Database cluster architecture
The cloud is an inherently failure-prone environment. Servers can experience degraded performance or become unavailable at any time and for unknown reasons. Because of this, we must treat all cloud server nodes as ephemeral. We can embrace failure and build database clusters that are resilient in the cloud environment by understanding our constraints and leveraging the cloud’s elasticity within known and practical limits. Every production database cluster in PlanetScale has a primary and two replicas. This allows us to embrace server failures through failovers. Some consider failovers as a problem, but we see that as a fundamental building block for operating reliable databases. Tolerating the brief disruptions produced by failovers has huge upside: PlanetScale can rapidly deliver changes which continuously increase the quality, reliability, and performance of customer databases.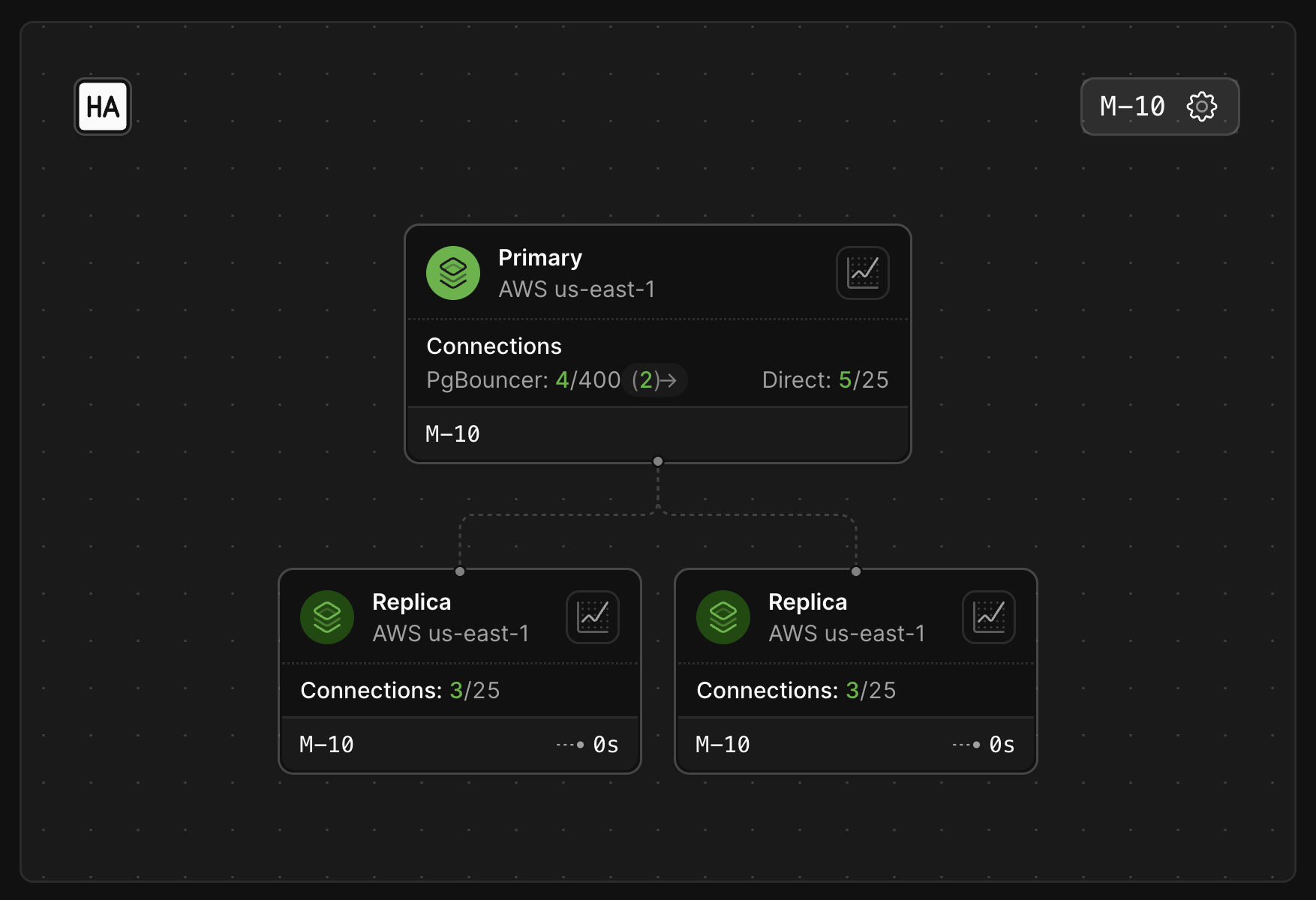
- Replicating data to multiple servers is crucial for data durability, especially in a cloud environment. All data is replicated 3 ways at minimum.
