When you leave your house, go to sleep, or go do work in the yard, you lock your door. Maybe you have a gate or fence you lock too. Without these, anyone can waltz into your house and snoop around.
Row Level Security (RLS) can be attractive to developers for numerous reasons, but the foot-guns and gotchas in RLS often outweigh the benefits. You probably want to keep your doors locked.
Friends and family: Managing access
RLS for Postgres lets administrators define security policies in their database, instead of the application layer. Let's imagine your house is your database, and the rows, tables, and data are like the things inside.
When your friends or family come over, you give them keys to every drawer they are allowed to have access to. Maybe everyone gets access to the silverware, but only the family can access your laundry room.
This is similar to how policies work in RLS. The rules for who gets which keys are your policies. If a user passes a policy rule (has the key) then they are allowed to access the data. At a very small scale, this can seem like a great idea. Anyone can access your database however they want and your policies ensure they aren't seeing things they shouldn't.
Testing and scaling these policies as your database grows becomes near impossible. For every new feature in your application, you must ensure your RLS policies are protecting the correct rows. Remembering to add these policies can be cumbersome, especially when they need to be manually synced to your codebase.
RLS fundamentally exists to protect your data. If you mess up even a single policy however, your data becomes exposed. Managing access in the same location your code lives is much easier than remembering to write a new policy every time a new table, column, or feature is added to your product.
The party: Managing connections
Postgres uses a process-per-connection architecture. Each new user connecting to your database directly with their role is like a new person coming into your house. At first it's fine, but once you have 100 people it gets crowded pretty quick.
PgBouncer is a connection pooler that reuses a small number of direct connections to your database while letting many clients connect to it. When using PgBouncer with RLS, you lose the upstream identity of the client.
The traditional way of solving this is using local variables instead of roles to define RLS policies. You define a policy that reads from a session-local variable instead of checking the Postgres role:
CREATE POLICY user_isolation ON orders
FOR ALL USING (user_id = current_setting('app.tenant_id')::bigint);
Then wrap every transaction in your application to set that variable:
BEGIN;
SET LOCAL app.tenant_id = '1234';
SELECT * FROM orders;
COMMIT;
This requires a lot of extra application code to manage all the different local variables attached to each and every transaction (1). If SET LOCAL is omitted, current_setting() returns an empty string or throws an error depending on how your policy is written.
Annoying neighbor: Attack Surface
You go out to get your mail and you find your neighbor standing over your mailbox trying to open it over and over. You try to tell them that one is yours and to let you in, but they are having none of it. Now you have to sit and wait until they get bored and figure out they don't have the right key.
RLS acts like an extra WHERE clause appended to your queries. Unless the user lacks read permission on a table, their queries will still run even if no data is returned. On complex joins or queries lacking indexes, this can hurt database performance.
If a malicious user starts retrying a query over and over, RLS will make sure they don't see any data, but cannot stop them from running the query itself. Relying on RLS to completely protect your tables burns valuable CPU cycles and can potentially starve your other, honest users.
Any user of your application, particularly in situations where you do not have sufficient rate limiting in place, can DDoS your database simply by hitting an API endpoint. This is preventable by checking authentication to see if a user is allowed to run a query, without relying on RLS to manage your security for you.
A large keyring: Performance Implications
Every time your friend goes to get a Diet Coke, they need to find the fridge key on their very large key chain. This wastes valuable time sifting through all the different keys and trying each one, so instead they mark the key so it's easier to find next time they go to the fridge.
RLS policies are generally executed per row (2), meaning any function or complex logic will run for each row scanned. This can be solved by wrapping functions into subqueries. Setting up a simple benchmark, we can see the difference between RLS, RLS cached, and with RLS disabled. If you want to try it yourself, you can use this benchmark repository.
