Connecting to your PlanetScale Postgres database
Connecting to your PlanetScale Postgres database involves understanding several key components. This page provides an overview of connection options — for detailed instructions, see the linked documentation below.Postgres
Create role credentials with
pscale role, then connect using a connection string.pscale connect is not supported.Vitess / MySQL
Create a branch password with
pscale password, then connect with a connection string or pscale connect.AI assistant integrations
You can expose read-only schema and query capabilities to tools like Claude, Cursor, or Zed through the shared Model Context Protocol (MCP) guide. The CLI configures each tool for you viapscale mcp install --target <claude|cursor|zed>, and the PlanetScale MCP server streams data over a secure, read-only connection.
Roles and credentials
PlanetScale provides two types of roles for database access:- Default postgres role — A near-superuser role with extensive permissions, ideal for administrative tasks and initial database setup. This role should not be used for application connections.
- User-defined roles — Custom roles with specific permission sets that follow the principle of least privilege. These are recommended for all application connections and allow credential rotation without downtime.
{role}.{branch_id}), password (prefixed with pscale_pw_), and database name. Learn more about managing roles and creating credentials.
Connection strings
PlanetScale databases require SSL/TLS encryption for all connections. Connection strings include parameters for the host, port, username, password, database name, and SSL configuration. The port determines the connection method:- Port 5432 — Direct connections to Postgres, bypassing PgBouncer
- Port 6432 — Connections through PgBouncer for connection pooling
Private connectivity
For enhanced security and reduced latency, PlanetScale supports private connectivity that keeps traffic within cloud provider networks:- AWS PrivateLink — Establishes private connections from your AWS VPC to PlanetScale databases without exposing traffic to the public internet. See the AWS PrivateLink documentation.
- GCP Private Service Connect — Provides private connectivity from your Google Cloud VPC to PlanetScale databases. See the GCP Private Service Connect documentation.
Choosing a connection method for your platform
Most JavaScript and TypeScript applications should connect with a standard TCP driver such aspg through PgBouncer on port 6432. This applies to Vercel (with @vercel/functions connection pooling), AWS Lambda, Railway, Render, and long-running servers.
For platforms without reliable TCP pooling, PlanetScale supports the Neon serverless driver over HTTP or WebSockets. Use it for Netlify Functions, Deno Deploy, and edge runtimes where TCP is not available. For Cloudflare Workers, prefer Hyperdrive with pg over the serverless driver when possible.
Understanding Postgres connections
Postgres uses a connection-per-process architecture. Each connection made to a Postgres server spawns a new process, which consumes system resources including memory and CPU. For this reason, it’s important to manage the number of direct connections to keep the system performant. Connection pooling is the primary solution to this challenge. In the Postgres ecosystem, PgBouncer is the most widely-used connection pooler. PgBouncer instances sit between clients and the Postgres server, maintaining a small pool of connections to Postgres while accepting a much larger number of client connections. PgBouncer routes client requests through these pooled connections efficiently.Connection options
PlanetScale provides several ways to connect to your Postgres database:-
Direct primary connections - Connect directly to your Postgres primary server on port
5432. This provides the lowest latency and full Postgres session capabilities. Use this for administrative tasks, long-running operations, and data imports. -
Direct replica connections - Connect directly to read-only replicas on port
5432by appending|replicato your username. Use this for read-only queries that can tolerate replication lag. -
Local PgBouncer (primary only) - All Postgres databases include a local PgBouncer running on the same host as the primary. Connect via port
6432. This is recommended for all application connections to the primary. -
Dedicated replica PgBouncer - Create dedicated PgBouncer instances that pool connections to your replicas. These run on separate nodes and are useful for read-heavy workloads. Connect via port
6432with the PgBouncer name appended to your username. -
Dedicated primary PgBouncer - Create dedicated PgBouncer instances that pool connections to your primary database. These run on separate nodes and provide improved high availability, with connections persisting through cluster resizes, upgrades, and most failover scenarios. Connect via port
6432with the PgBouncer name appended to your username.