- Each instance is in a distinct availability zone. This means we can be resilient to zone-wide incidents.
- Replicas can receive read queries that can tolerate replication lag. This allows offloading work from the primary, reserving it for writes and critical reads.
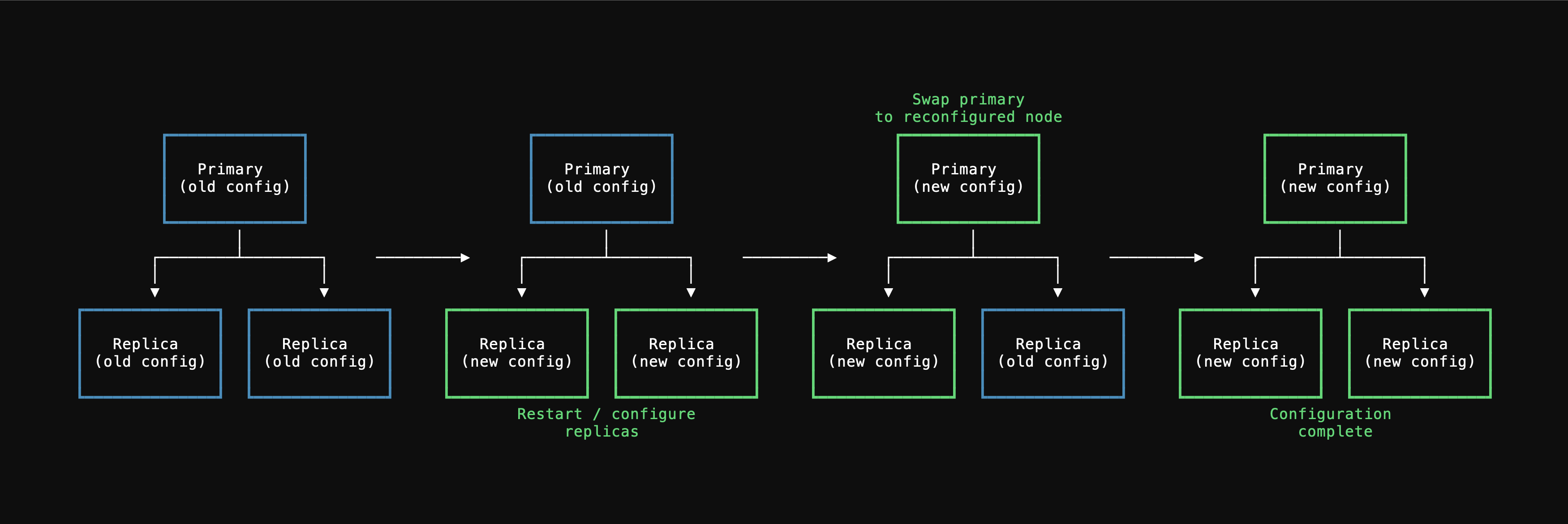
- In the event of an incident in the primary’s availability zone, we can failover to a healthy replica in a different availability zone. Likewise, when performing a planned upgrade on the primary instance, we first promote a healthy replica to become primary before upgrading the old primary (now demoted to a replica) Failovers take on the order of seconds, not minutes or hours, getting you back online quickly.
