The Postgres process-per-connection architecture has an elegant simplicity, but hinders performance when tons of clients need to connect simultaneously.
The near-universal choice for solving this problem is PgBouncer. Though there are upcoming systems like Neki which will solve this problem in a more robust way, PgBouncer has proven itself an excellent connection pooler for Postgres.
PlanetScale gives you local PgBouncers by default, and makes it incredibly easy to add dedicated ones when needed. The challenge comes in determining the optimal configuration for your app, which is highly use-case dependent.
My aim with this article is to make every engineer well-equipped to tune PgBouncer with confidence.
Why PgBouncer?
PgBouncer is a lightweight connection pooler that sits between your application and Postgres.
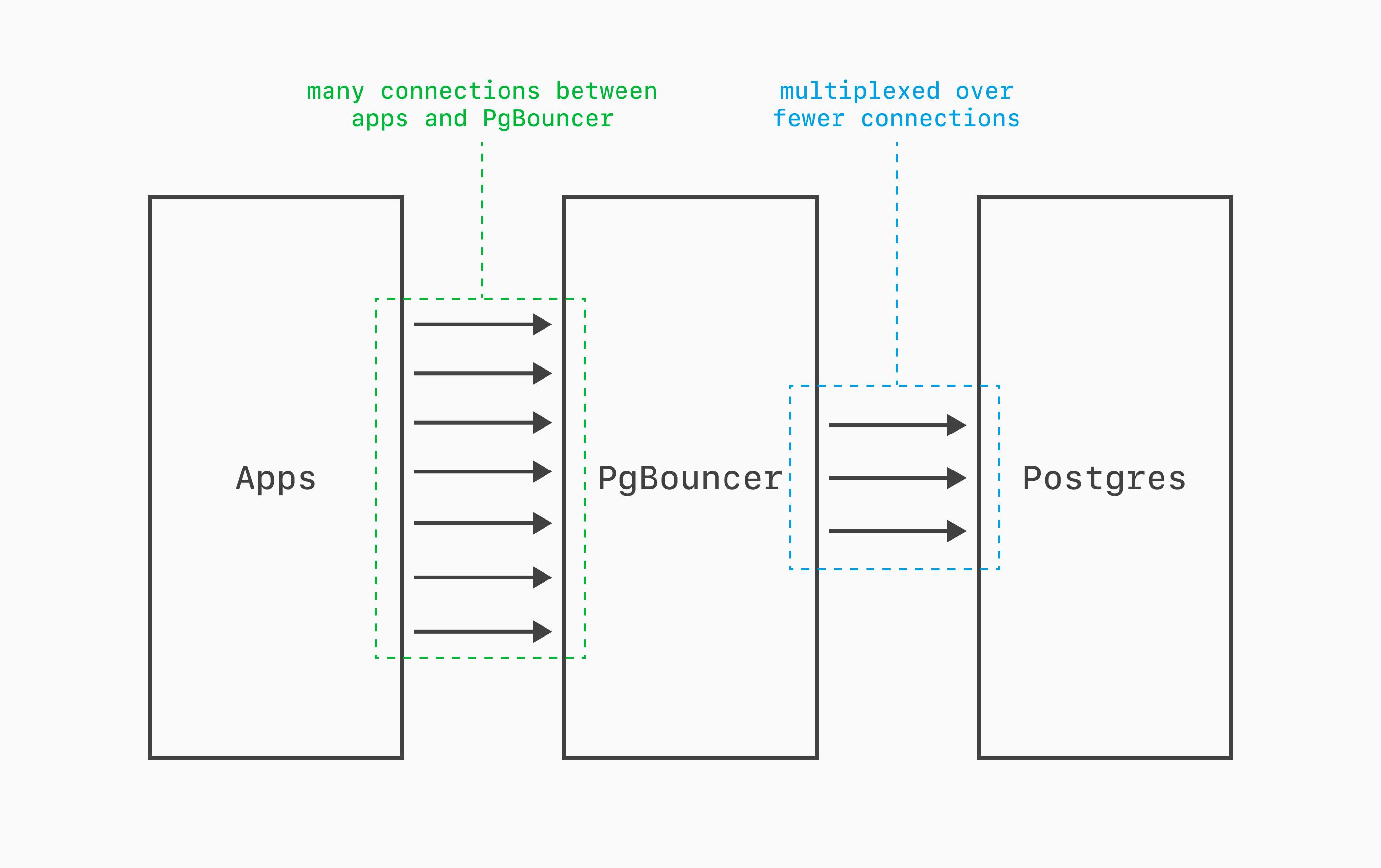
PgBouncer is totally transparent, speaking the PostgreSQL wire protocol. From an app's perspective, it's just talking to a Postgres server, PgBouncer acting as a lightweight middleman. It can multiplex thousands of client connections onto tens of Postgres connections.
But why not just make 1000s of connections directly to Postgres? Unfortunately, the Postgres process-per-connection architecture doesn't scale well. Every connection forks a dedicated OS process consuming 5+ MB of RAM and adding context-switching overhead. PgBouncer solves this by maintaining a pool of reusable server connections, reducing resource consumption and letting PostgreSQL handle far more concurrent clients than its native max_connections would otherwise allow.
