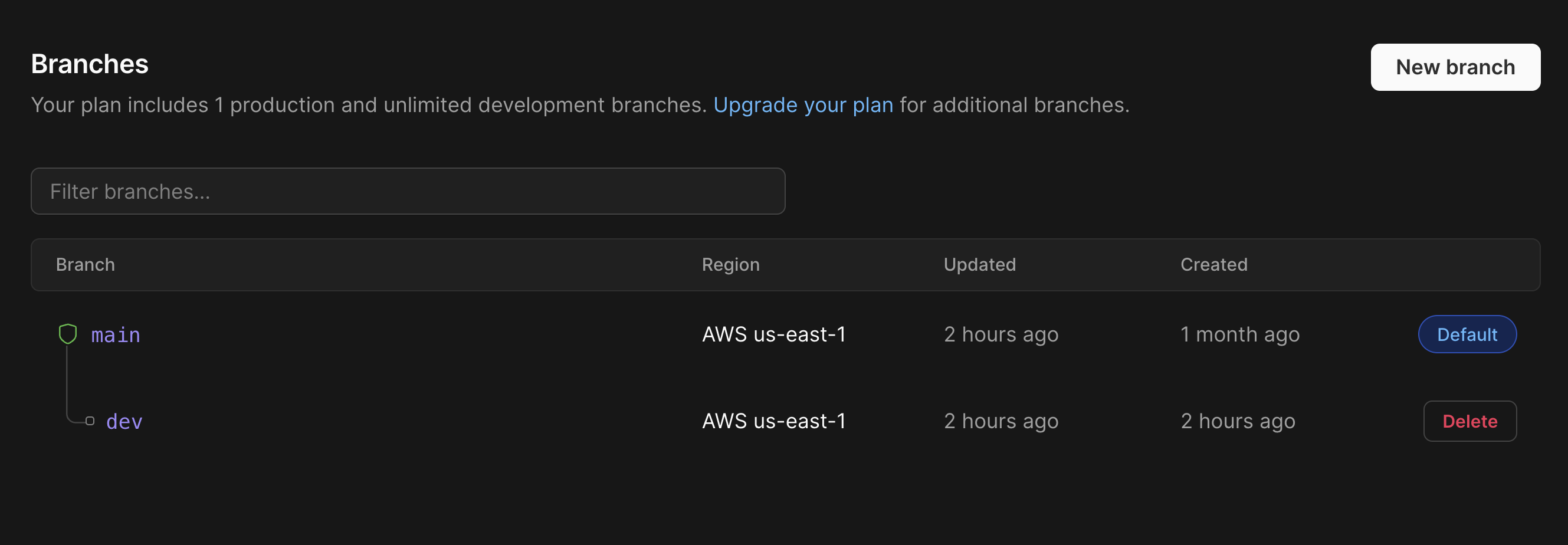
When they want to release the changes, a deploy request would be created that would let anyone on the team review the changes that will be applied to the main production database, very similar to the way pull requests work in a git environment. PlanetScale also runs the changes through an automated analysis system to inform developers whether or not the schema changes may be destructive or affect the data in any way.