Direct primary connections
Direct connections provide the lowest-latency access to your Postgres primary instance.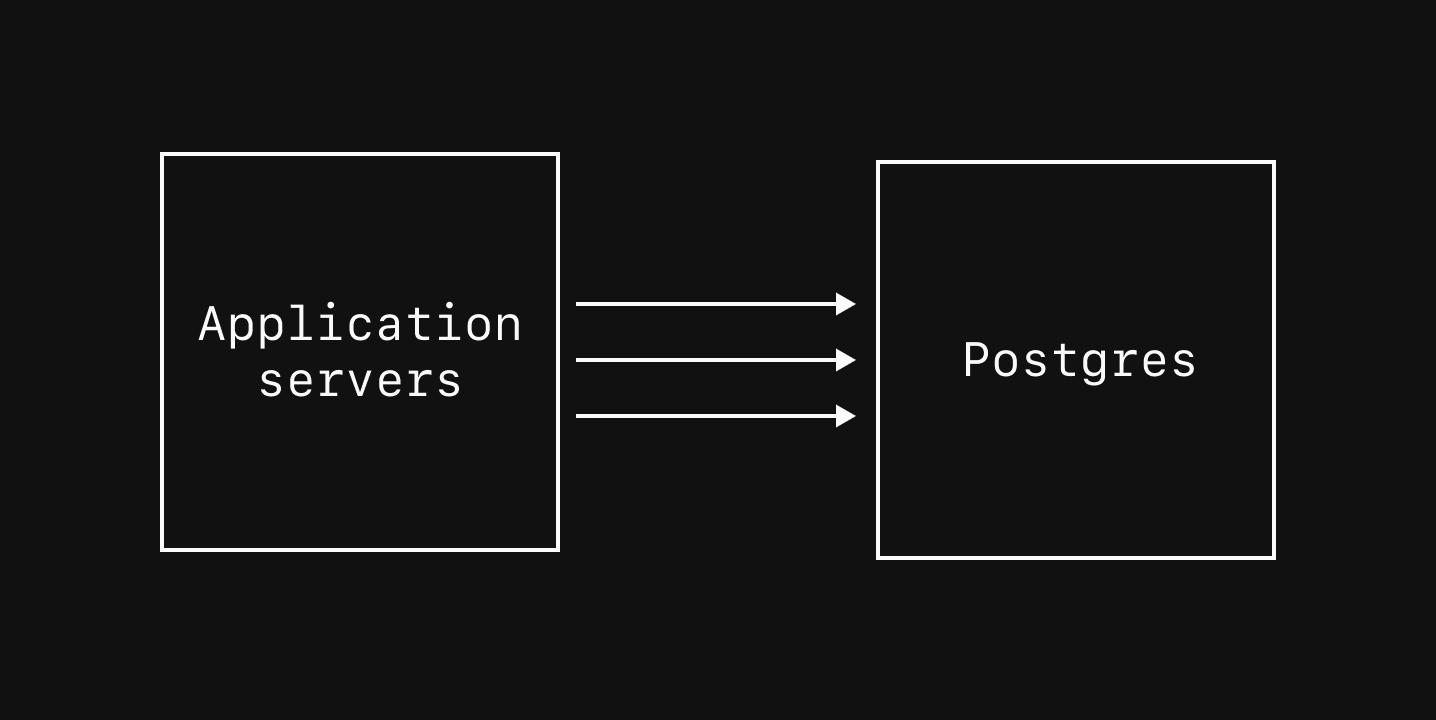
- Administrative tasks, like creating new databases/schemas, manual DDL commands, and installing extensions.
- Long-running operations like
VACUUMs and large analytical queries that are executed infrequently. - Importing data during a migration or other bulk-loading operations.
- When you need features like
SET, pub/sub, and other features not provided by PgBouncer pooled connections.
max_connections to a conservative default value that varies depending on cluster size. To find this value, navigate to the “Clusters” page and select the “Parameters” tab.