It's best-practice to keep the count of direct connections to Postgres small. Tens of connections for smaller instances. Hundreds for larger servers.
This is too restrictive for the way modern apps are built. We frequently want thousands of simultaneous connections to the database. PgBouncer gives Postgres that capability while keeping the total number of forked processes low.
At PlanetScale, we recommend using PgBouncer for all application traffic, only resorting to direct connections for administrative tasks and a few other narrow cases.
How to use PgBouncer
PgBouncer maintains a pool of pre-established Postgres server connections. When an app / client needs a database connection, it connects to PgBouncer, and then PgBouncer uses one of the pre-existing pooled connections to pass along the message. When the client is done, the connection returns to the pool for reuse. A single pooled Postgres connection can serve hundreds or thousands of client PgBouncer connections over its lifetime.
When all pool connections are in use, PgBouncer queues the client until one becomes available rather than rejecting it. If the wait exceeds query_wait_timeout (default: 120 seconds), the client is disconnected with an error.
Whereas the Postgres default port is 5432, PgBouncer defaults to 6432. Typically, switching from a direct connection to a PgBouncer connection is as simple as switching the port in your client connection string.
This is true on PlanetScale, with a twist: We give you three options for using PgBouncer:
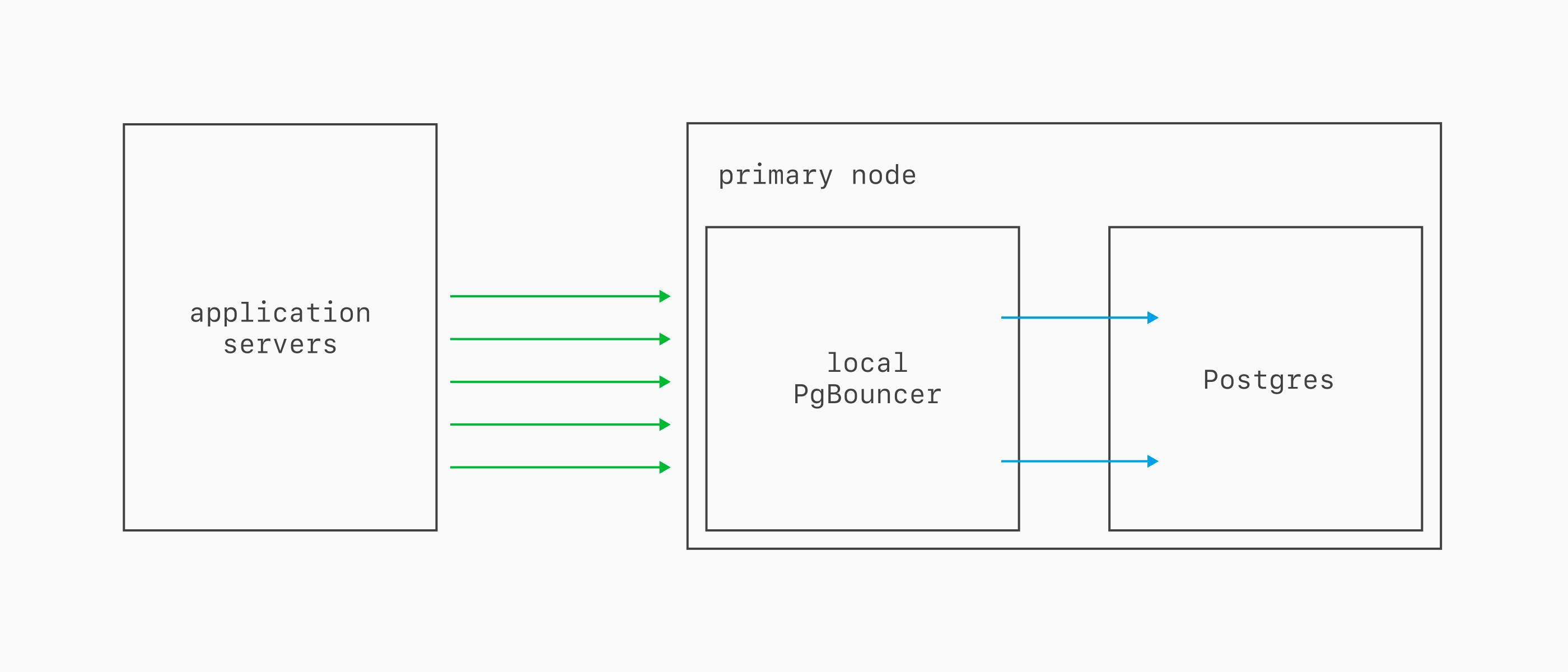
Local PgBouncer
Every Postgres database includes a local PgBouncer running on the same server as the primary. Connect using the same credentials as usual, just swap the port to 6432.