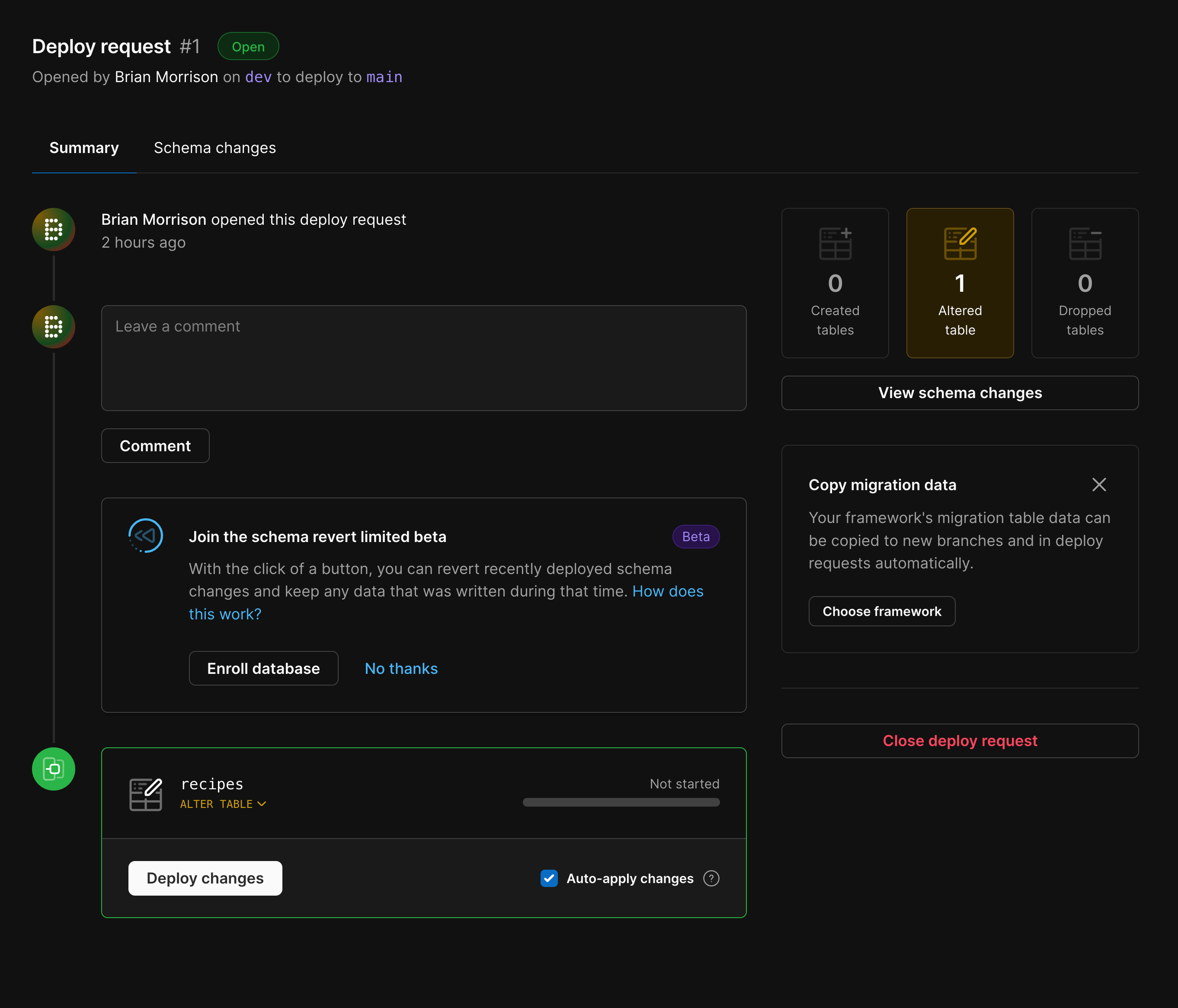
Once the changes are approved, the schema changes will be applied to the production branch of the database with zero downtime. Using the branching system, PlanetScale also has built-in change tracking for your database schema, providing a method to audit and track what changes are made to the database and by whom.
The branching feature also provides a method to quickly rollback schema changes. In a situation where changes are deployed, but your application starts experiencing unforeseen issues as a result, you'll have a 30-minute window to quickly revert the changes without affecting the data that was written to the database while the changes were active. This can act as an emergency backout to quickly get you back up and running while further debugging needs to happen.
Monitoring and metrics
Managing the infrastructure is an excellent first step towards a performant MySQL environment, but poorly written queries and missing or misconfigured indexes can still degrade any well-architected setup. Typically, you'd need to install third-party tools like SolarWinds Database Performance Monitor (formerly VividCortex) to keep an eye on how well the queries are performing and report any potential issues so you can decide how to optimize queries.