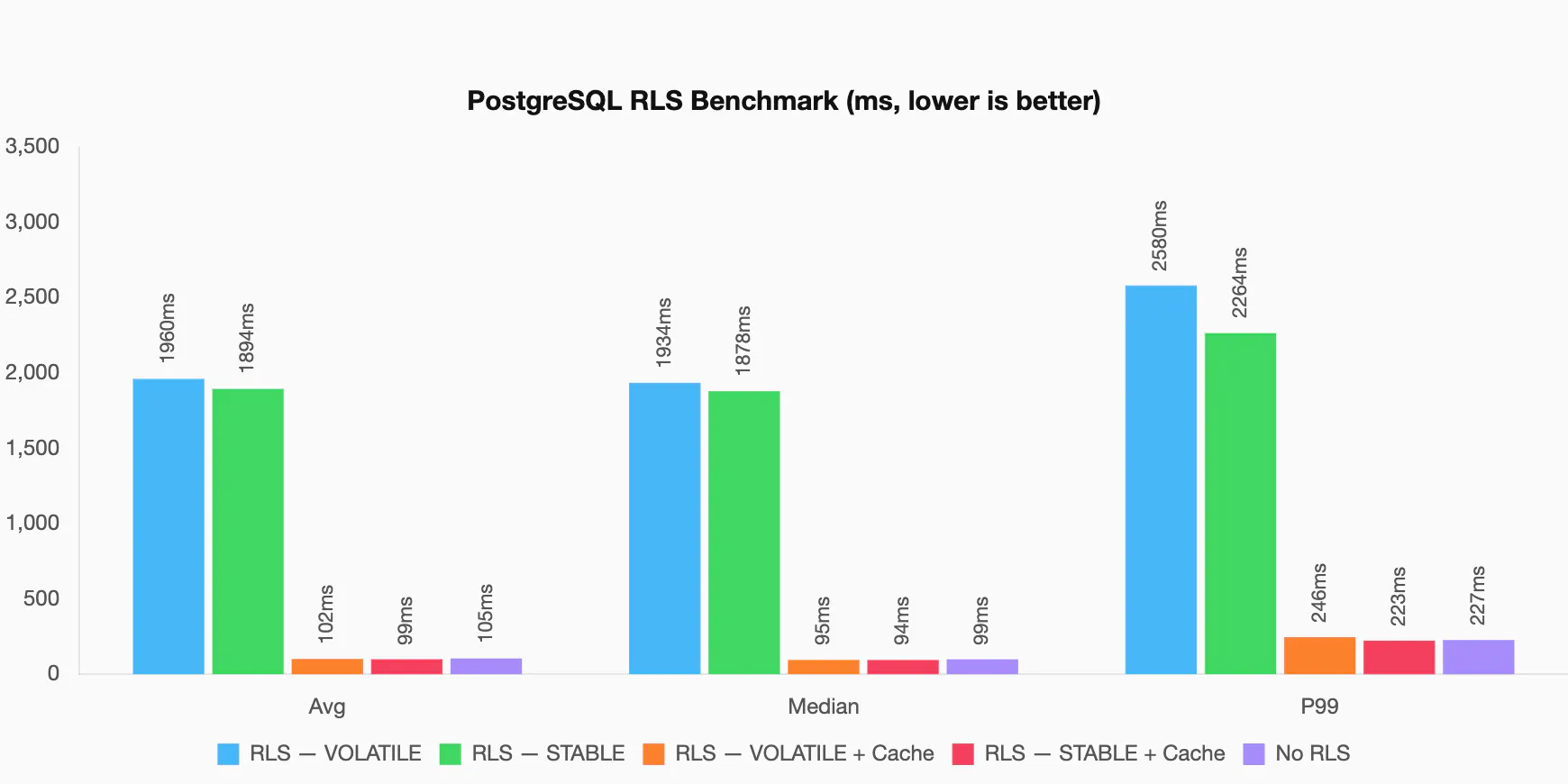
For this benchmark, we tested 5 different setups. Two different functions that are called from two different policies, and one without RLS at all.
- RLS with a
VOLATILEfunction - RLS with a
STABLEfunction - RLS with a
VOLATILEfunction + cache - RLS with a
STABLEfunction + cache - No RLS
A volatile function is defined with the keyword VOLATILE that tells Postgres the function may modify data or return different values upon successive calls. This is the default mode for a new function in Postgres.
CREATE OR REPLACE FUNCTION get_current_role()
RETURNS TEXT
LANGUAGE SQL
VOLATILE
SECURITY DEFINER
AS $$
...
$$;
The other option is to use STABLE in our function definition. Stable functions cannot modify data, and are expected to return the same value for successive calls within the same transaction. When using RLS however, Postgres does not cache the value when evaluating the policy on each row during queries. In order to successfully cache the result across each policy evaluation, we need to trick Postgres.
When we wrap the function call in a SELECT, Postgres creates an InitPlan query node type. By default, anything after the USING keyword is executed as a SubPlan type, where Postgres expects that the outcome can change row to row. This is desired as that is what we are checking; for every row, should the user be allowed to fetch it.
An InitPlan is only run once per execution of the outer plan, and cached for reuse in later rows of the evaluation. Using EXPLAIN, we can see how the different policy definitions change the estimated cost.
-- RLS without subquery: no InitPlan, high cost
CREATE POLICY tenant_isolation ON orders USING (tenant_id = current_setting('app.tenant_id')::bigint AND get_current_role() = 'admin');
EXPLAIN:
Aggregate (cost=34828.68..34828.69 rows=1 width=40)
-> Index Scan using orders_tenant_id_idx on orders (cost=0.43..34826.20 rows=495 width=6)
Index Cond: (tenant_id = (current_setting('app.tenant_id'::text))::bigint)
Filter: (get_current_role() = 'admin'::text)
-- RLS with subquery: Initplan caches result, lower cost
CREATE POLICY tenant_isolation ON orders USING (tenant_id = current_setting('app.tenant_id')::bigint AND (SELECT get_current_role()) = 'admin');
EXPLAIN:
Aggregate (cost=10095.69..10095.70 rows=1 width=40)
InitPlan 1
-> Result (cost=0.00..0.26 rows=1 width=32)
-> Index Scan using orders_tenant_id_idx on orders (cost=0.43..10092.95 rows=495 width=6)
Index Cond: (tenant_id = (current_setting('app.tenant_id'::text))::bigint)
Filter: ((InitPlan 1).col1 = 'admin'::text)
The cost= in the explain rows is Postgres' guess at how expensive a query will be to run, in arbitrary units. The first number is the estimated startup cost; or how expensive it is to do the sorting and filtering of the query before returning rows to the user. The second number is the estimated total cost, including fetching all the rows. The rows= and width= are how many expected rows the query will return, and the width of those rows respectively.