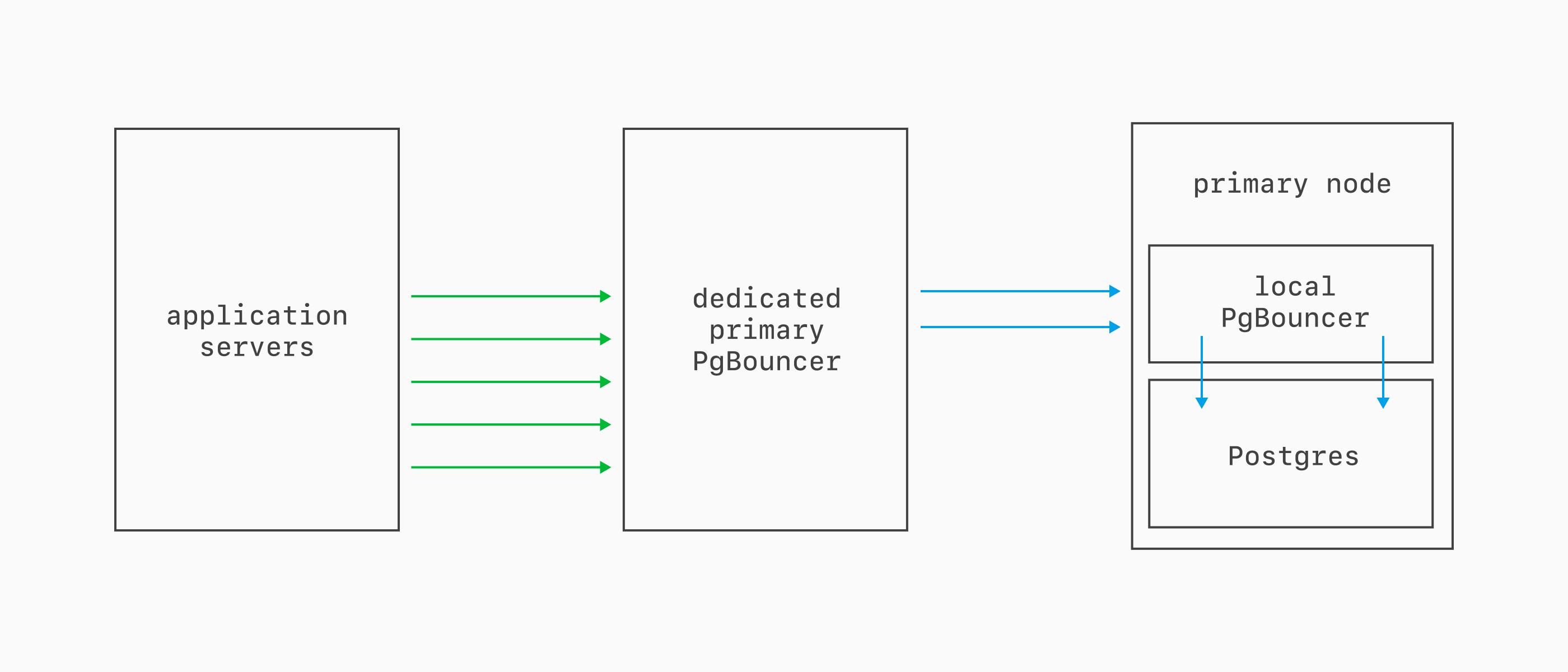
Dedicated primary PgBouncer
A dedicated primary PgBouncer runs on separate nodes from Postgres, making for better HA characteristics. It connects to the local PgBouncer first, which then connects to Postgres. Client connections persist through resizes, upgrades, and most failovers. Connect by appending |your-pgbouncer-name to your username on port 6432.
Dedicated Replica PgBouncer
Dedicated replica PgBouncers are similar to dedicated primary ones, but connect to the replicas instead (and don't route through the local bouncer).