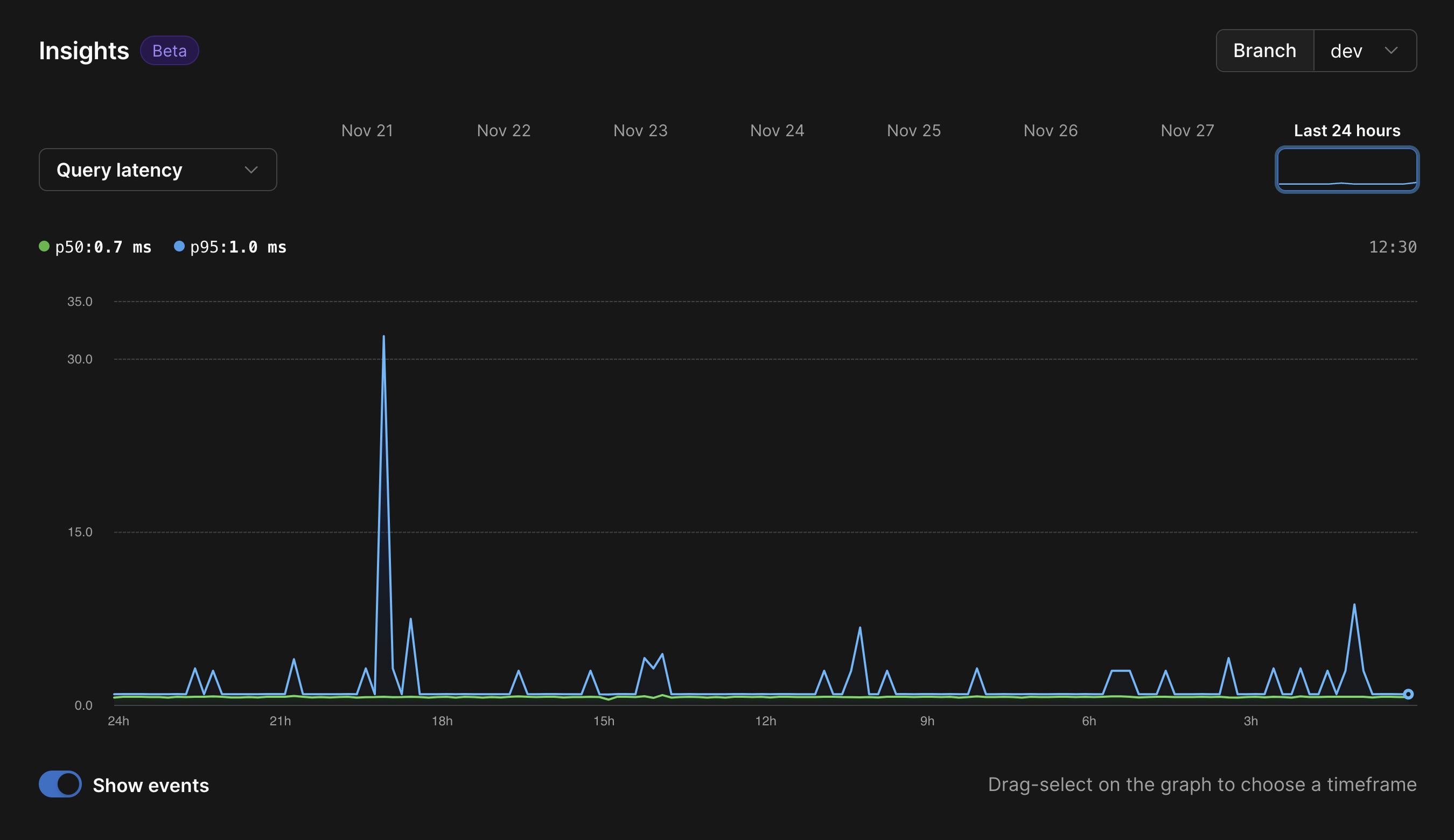
PlanetScale has this functionality built-in for all databases on our platform with the Insights feature, regardless of the tier you are on. Insights provides a way to analyze slow-running queries so you can make intelligent decisions on how to optimize those queries or apply the right indexes. Execution data is retained for 7 days and is used to track how many times a query was run, how long it took, and how many rows were both read and returned. All of this data is then provided in a concise, filterable, and sortable table with an accompanying chart that lets you select the specific timeframe you want to analyze.
