Engineering team velocity is one of our top priorities at PlanetScale, both for our own teams and for all developers using the tools we build.
One of our early goals when building PlanetScale was to make the absolute best schema change process for engineering teams. We've been iterating on this for the past 3 years and are increasingly happy with how easy it is to change our application's schema.
Our main API is a Ruby on Rails application that is connected to two PlanetScale databases. One of these databases contains the majority of our business and user data. The other is a larger, sharded database built to handle the massive scale needed to power PlanetScale Insights.
Our team makes schema changes to these databases nearly every day. We do this through the exact same tooling we've built for our customers. With the addition of our own "GitHub Actions Bot" which automates steps specific to our Rails application. In this post, I'll share our current process for making schema changes at PlanetScale.
Production database schema changes
The majority of Rails applications in the world update their production schema on each deployment. They will run rails db:migrate as part of their CI process immediately before deploying code to production. This process works well for many teams, but tends to suffer from growing pains as both the size of the data and engineering team grows.
There are two primary problems we see develop:
- As data size grows, running schema changes (DDL) directly against production becomes increasingly dangerous and time consuming.
- Larger teams deploying frequently get blocked by each others schema changes and suffer from higher coordination costs.
The cost of having a painful migration process is high. For teams where these problems are most severe, engineers will start finding ways to avoid making schema changes. By either designing their features differently, or abusing json columns instead of a proper schema design.
Fixing the process: The solution to this starts with severing the tie between schema migrations and code. Allowing each to go out independently of each other. There are many of benefits to doing this. The largest being: engineers are now forced to think more deeply about how their code and database schema changes interact with each other.
The next step in fixing the process is introducing an online schema change tool.
Online schema changes
"Online" is a term used in database circles to describe a change that does not require downtime. The Rails community has done an excellent job at building tooling and education on how to complete migrations without downtime. Every Rails developer I know has memorized which schema changes may cause locking. There are even gems that guide us into making changes safely.
Even with all this education and tooling, the problem is not fully solved without a solution at the database layer.
Many applications developers are not aware that there is a whole suite of tooling built by "at scale" companies to handle this problem. These are known as online schema change tools. These tools replace rails db:migrate and run the schema changes in a way so that production traffic to the database is not interrupted. The benefit of this is that application developers no longer need to keep track of which schema changes may cause a table to lock. The schema change tooling will make the change in a way that is always safe, mitigating much of the fear around schema changes.
Most large scale companies you can think of are using some variety of online schema change tools for their migrations.
Here at PlanetScale, the team which maintains the online schema change tooling for Vitess is on our staff. This is also built directly into PlanetScale through our safe migrations feature.
Timing application code with schema changes
With each schema change in the database, it is also crucial to consider how the application layer will handle the change. We can have the best schema change tooling in existence, but if we make mistakes with how our application interacts with the database, downtime can still occur.
A common misconception we see among developers is that they think they can atomically deploy both their schema and application code at the same time. This is not possible. For each schema change made, the application needs to be setup to handle both the current and future schema. Without doing so, errors will ensue.
The perfect workflow for each company involves solutions at both the database and application level.
Our schema change workflow
When developers at PlanetScale are making a schema change, the process begins locally. The application code is modified in a git branch, and any corresponding changes to the database schema are applied in a local instance of MySQL. After local development and testing is complete, they then commit their changes and open a pull request on GitHub.
Pull request bot
We've built a "pull request bot" with GitHub Actions that will detect any schema changes that need to be made as a part of a pull request. When it sees changes, it will create a PlanetScale branch, run the migrations, open a deploy request (PlanetScale's method for making a schema change) and comment the result in GitHub.