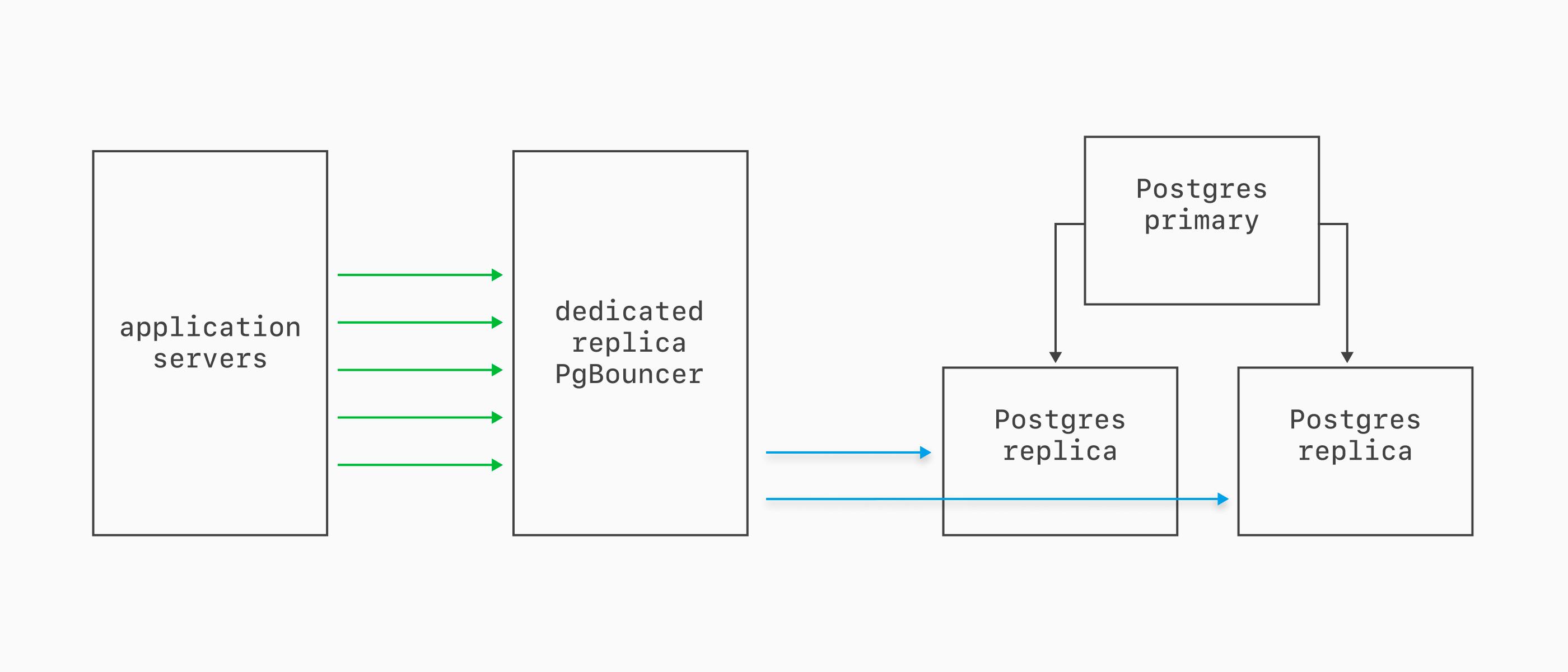
We recommend this if your applications make heavy use of replicas for read queries.
The three pooling modes
PgBouncer operates in one of three modes.
Session pooling assigns a server connection for the lifetime of the client connection, releasing it only when the client disconnects. This means there's a 1:1 mapping between client and server connections. It's not incredibly useful, as it does little to reduce Postgres connection count. At times, it's helpful for limiting thundering herds of connections.
Statement pooling assigns a server connection for a single SQL statement and releases it immediately after. This means multi-statement transactions are disallowed entirely. Most apps need this, so not useful in 99% of cases!
Transaction pooling is the only sensible option. It assigns a server connection for the duration of a transaction, returning it to the pool the moment a COMMIT or ROLLBACK completes. This is great for most use cases, though there are a few unsupported features in this mode.
PlanetScale only supports Transaction pooling, given the clear weaknesses of the two. When you absolutely need one of those few unsupported features, keep them to a small number of direct-to-Postgres connections.
Knob all the things
PgBouncer's configuration centers on a hierarchy of connection limits. These control how many client connections are accepted, how many server connections are maintained per pool, and how those relate to PostgreSQL's own max_connections.
The connection chain works like this:
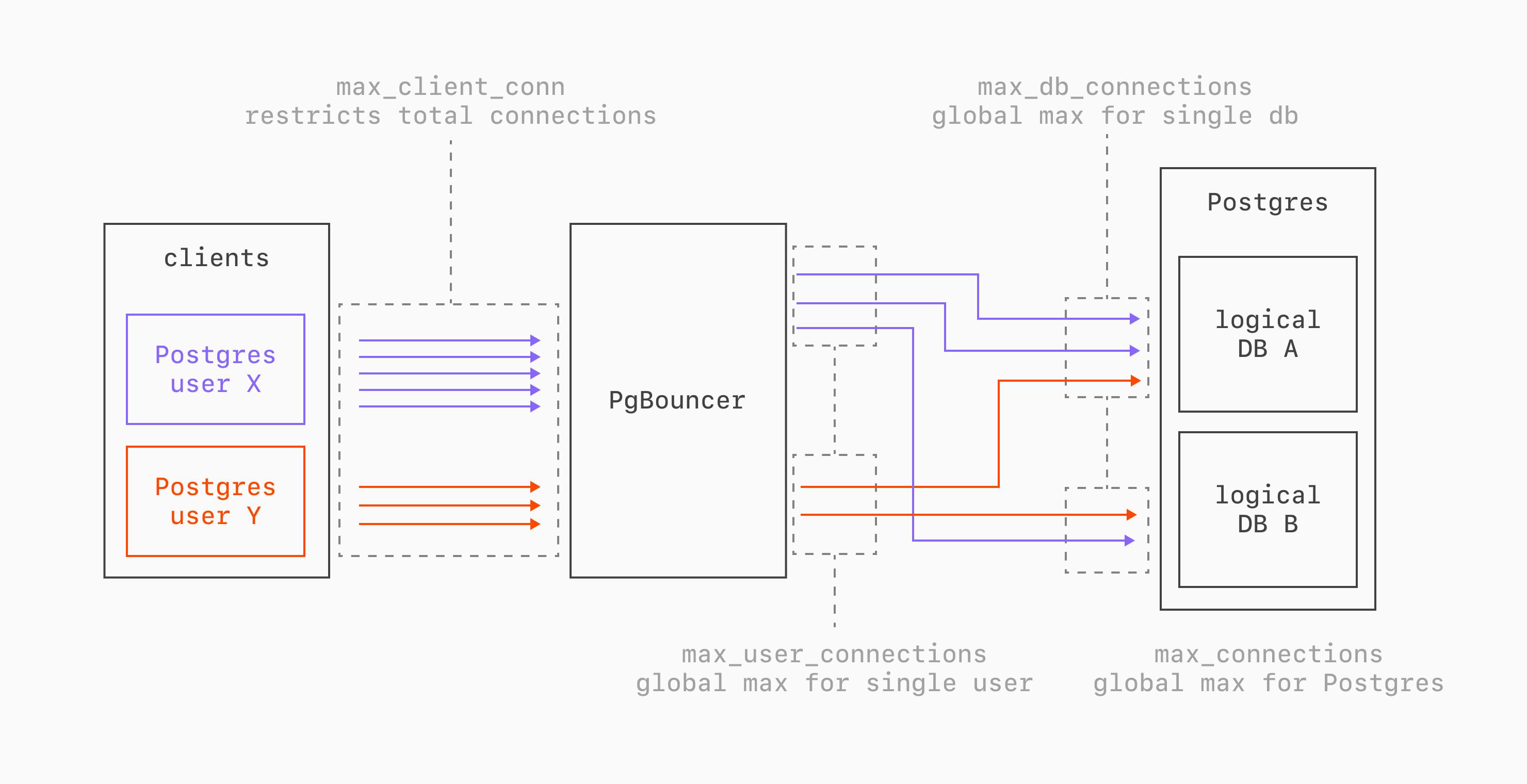
max_client_conn is the maximum number of application connections PgBouncer will accept. Because connections are lightweight in PgBouncer, this is frequently set in the 1000s.
default_pool_size controls the number of server connections per (user, database) pair that PgBouncer will make to Postgres. How to configure this depends quite a bit on your schema and access patterns. In an environment where you have a single server with many logical databases and many Postgres users, this will likely need to be set low, between 1-20. When you have a single logical database and a small number of Postgres roles, this can be set much higher.