Backup and restore
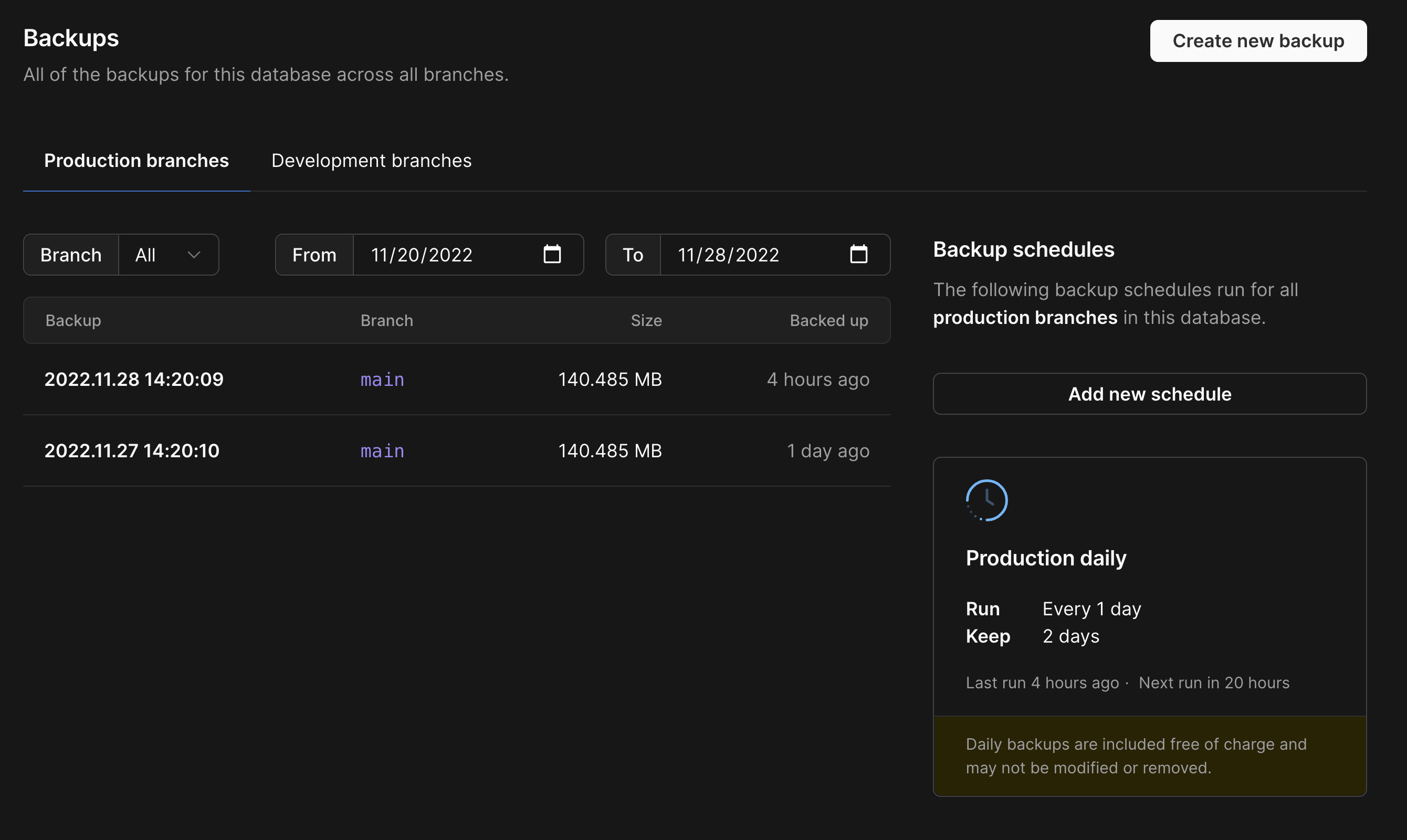
Backups are critical to the operation of any database in case data gets mistakenly deleted or updated. While many platforms require you to manually configure backups, database backups in PlanetScale are automatically configured for every database. When you create a database, each branch of that database will be backed up once every 12 hours for the Base plan, and backups are retained for 2 days. These are simply the defaults though; you are welcome to create any additional backup schedules you desire and are only charged for the cost of the data stored. The data is stored right in our system so you won't need to configure external storage like S3 to retain your backups.
When you need to restore, you'll be presented with a list of the available restore points for that database, which can be restored into a dedicated branch, giving you the option to review the data and test your application with it before fully moving to the restored version of your database.
Conclusion
Reiterating what was stated earlier, building a database system (regardless of the engine) that is performant, scalable, and feature-rich goes well beyond installing the software on a computer. You'd need a great deal of other tooling on top of the database itself, which also means additional resources to manage and maintain said tooling. PlanetScale aims to provide the simplest way to spin up a complex MySQL environment, complete with bells and whistles, without you having to worry about the overhead that comes along with it.