Back in the day, as a junior software developer, I was terrified to make database changes. We all hear the horror stories of one wrong command being run, and everything is wiped out. Or a database change took longer to release than expected, and users were severely affected.
At the same time, I was never pushed to get “good” at databases. I worked at a small startup. I had product features to release. I wanted to be better at Python and JavaScript, not databases. The database was just not my focus, so it stayed scary.
As many of you know, not making changes in the database is never an option. Your database has to grow and change with your application and product. The velocity of our database changes cannot be slow if we want to ship new features regularly, but historically moving safely has meant moving slowly. These bottlenecks can come from different sources, like having a limited number of database experts on the team or being restrictive of what and when changes can occur.
In this blog post, I want to focus on safely making database schema changes without these blockers. I'll touch on both database best practices and PlanetScale features that ensure safe database schema changes.
Smaller, frequent changes
Before we get into PlanetScale-specific features, I want to start with the size of schema changes. Modern software development teaches us to release code early and often. This should apply to our database changes too.
We aim for smaller, more frequent schema changes instead of big, complex changes. Smaller changes are easier to test, verify, and are safer for the whole system. It's hard to verify large changes that span across the schema and into many different tables. A small SQL change is easier to understand and verify than one with hundreds of lines of SQL.
You and your team might be the only database consumers from an application code perspective when you are small. However, as the company grows, multiple teams or departments will interact with the database. This can make bigger changes even riskier. (If this includes an Analytics or Data team, you should check out PlanetScale Connect.)
Backwards compatible changes
Anytime you change an existing schema used by application code, you should ensure it is backward compatible at all steps of the process. You may have also heard of this referred to as the “expand and contract” model. An oversimplification of this model is that you:
- Expand the schema: Update the existing schema with new changes
- Update the application code to write to both old and new schema
- Migrate data from the old schema to the new schema
- Update the application code to only read from the new schema
- Update the application code to only write to the new schema
- Contract the schema: Remove the old schema that is no longer used
The expand and contract model ensures that at any time throughout a schema change, your application code will always work and not break while you are changing the existing schema. You can learn more about making backwards compatiable database changes in this blog post.
Feature flags
You might be wondering, what do feature flags have anything to do with database schema changes? The reality is that they can help us make incremental changes to the database more safely. Using feature flagging, we can incrementally roll out new features built on top of the updated database schema. If something goes wrong in that process, we can roll back in many cases. Of course, not all changes can be rolled back, and you must implement feature flags properly. Still, they are a helpful tool to leverage alongside your database when you want to make safer changes incrementally.
Branching
A core part of safely making database schema changes with PlanetScale is branching. A database branch provides an isolated copy of your production database schema, where you can make changes, experiment, and test. With safe migrations turned on in PlanetScale, branching enables you to have zero-downtime schema migrations, the ability to revert a schema, protection against accidental schema changes, and more with deploy requests.
Deploy requests
When using safe migrations to deploy a database branch to production, you must open a deploy request in PlanetScale. Behind the scenes, though, PlanetScale is running automated linting for you to ensure your schema change is compatible and ensuring it can be safely deployed.
PlanetScale will even check that tables are truly unused during deploy requests and warn you if the table to be dropped was recently queried.
A deploy request automatically checks for:
- Conflicts that would prevent the schema from being migrated, such as an invalid column or table charsets, non-null unique keys, and more
- Data loss from proposed schema changes
- Conflicts with other schema changes from teammates
This removes the burden of a human needing to catch these in a deploy request. It saves time, mental energy, and prevents possible errors in a schema migration. Making schema reviews easier helps reduce the workload of schema changes. It does not require a whole team of DBAs to review developers' schema changes.