The total potential PgBouncer ↔ Postgres connections equals num_pools × default_pool_size. With 4 users and 2 databases we get 4 x 2 = 8 pools. At a pool size of 20, PgBouncer could open up to 160 connections to PostgreSQL.
max_db_connections and max_user_connections are hard caps that span across all PgBouncer pools for a given database or user, respectively. They act as safety valves to prevent pool arithmetic from exceeding PostgreSQL limits. These default to 0 (no limit) but can be set in some scenarios for safety.
All the above are PgBouncer settings. The key setting on the Postgres side is max_connections. The total server connections must stay below this number. We should always keep a few available direct connections reserved for admin tasks and other emergency scenarios. We NEVER want PgBouncer to use all of the connections!
All of this can be summarized in a nice formula:

In Postgres, we can explicitly set superuser_reserved_connections, which is handy for ensuring some connections are reserved for the superuser.
Tuning examples
Thinking through some practical scenarios makes this easier to reason about.
Small server
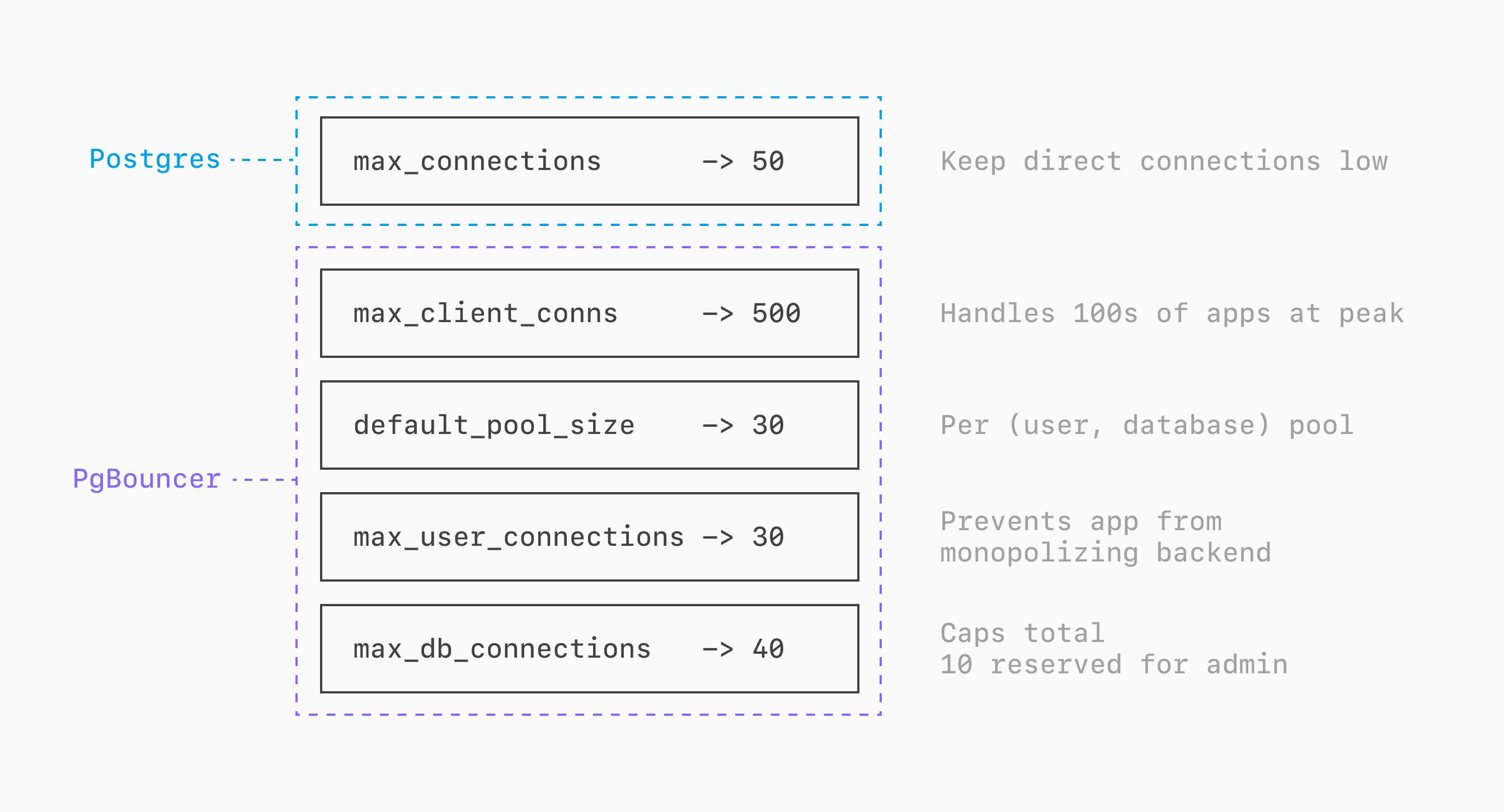
First, let's think through having a PlanetScale PS-80 (1 vCPU, 8GB RAM per node), a single multi-tenant database, and 3 distinct Postgres users we use for clients connecting through PgBouncer: one for the app servers (app), one for an analytics service (analytics), and one for a data exporter (export).
We want to keep direct Postgres connections low, so we set the Postgres max_connections=50.
Though it's a small database, we sometimes have 100s of app servers making simultaneous connections during peak load. We set the PgBouncer max_client_conn=500.
The majority of these connections come from a single Postgres user + database pair (the app-server user connecting to the main logical database). Because of this, we set default_pool_size=30 but then also set max_user_connections=30 and max_db_connections=40. This prevents connections from the app user from utilizing all of the backend connections, ensuring some are always available for the other two. This also means PgBouncer can never hold more than 40 connections to Postgres in total, ensuring 10 are always available for other services or administrative tasks.
Large server