When Postgres doesn't think it can cache the inner query, the cost is over 3x higher than if it would have been able to. In reality, the actual latency difference is much larger than 3x as seen in the chart above.
When Postgres doesn't cache expensive functions in your policy definitions, RLS becomes expensive overhead. RLS can be just as fast as if you weren't using it at all in some scenarios. The issue is that RLS becomes yet another layer of code that needs to continuously optimized, where small mistakes can cause large performance hits.
It's your house: Permission ownership
It's your house, you obviously have the keys to everything, but what if you weren't supposed to?
Every Postgres table has an owner. Normally you'd control table and row access on a per-Postgres-role basis, however when you connect to Postgres as the owning role of a table, none of its RLS policies apply. You must explicitly opt in:
ALTER TABLE users FORCE ROW LEVEL SECURITY;
Even this may not be sufficient if you are connected with the Postgres superuser role. Any roles that contain the SUPERUSER attribute will always bypass RLS. This is easy to miss and easy to test incorrectly. Your policy tests might pass under a non-owner role while production traffic runs as the owner.
Making a ham sandwich: Stricter patterns
Let's say your friend Andy wanted to make a ham sandwich. He had access to the fridge and utensils, but not your grocery list. When he made his sandwich, he used up all the mustard, and now you need to go get more. When using RLS, Andy's query can't touch our grocery list. We have to update that separately.
Without RLS this is easy. When using RLS, doing this type of query can add a lot of complexity. Getting the utensils, making the sandwich, and updating the grocery list might not share the same permissions. While rows in one table may be accessible to a user, updating rows in another may not be. Since we own the grocery list, we don't want anyone touching it except in well defined scenarios.
One way to solve this is by using multiple roles and multiple transactions, but this becomes overly cumbersome on our application layer. A better solution would be to add a SECURITY DEFINER function in our database that gives roles access to modify or view data in a well defined way:
CREATE FUNCTION use_ingredients(ingredients text[])
RETURNS void
LANGUAGE plpgsql
SECURITY DEFINER AS $$
BEGIN
-- Runs as the function owner, bypassing Andy's RLS policies
UPDATE grocery_list SET quantity = quantity - 1
WHERE item = ANY(ingredients);
END;
$$;
SECURITY DEFINER causes the function to run as its owner's role, bypassing RLS entirely for that operation. Now you're back to managing security on both RLS and your application layer, ensuring only specific parameters are allowed to pass to this function.
Keeping database functions in version control also becomes difficult. Some migration tools include SQL functions and policies, but are another part of your schema migrations that can cause headaches down the road.
Your application layer also needs to stay in sync with every function it calls in your database. Changing function definitions, names, or return values may require a new database migration, or delicate surgery to ensure a stable update.
End of the day
Once we have managed locking everything under a different key inside your house, who has what keys, who is allowed in, and who is delegating access for who, we find our application code has almost as much logic as if it didn't have RLS at all.
RLS policies themselves are stored in pg_policies inside your database, not in your source code. Most standard migration tools don't track policy changes alongside schema changes. Policy migrations become a separate, manual process, and they drift. A schema change that adds a column or renames a table can silently break a policy that no one realizes is outdated until something breaks in our application, impacting users.
Each query to the database will already need some sort of modifier in your application code to add local variables for user identification when using PgBouncer. Misconfigured local variables could be just as damaging as if RLS wasn't there to begin with.
We still need to check early on if a user has permission to run a query, or else we risk allowing users to degrade our database performance with spam. If we are already checking permissions at the application layer, the benefits of RLS become harder to observe.
Optimizing queries also becomes much harder. Queries are artificially restricted to what they are allowed to see, and need bespoke functions and permissions to get access. This causes our management of source code and database logic to become even harder to manage, between policies, functions, and the mappings between them.
How to do it right
At PlanetScale, we typically recommend against relying on Postgres RLS. There may be occasional useful scenarios, but when implementing RLS correctly at scale, the benefits quickly turn into cons with a higher overhead not only to performance, but also developer experience and complexity.
Application-layer authorization like middleware, ORM-level scoping, or a dedicated permissions table keeps your logic visible, testable, and co-located with the code that uses it.
Your database is more like a warehouse. Don't treat it like your house.
Footnotes
- Note that PgBouncer
pool_modemust be in eithersessionortransaction.statementmode won't work withSET LOCALat all. - The Postgres query planner can sometimes determine that a policy is safe to cache across evaluations on its own. Doing this properly can be a tricky process. Even in our benchmark example, functions that are marked as stable still need to be wrapped in a subquery in order for Postgres to properly cache the result. Each policy is different, and determining the proper optimizations for each one is another layer of complexity in your codebase.