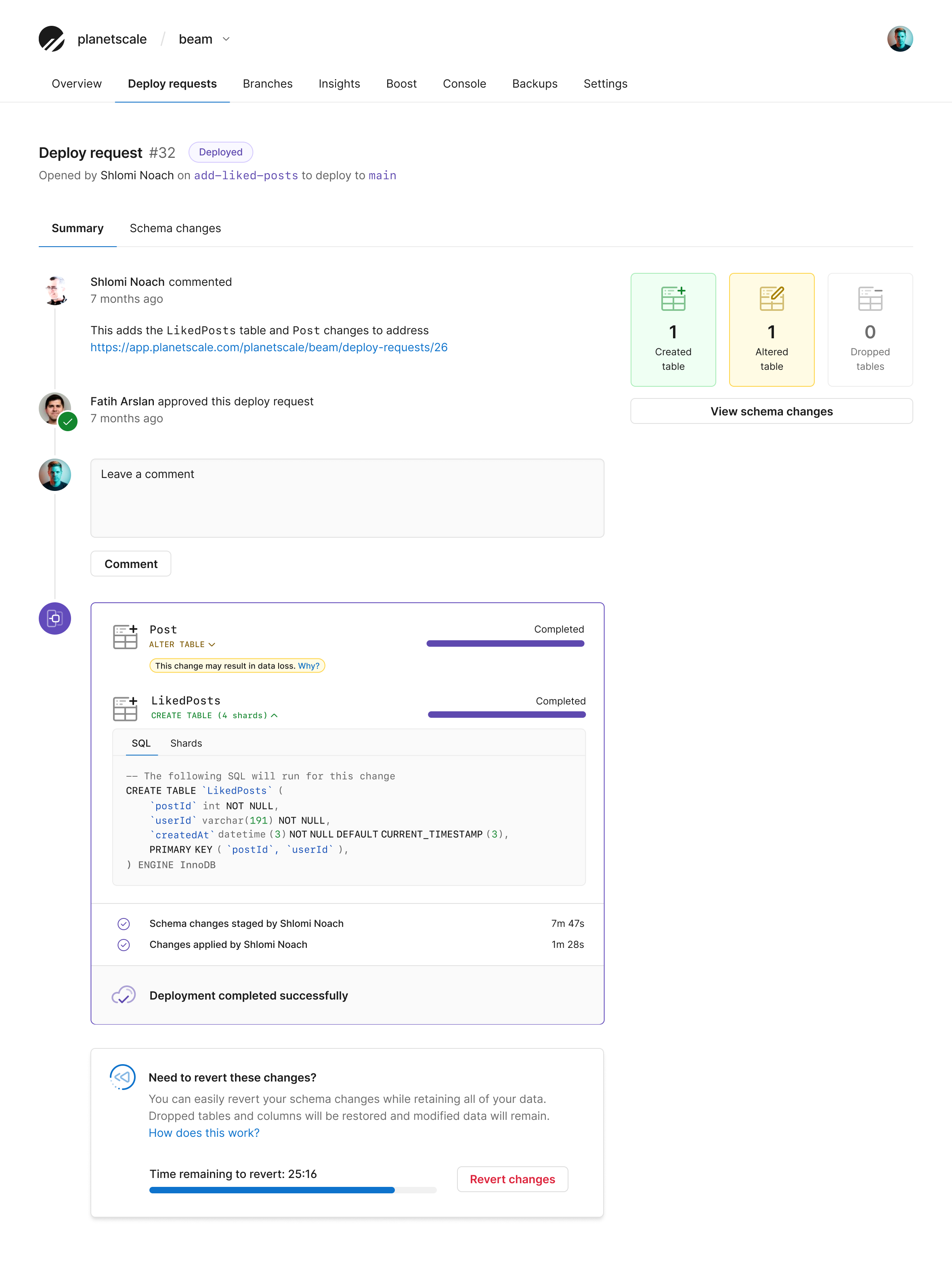
Schema reviews
Historically, schema changes have not gotten the same treatment as code changes. Doing a schema review in a PlanetScale deploy request helps give you a transparent schema review process. It is visual and deeply rooted in how we review pull requests for code.