Now for the same scenario, but with much higher traffic, requiring an M-2650 (32 vCPU, 256GB RAM per node). We'll again have the same 3 distinct Postgres users.
Just because we now have 32x the CPU power, we don't want to increase direct Postgres connections by 32x. It's still wise to keep this on the lower side, so we will settle in at a max of max_connections=500.
We now sometimes have 1000s of app servers making simultaneous connections during peak load. We set the PgBouncer max_client_conn=10000.
Because of this, we set default_pool_size=200 but then also set max_user_connections=200 and max_db_connections=450 for similar reasons as the previous example. No one user can use more than 200 connections.
This also means PgBouncer can never hold more than 450 connections to Postgres, ensuring 50 remain available for other purposes, or if we add services requiring features of direct connections like session variables.

Single-tenant configuration
Though single-tenant architectures are generally discouraged, some organizations prefer this or have inherited such a structure. In this case, we'll assume there is a unique logical database co-located on the same Postgres server for every customer.
Say in this case we have a PlanetScale M-1280 (16 vCPUs, 128GB RAM per node), 200 distinct logical databases (for 200 tenants) and a unique Postgres role for each, for the sake of isolating permissions. There is a 1:1 mapping between each logical database and the Postgres user querying it.
This is a much different connection pattern than the previous example. We have 200 roles connecting to 200 logical databases all on the same host, and want to ensure we can scale to thousands of combined connections without hitting limits.
We'll center this around max_connections=400.
If any one tenant peaks at 20 connections, then we'll set PgBouncer's max_client_conn=5000 (includes a bit of buffer).
Recall that default_pool_size controls connections per (user, database) pool. Since each of the 200 users connects to exactly one database, there are 200 active pools. Even a modest default_pool_size results in a large number of server connections: for example, a default_pool_size of 10 would yield a theoretical max of 200 × 10 = 2,000 server connections, far exceeding max_connections=400.