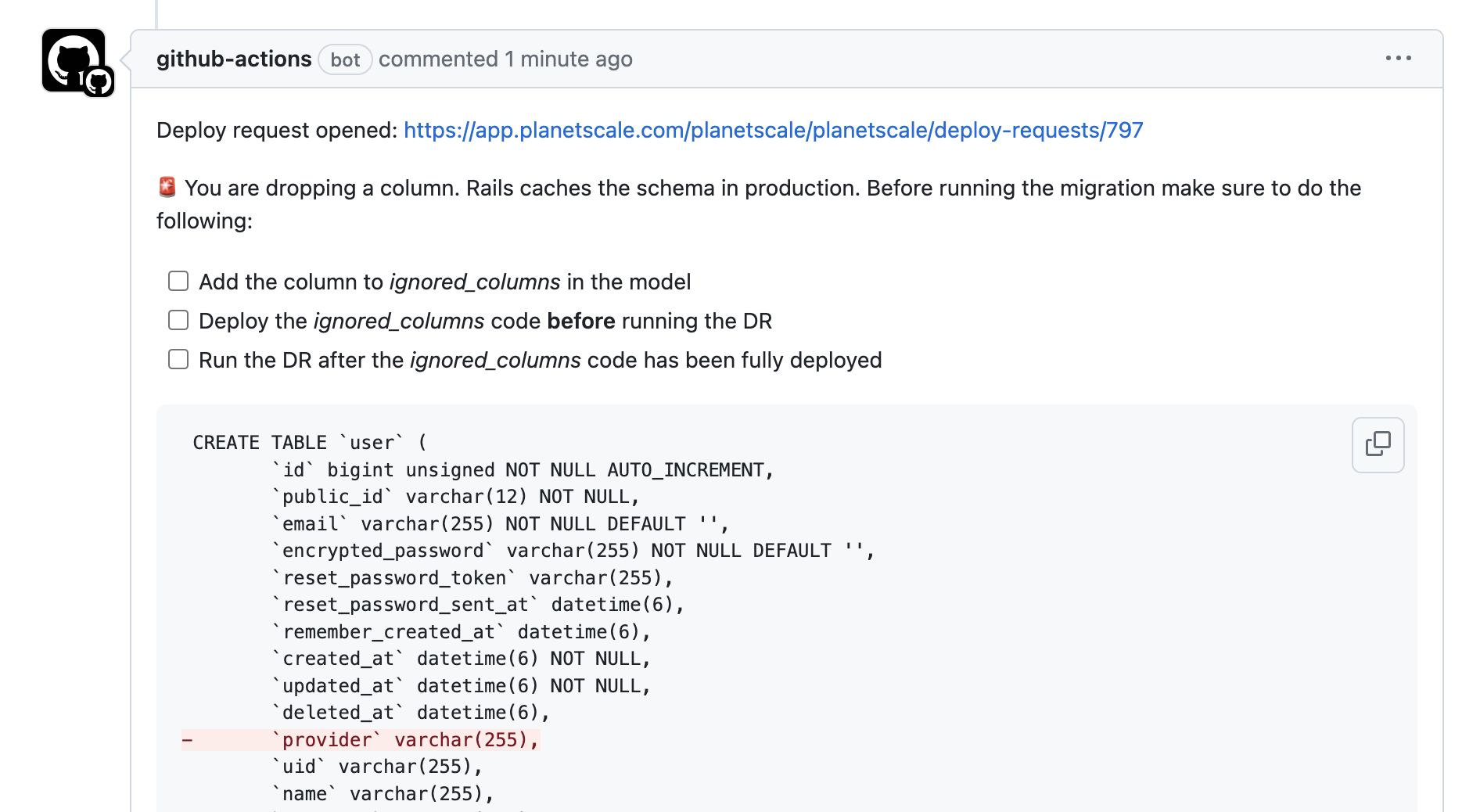
A few notes about this workflow:
- We only create a PlanetScale branch when there are schema changes
- Our CI runs against local MySQL for lowest latency
- We use the
planetscale_railsgem to run the migrations
Each of these steps will vary per application, but the general flow will be similar.
With our bot, we are able to use the PlanetScale API to detect the class of changes being made to the database. The bot then generates comments based on the characteristics of the changes, including instructions for the sequence of steps needed to make the change safely for our application. Each application is different, but they all have similar needs when making schema changes.
- When removing a column, application code must be deployed before the schema is changed
- When adding a column, application code must be deployed after the schema is changed
Note
For a deeper look at how this pattern works, check out our Backward compatible database changes blog post.
The deploy request
The bot automatically opens a deploy request for us and leaves a comment linking to the change in GitHub. This allows our team to review both the schema change as well as the code. Giving full context around why and what is being changed.