Continual improvement
Most Postgres database platforms shy away from version updates and other incremental improvements due to their disruptive nature. Many services require minutes or even hours of downtime to handle this. The PlanetScale philosophy is different. To give our customers the best possible Postgres experience, we believe that regular version bumps, bugfixes, and quality-of-life improvements are necessary. Image upgrades are performed in cases of emergencies (such as patching security issues) or when initiated by the user via the PlanetScale application or API. When these upgrades occur, they require node failovers, which lead to a short period of database unavailability (seconds).The ideal Postgres experience
PlanetScale provides a well-rounded, out-of-the-box Postgres experience while also giving users what they need to tune it to their liking. This shows up in several aspects of the product:- Each database is given custom default tunings depending on CPU, RAM, and disk characteristics. Users can adjust and carefully monitor the effects of their own changes via the Clusters and Insights pages.
- In addition, we tune
effective_io_concurrencybased on the IOPS values specific to your database. For example, each Metal node type has unique and very large IOPS capacity, so we customize it on a per-instance-type basis. But we also let you experiment with your own tunings. - Users have lots of freedom to customize their Postgres roles via our UI, giving them fine-grained control over permissions.
- Both direct-to-Postgres and PgBouncer connections are available by default. Each has tradeoffs, and we let you choose what makes the most sense for your applications.
Minimizing the impact of configuration changes
PlanetScale takes the database unavailability produced by upgrades extremely seriously. We monitor this downtime across the fleet, and make continual efforts to reduce its impact. We apply context-appropriate, rather than a one-size fits all, upgrade strategies to ensure that a given upgrade takes no more time than absolutely necessary. PlanetScale allows manual configuration of a number of parameters via the clusters page. Each configuration change falls into one of two categories:- Reloadable changes: The change can be applied with no need to restart Postgres. When applying these, there is zero downtime.