We'll set default_pool_size=2 (at most 2 PgBouncer <-> Postgres connections per pool). Since we have a clean user-to-logical-database mapping, we also set max_db_connections=2 and max_user_connections=2 to enforce this per-pool cap. The maximum total PgBouncer server connections is 200 × 2 = 400, matching max_connections=400.
A single tenant can have 10s or even 100s of connections to PgBouncer, but all these will get multiplexed through at most 2 direct Postgres connections.

App-side PgBouncers
In some deployments, it also makes sense to layer PgBouncer. You can run one PgBouncer on the app or client side to funnel many worker or process connections into a smaller egress set, then run another PgBouncer near Postgres as the final funnel into a tightly controlled number of direct database connections.
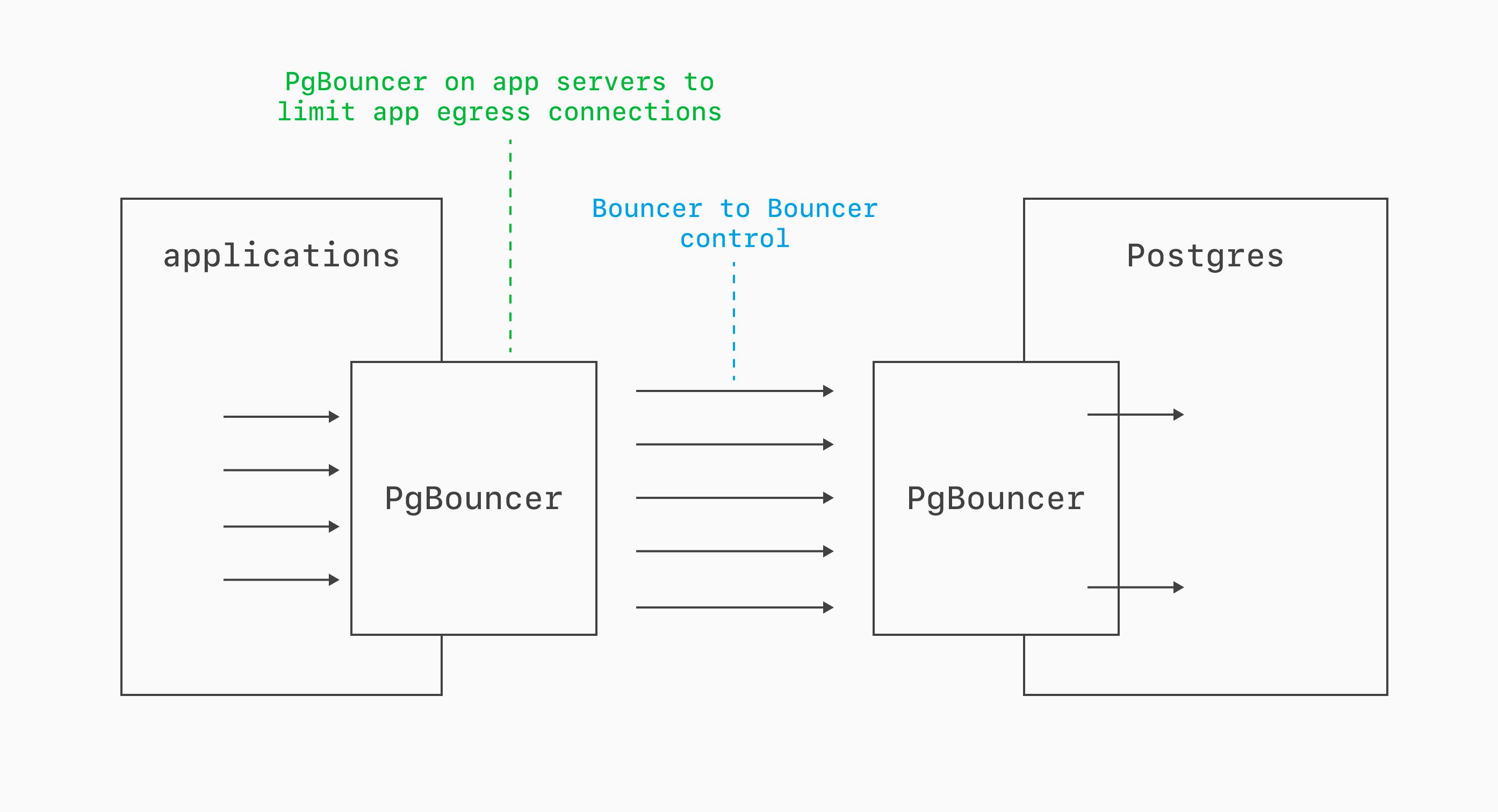
This is especially useful when you need connection pooling both close to compute and close to the database.
Multiple PgBouncers
In large-scale deployments, setting up multiple PgBouncers is useful for traffic isolation. When your web app, background workers, and other consumers all share one pool, a spike from one class of traffic can saturate the PgBouncer and delay everything else.