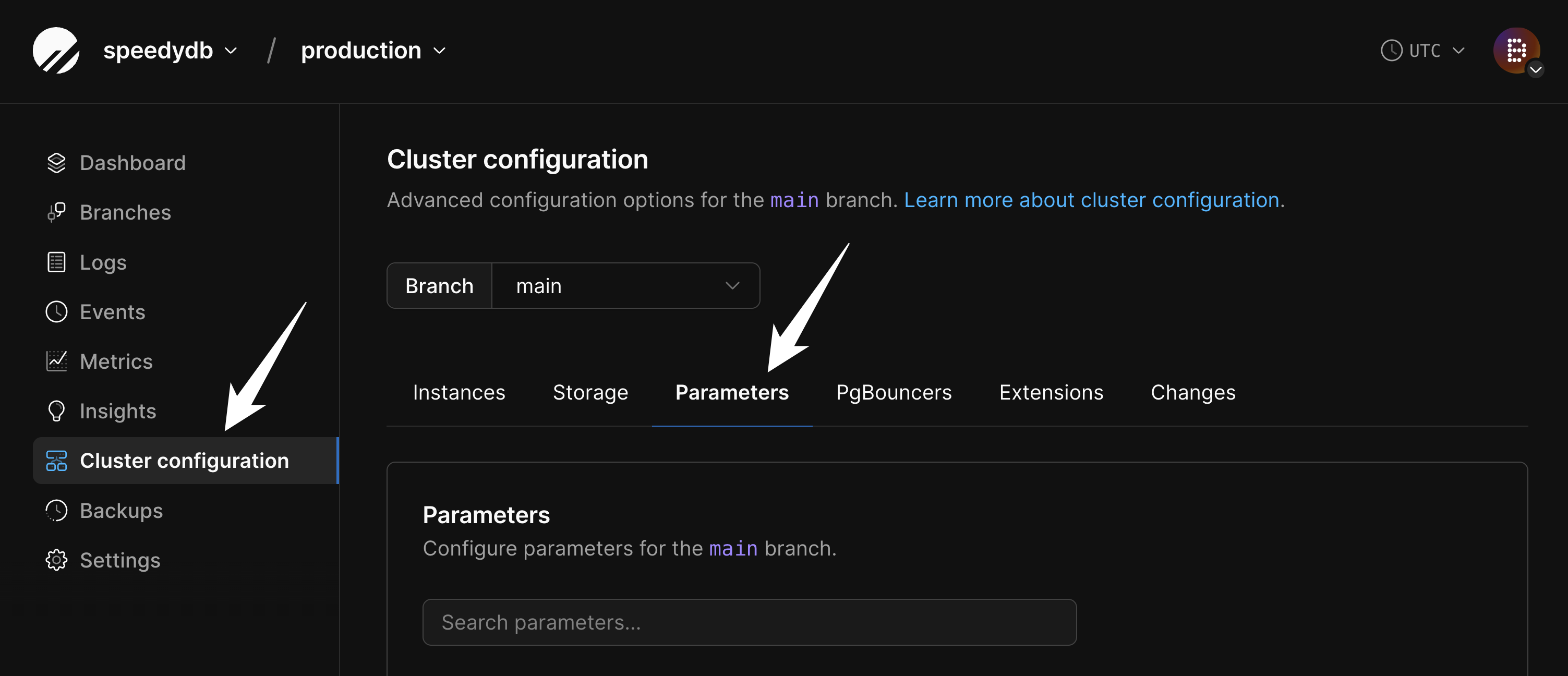
max_connections to view the current configured value. This can be increased if necessary, though doing so requires careful consideration as increasing direct connections can negatively impact performance.
When the max_connections limit is reached, error messages like the following will appear:
Direct replica connections
The main purpose for the default Replicas in a cluster is to maintain high-availability, but they can also be used to handle read traffic. Since replicas are read-only, they are only capable of servingSELECT queries. All write traffic (INSERT, UPDATE, etc) must be sent to the primary.