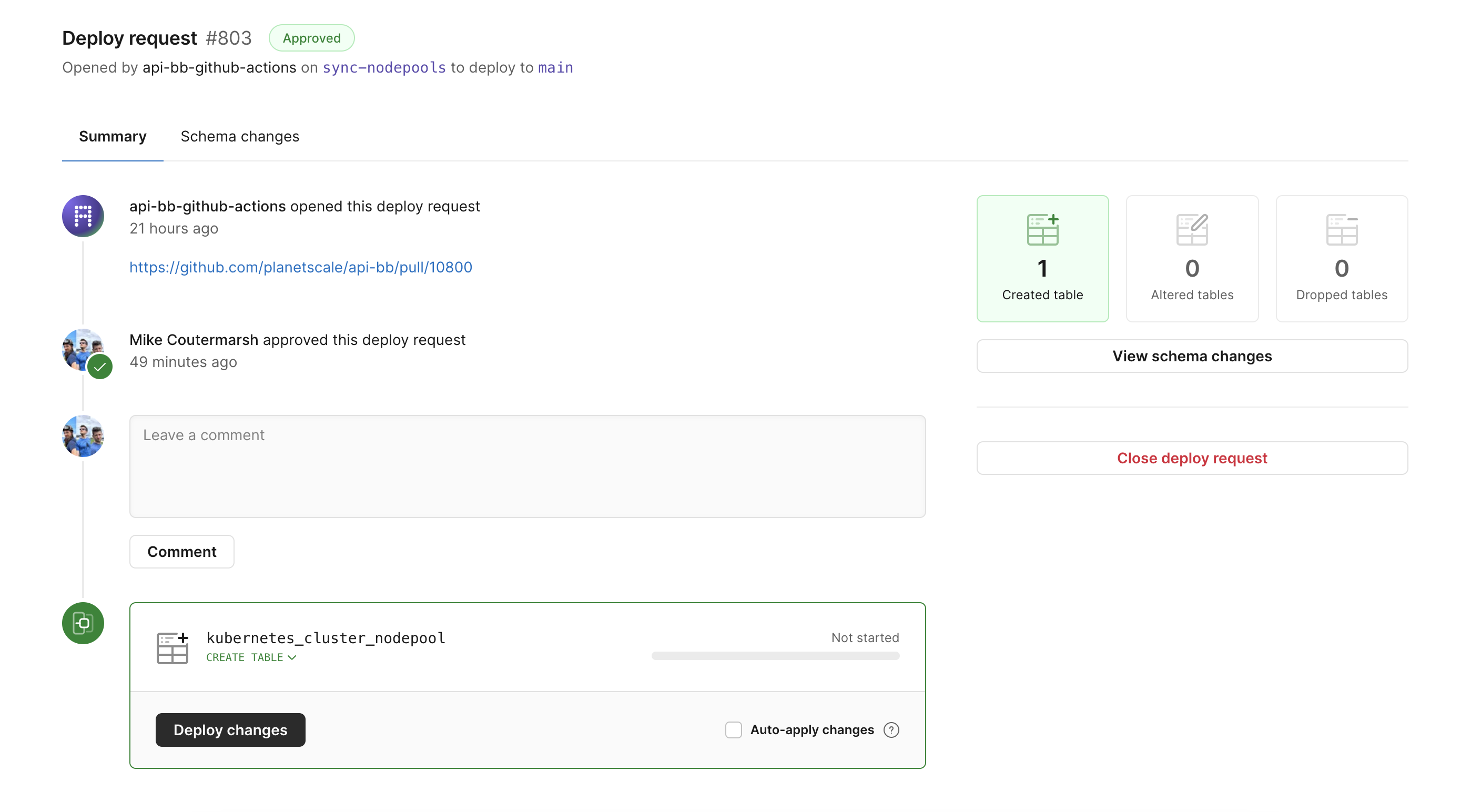
Before the schema change is even deployed, checks are run through a linter to catch any common mistakes.
The deploy request will make the schema changes using a Vitess online migration. This protects production and also allows us to quickly revert the schema change if we notice anything going wrong.
When we have multiple team members making schema changes at the same time, PlanetScale will create a queue for each change. This allows each change to be deployed automatically in the order it was added to the queue. It has safety benefits as well, PlanetScale runs safety checks not only on each schema change, but on the resulting database schema with all changes combined. This protects against mistakes when multiple people are making changes at once.
How can I do this?
By combining our GitHub Actions bot with PlanetScale deploy requests, we've found our schema change process to be delightful. Developers are able to make changes quickly while also feeling confident that the change they are deploying will not impact production.
The bot ties together the online schema change tooling built into PlanetScale, with the specific needs of our Rails application. With these combined, developers can move quickly and confidently.
Our process to deploy code and schema are purposefully separate, forcing our engineers to think through each step of their change. As well as allowing us to move quickly and never have code changes blocked behind another team members unrelated schema migration.
We've implemented our bot using GitHub Actions, however a similar workflow can be achieved with other CI tools as well. On the PlanetScale side, all of the API calls needed are available via the pscale CLI.
We have published many of the key pieces of our workflow in our GitHub Actions docs page. With this page, you can mix and match the examples to fit the needs of your team and application.
If you have a Rails application, we've published instructions directly in the planetscale_rails readme.