It clearly shows what tables have been created, altered, or dropped. It also shows the exact SQL that will run for the change. This is also useful if the SQL migration was created by an ORM where you only sometimes see the actual SQL being run. Like in a pull request, you can see what is being added and removed from the existing schema.
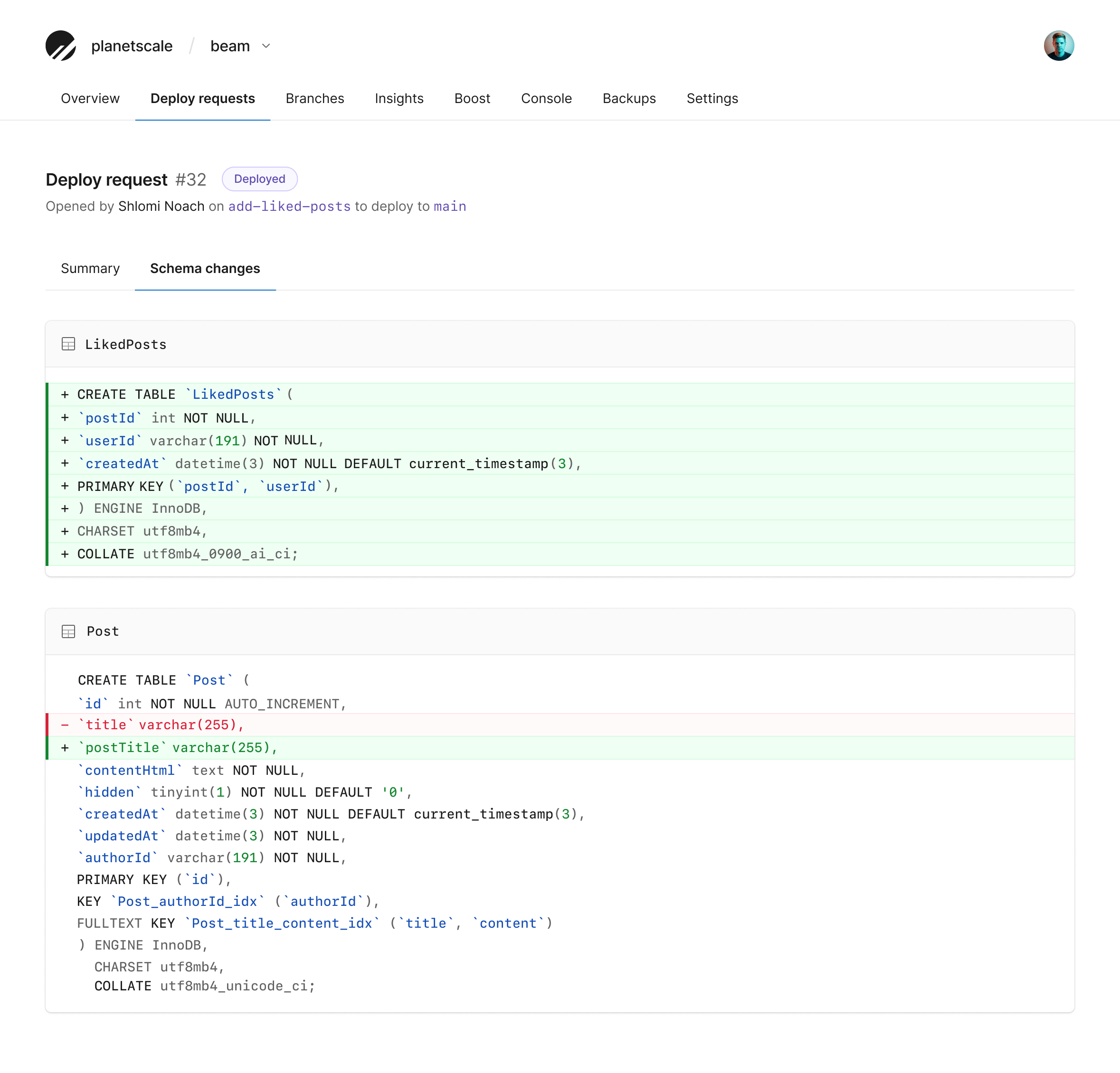
Non-blocking schema changes
Non-blocking schema changes allow you to update database tables without locking or causing downtime for production databases. For example, a direct ALTER TABLE is a blocking operation, which renders the table completely inaccessible, even for reads. One way to ensure you do not cause downtime for your application is to use an online schema change tool. You can read this comparison of online schema change tools or how online schema change tools work. With deploy requests in PlanetScale, an online schema change tool is built-in.