- Restart-required: Postgres requires the server be restarted for the change to take effect. When applying these, you can expect a brief period of server unavailability due to the restart.
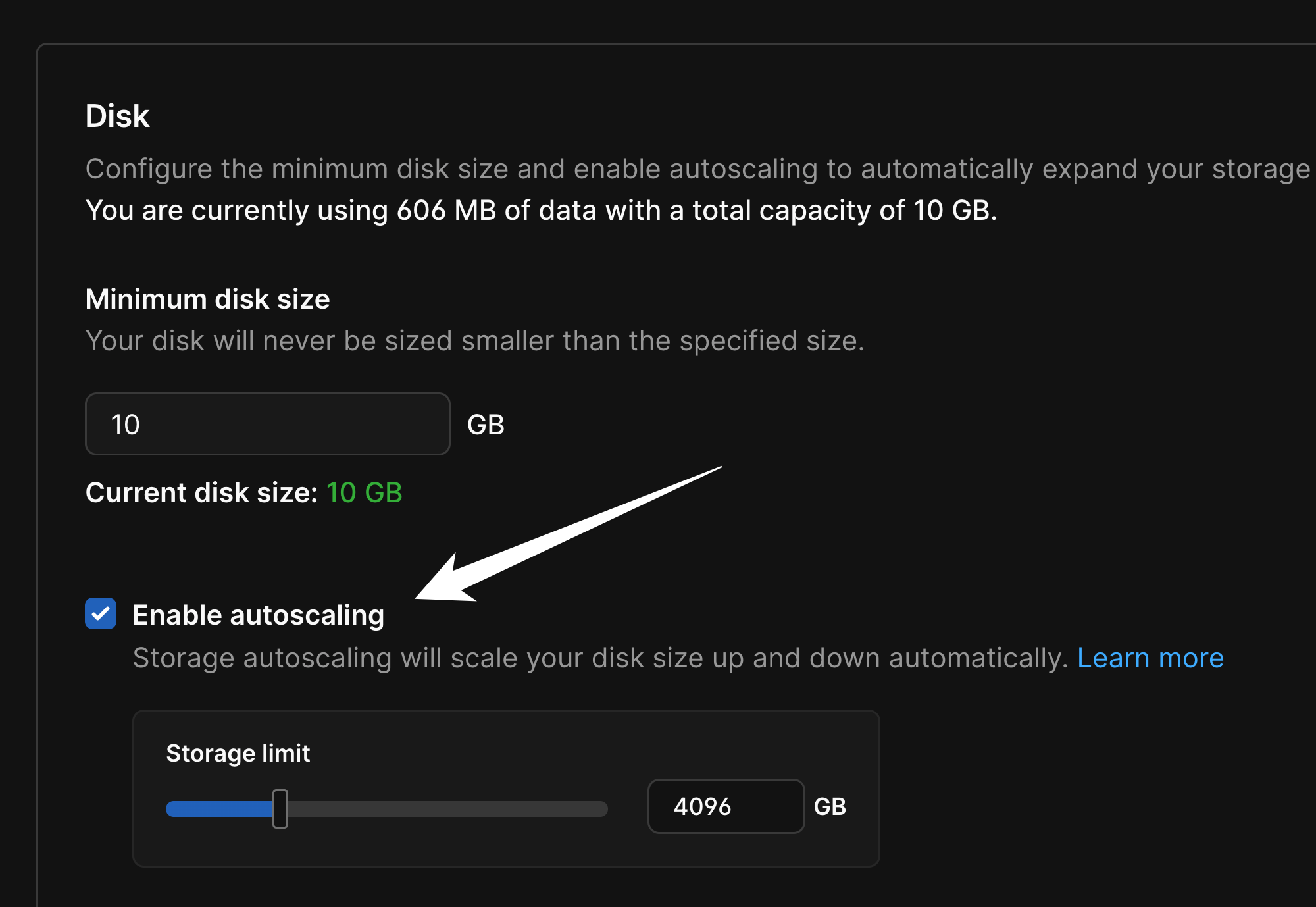
Database cluster sizing
PlanetScale does not support autoscaling of CPU and RAM. Instead, users are put in the driver’s seat to choose the hardware the database runs on, and are given tools to closely monitor performance and adjust resources when needed. There are two main ways to increase the compute capacity of a cluster: Adding replicas and resizing all nodes.Adding Replicas
Each production PlanetScale database (excluding single node) has 1 primary and 2 replicas. In this standard configuration, read traffic can be routed to a replica rather than relying on the primary for everything. It’s important not to over-stress your replicas, however. If all three nodes in the cluster experience too much strain, failovers will be more disruptive, since the cluster will temporarily go from 3 nodes down to 2. Reads from replicas must also be able to tolerate replication lag. If you only need to increase the read capacity of the cluster, a good option can be to add 1 or several additional replicas. This is done through the Clusters menu, and has no negative impact on the other nodes when being added.Resizing a cluster
Resizing a cluster leads to database connections being terminated. Therefore, it’s important for your application to have connection retry logic. Consider the case where you need to upgrade from anM-160 database cluster to an M-320, doubling the compute resources of each node.
After applying the upgrade, three new M-320 nodes are created.
These are caught up with the primary through a combination of a backup restore and data replication.