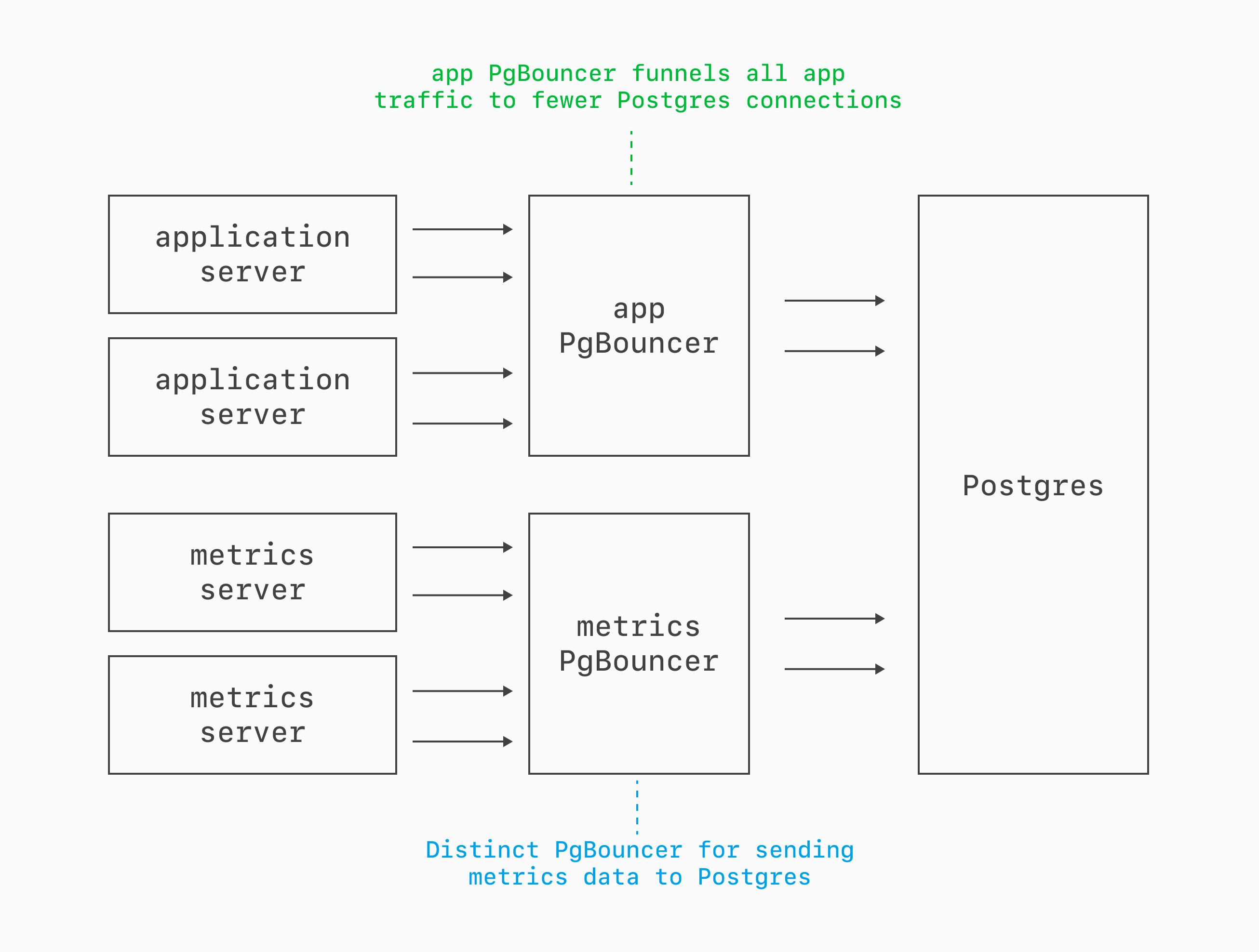
Giving each major consumer its own PgBouncer creates independent funnels with their own limits, pool sizing, and failure domains. That makes it easier to protect latency-sensitive app traffic from bursty worker traffic and tune each workload separately.
For an additional layer of protection, Database Traffic Control® lets you enforce resource budgets on query traffic by pattern, application name, Postgres user, or custom tags — without needing separate infrastructure. The two approaches complement each other well: PgBouncer manages connections, Traffic Control manages resource consumption.
The key concepts
PgBouncer solves a fundamental architectural constraint in PostgreSQL: the process-per-connection model that makes every connection expensive. When working with PgBouncer, there are a few fundamental things to keep in mind:
Transaction pooling is the mode that matters. Every transaction, be it a single query or many, gets a dedicated connection from PgBouncer <-> Postgres while executing. After this, the connection can be re-used for another transaction, maybe on the same client, and maybe for another.
Use PgBouncer as much as possible. If you absolutely need features that are incompatible with transaction pooling, like
LISTEN, session-levelSET/RESET, or SQLPREPARE/DEALLOCATE, use a direct connection. In all other cases, the small latency penalty of PgBouncer is well worth the scalability and connection safety.The key configs to pay attention to are:
max_connections(Postgres), plusmax_client_conn,default_pool_size,max_db_connections, andmax_user_connections(PgBouncer).Ensure things are configured to allow for direct connections, even when all PgBouncer connections are in use.