Historically, adding a column to a large table has been seen as a possibly problematic change, but it is safe in PlanetScale with non-blocking schema changes. Database maintenance windows are a thing of the past. Not only are they bad for users and businesses, but they also cause changes to be often batched up, which gets us in trouble because we are releasing multiple schema changes at once that are harder to test and verify.
Gated deployments
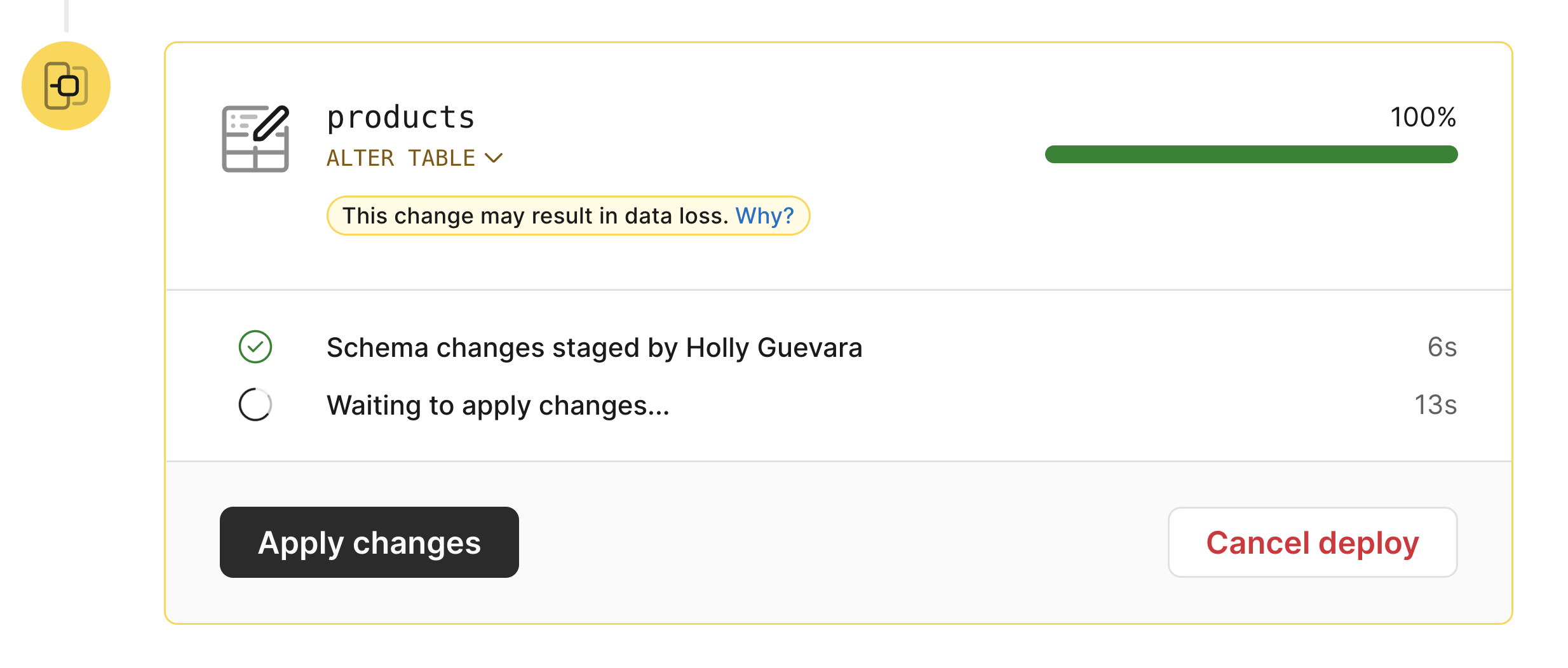
As part of our non-blocking schema change process, instead of directly modifying tables when you deploy a deploy request, we make a copy of the affected tables and apply changes to the copy. We get the data from the original and copy tables in sync. Once complete, we initiate a quick cutover where we swap the tables. Some schema migrations can take less than a minute, and some can take a more extended period of time. Deploying a schema change can take several hours for very large or complex databases.