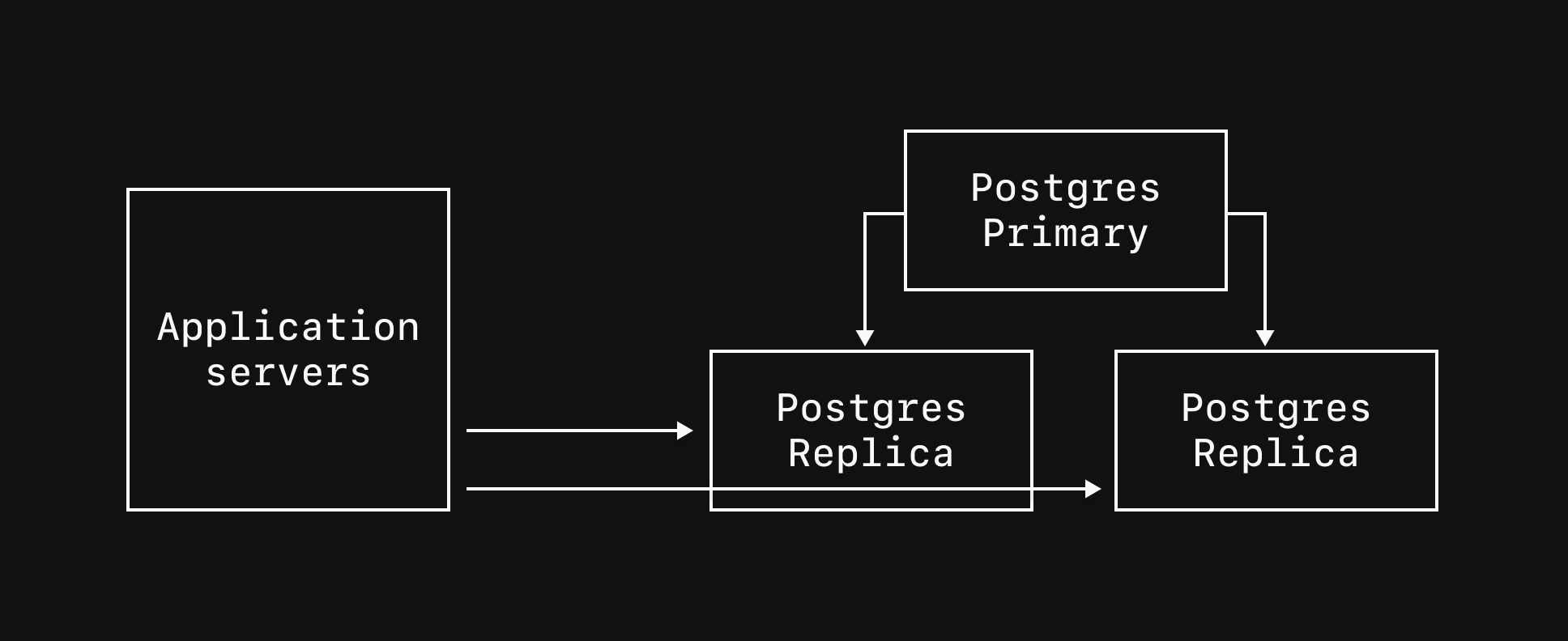
|replica to your credential username and use port 5432. For example:
PgBouncer connections
PgBouncer provides connection pooling for your Postgres database, allowing applications to scale beyond the constraints of direct connections. Connections from application servers should be made via PgBouncer whenever possible. PlanetScale provides three types of PgBouncer instances: All managed PgBouncers run in transaction pooling mode. Session pooling is not offered because it creates a 1:1 mapping between clients and Postgres connections, so it hits the same connection limits as direct connections while introducing additional latency through another proxy layer. If you require session-specific behavior, use a direct connection on port5432 instead of requesting session pooling.