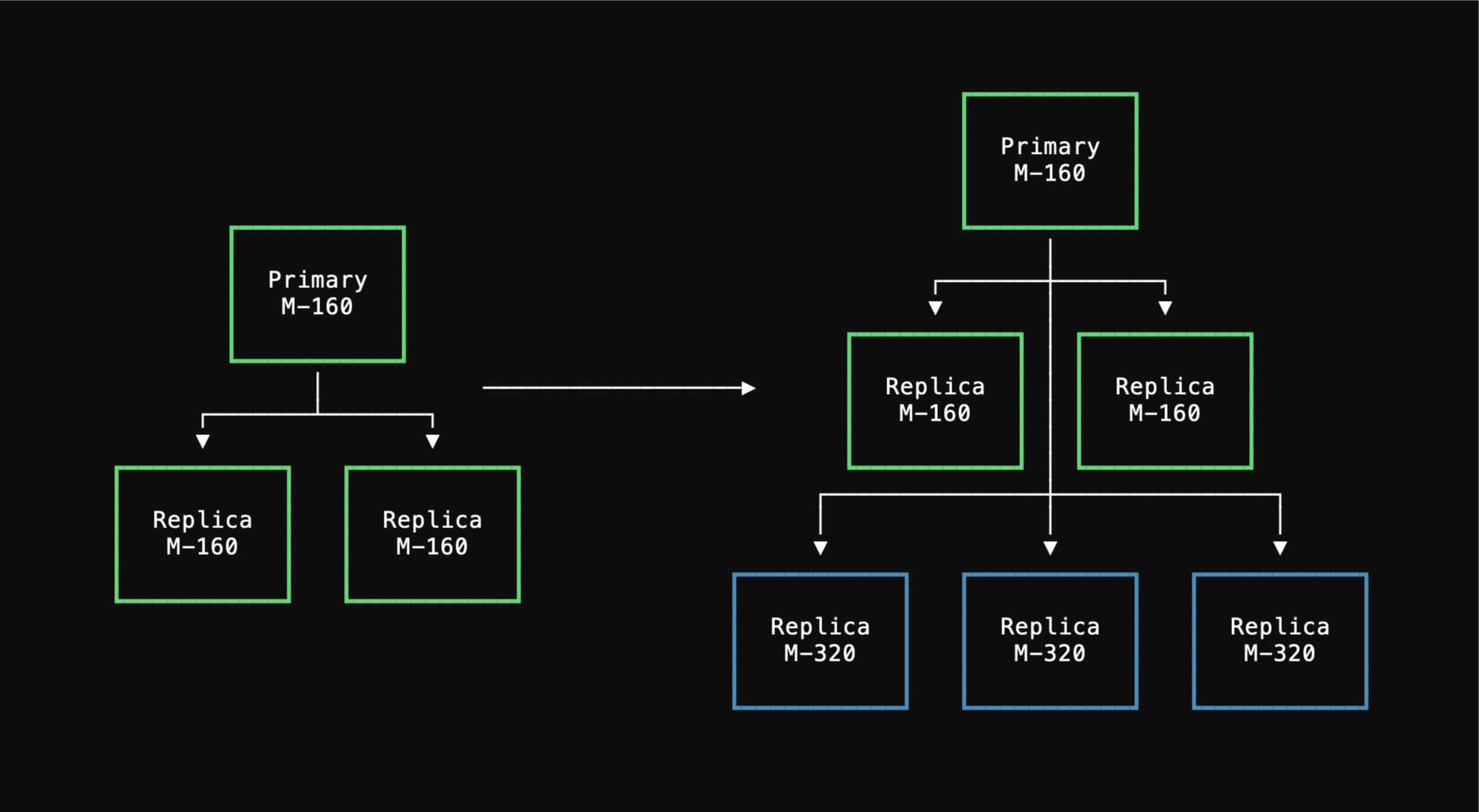
M-320 replicas are sufficiently caught up, the operator transitions primaryship to one of the new M-320 nodes.
After this, the old M-160 replicas are decommissioned, using the new ones for all replica traffic.
During each node replacement, connections to the decommissioned node will be destroyed.
New connections will need to be made to re-establish with one of the new nodes.