In some situations, you might not want a schema change to cutover immediately when the deployment process completes, such as when a schema migration completes outside your work hours. You want to be a part of the process to monitor the change and ensure no issues. With Gated Deployments, you can start the deployment process by adding your deploy request to the queue. Once it is done, you can hold off on the cutover. Instead, when it is safer to make the change, you can click a button to swap the tables and complete the deployment.
Revert
What happens when you change a schema and things don't go as planned? We know as developers that nothing happens as we expected 100% of the time. Bad migrations occur all the time. We shouldn't be scared of them. Instead, we should have tools that help us deal with bad migrations.
The revert feature in PlanetScale allows us to go back in time to revert a schema migration deployed to your production database and, in many cases, even retain lost data.
This is possible because of VReplication in Vitess, the database clustering and management system that powers PlanetScale databases alongside MySQL. VReplication uses a lossless sync in the background between valid states of the database. It copies data from the source to the destination table in a consistent fashion. VReplication's implementation is unique because it allows us to go down to the MySQL transaction level, ensuring no data is lost and that your database schema returns to its previous state before the schema change. If you want the behind-the-scenes look at how this is possible, check out this blog about how schema reverts work.
Insights
Some tools use abstractions to improve the developer experience. Insights is the opposite; it is a complexity revealing tool. Insights is PlanetScale's in-dashboard query performance analytics tool. It is built into the platform and doesn't require extra setup to monitor the performance of every database query.
This is useful for safety because it allows you to monitor query performance anytime. What if you release a schema change and notice your users experiencing degraded performance? There could be many causes for this up and down the stack. With Insights, you can quickly confirm if one of your database queries is the cause. It gives you the safety to make schema changes and perform queries while ensuring they do not have problematic database performance.
Tip
Insights will surface SQL comments on queries, so you can tag your queries with additional information to track down where they came from. You can see how to add SQL comments in Laravel or Ruby on Rails.
Unless you deeply understand the inner workings of a database, it can be hard to know precisely how some queries will perform. There are the basics, like understanding how an index can improve performance or that you should only SELECT the information you need. But often, our ORMs create queries that we might not fully understand. Having built-in query performance metrics gives us the safety of knowing we do not have problematic queries in our applications.
For example, a developer noticed they were reading a lot of data. The data in Insights clearly showed that full table scans were occurring on specific queries, which made it clear to the developer that their schema could benefit from adding an index. Insights allows you to focus your database performance optimization work.