Local PgBouncer
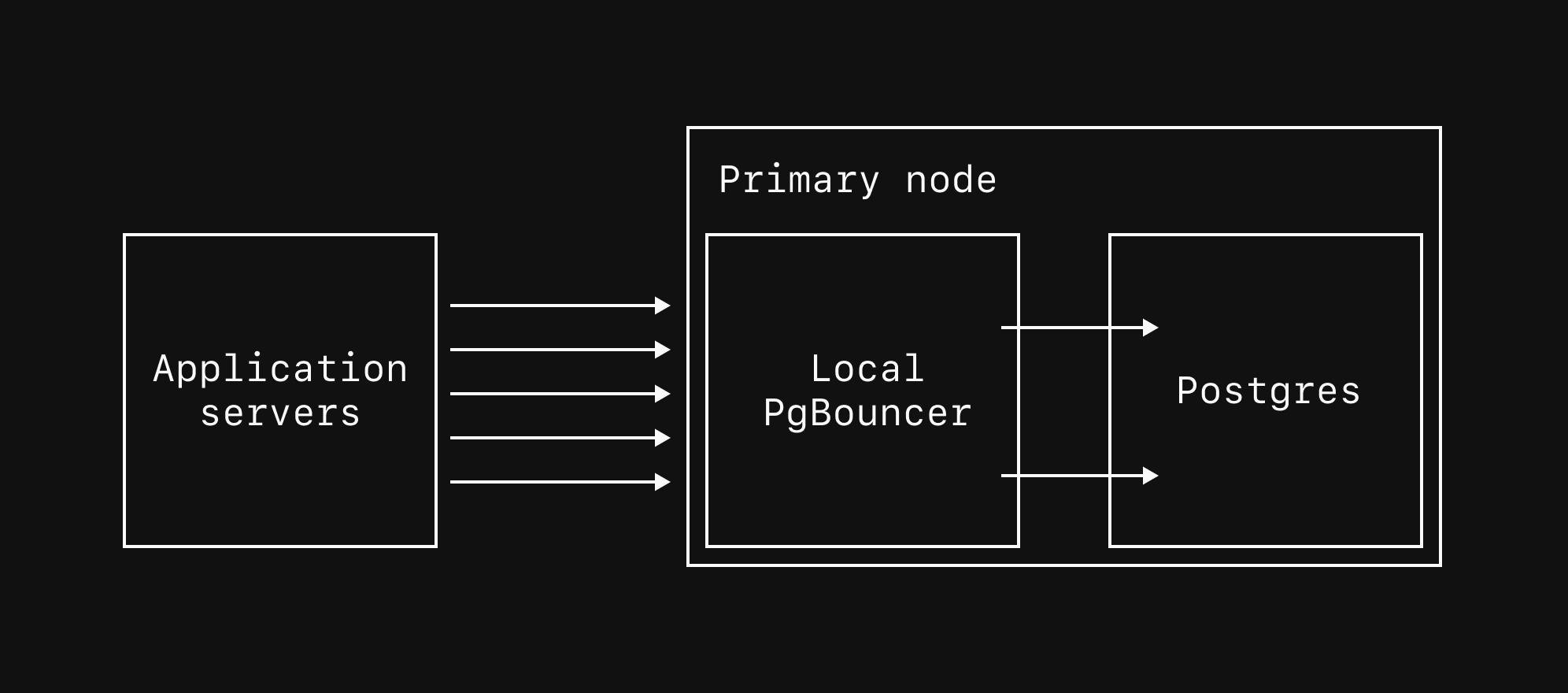
5432 to 6432.
The local PgBouncer only routes connections to the primary. To pool connections to replicas, use a dedicated replica PgBouncer.
Dedicated replica PgBouncer
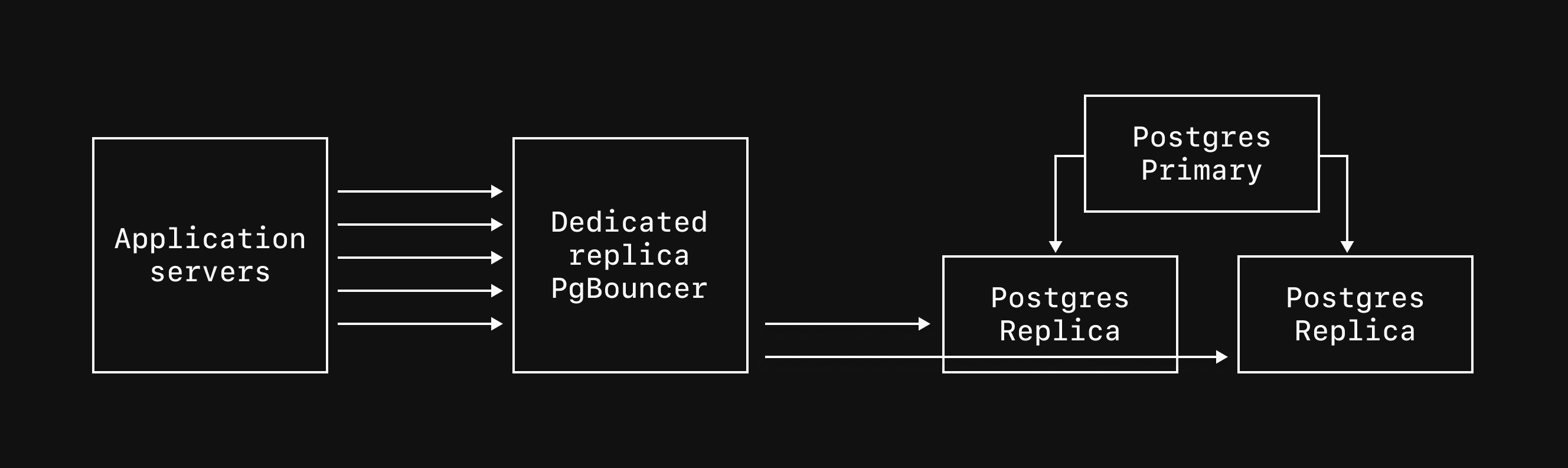
Dedicated primary PgBouncers