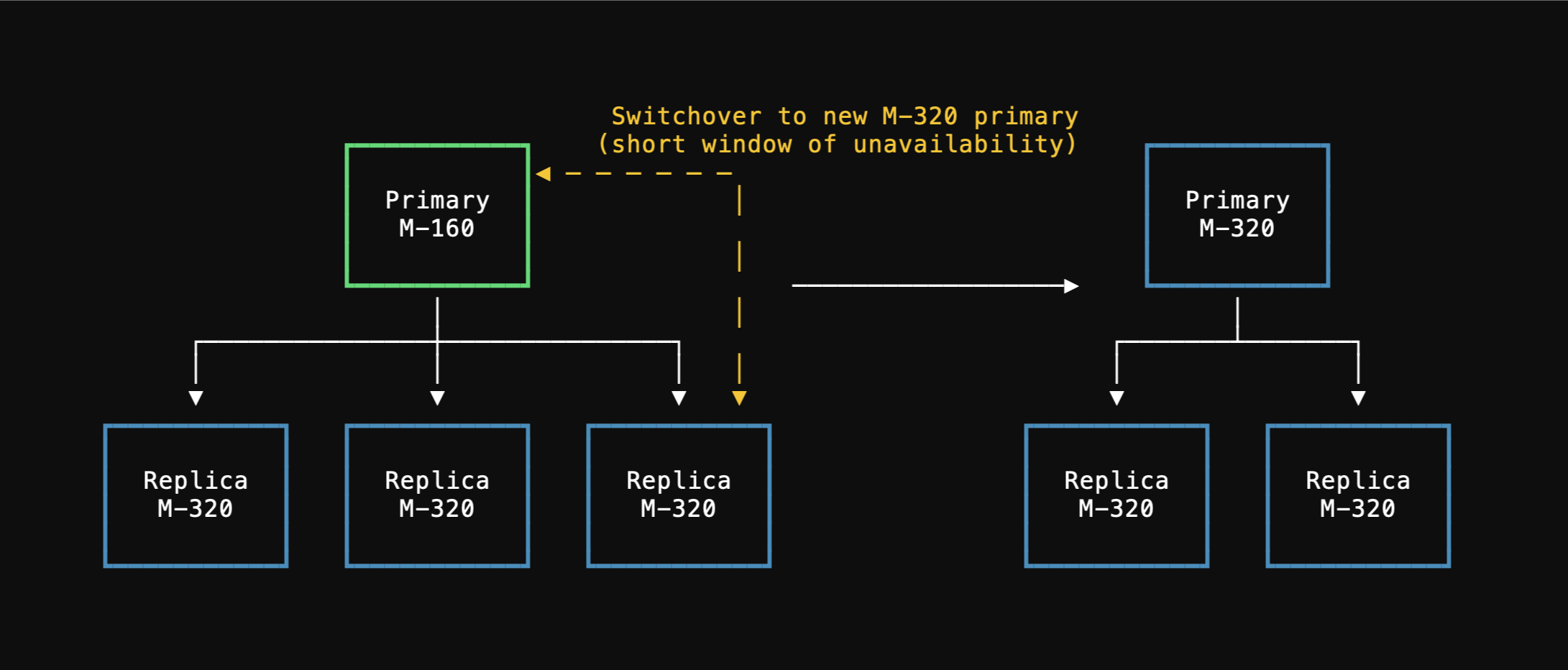
M-160 database cluster fully functional.
Only brief periods of unavailability are required to ensure we can smoothly replace each node.
Many ORMs have built-in connection retry logic to help with these scenarios.
It’s likely your application already has such capabilities if you are using libraries like Rails ActiveRecord, Laravel Eloquent, and Drizzle.