Automatic backups
Having to use a database backup is the last resort, but it is a necessary one. PlanetScale allows you to create a branch with the data from a backup, test the branch, and when you are ready, promote it to production. The following checklist helps you walk through this process:
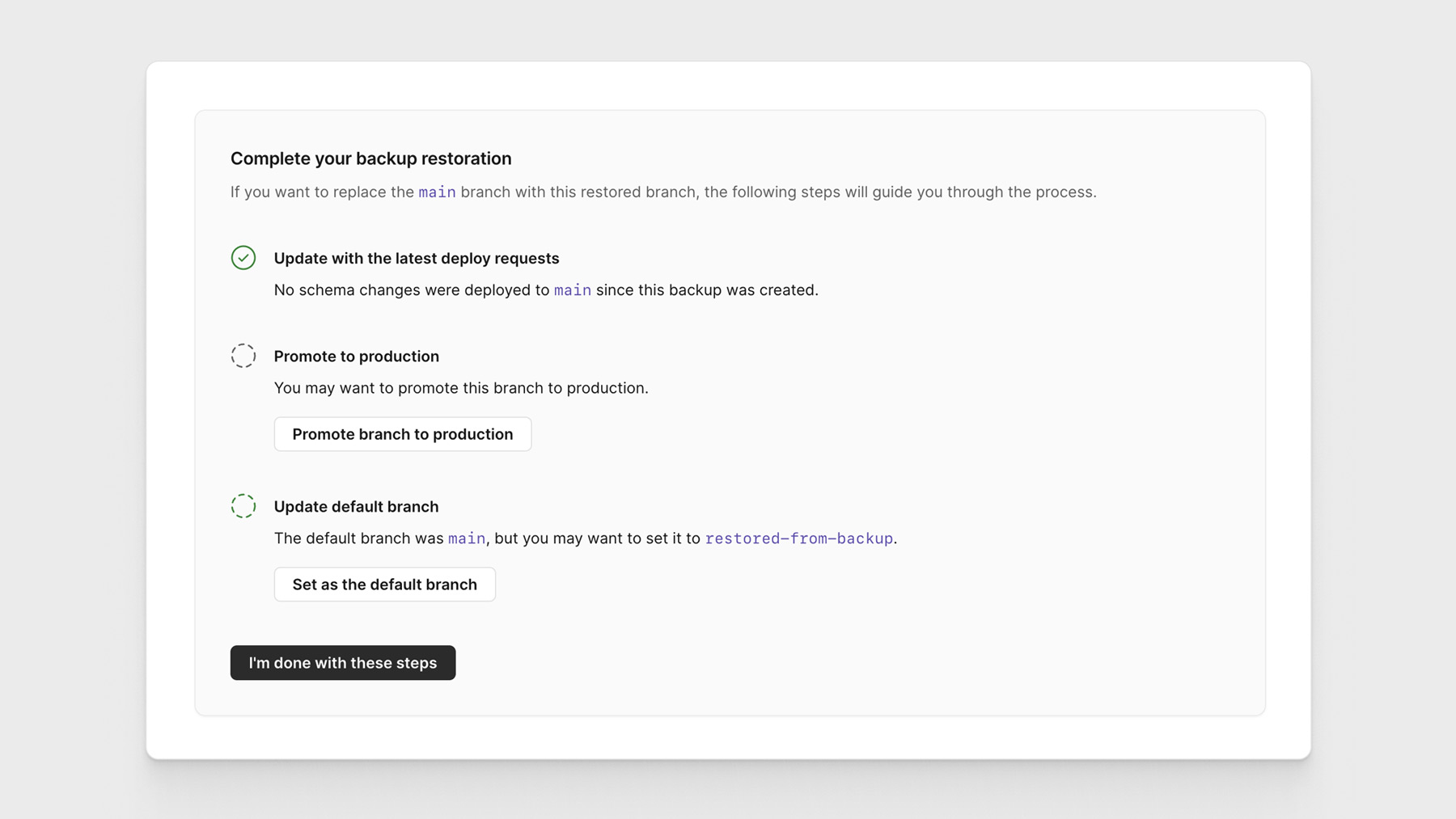
Base plans include a backup every 12 hours, but you can easily change the schedule with a few clicks and create manual backups from the UI.
Going forward with safe database schema changes
As a core tenant of developer experience, you should never have to decide between safety and shipping more features. Hopefully, this blog post informed you how database schema changes could safely be made inside and outside PlanetScale. If you are interested in safety features in different frameworks with excellent developer experience, check out our blog posts on Laravel and Ruby on Rails safety features.