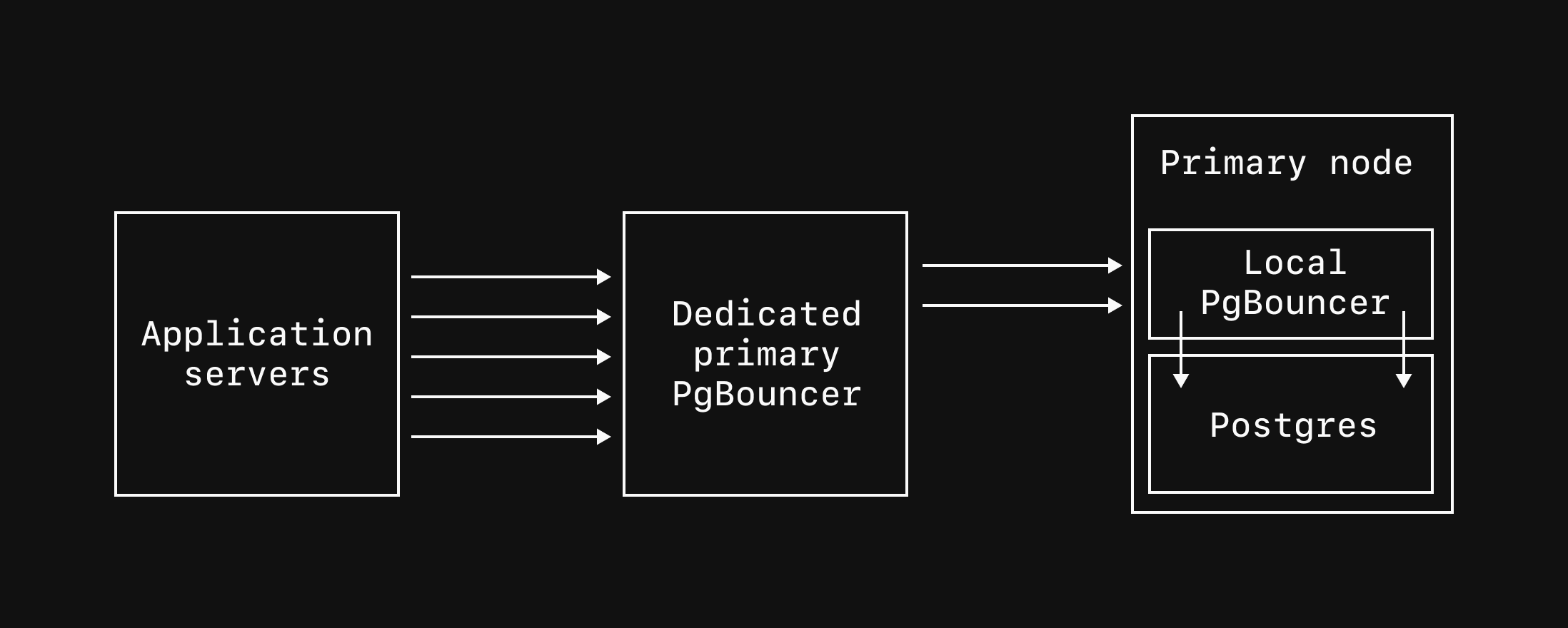
Connecting to dedicated PgBouncers
Connect to replica or primary PgBouncers via port6432 and append the name of the PgBouncer to your username. For example, if your PgBouncer is named read-bouncer, the connection username should be postgres.xxxxxxxxxx|read-bouncer.