Unplanned failures
In a cloud-native environment, server failure is to be expected. This is unavoidable, so we embrace the behavior and have proven failover systems in place to address issues as quickly as possible. PlanetScale has executed millions of failovers across our Postgres and Vitess database clusters. They are a well-exercised path and are proven to be an invaluable mechanism for database operations and handling node failures.Replicas
Replica health is important to keep your PlanetScale database cluster operating smoothly. Replica failures are automatically detected and automatically replaced. There will be a period of time where your cluster has only the primary and a single replica while the replacement replica is created and data restored to it. This time varies from minutes to hours depending on database size and your instance type.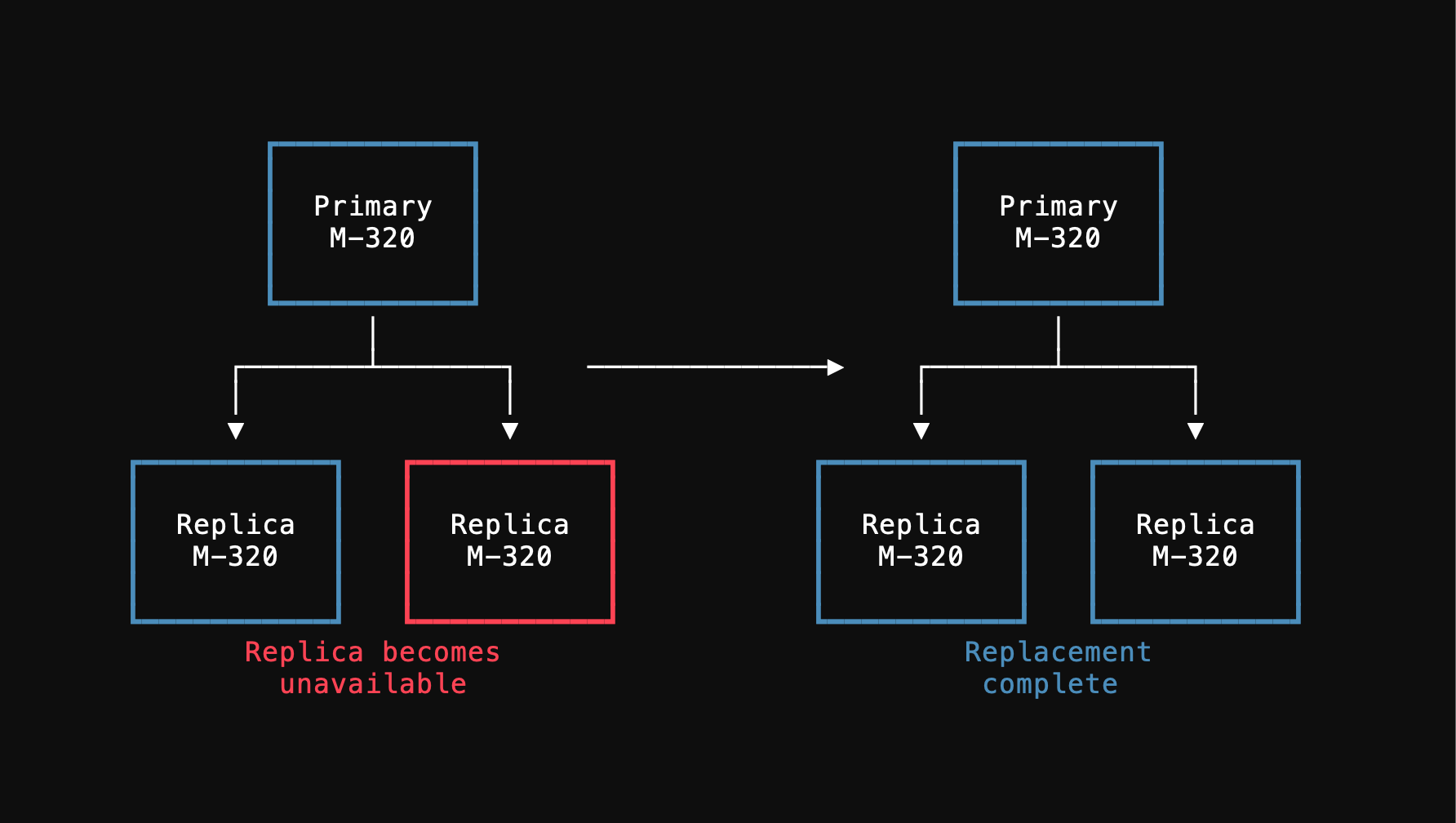
Primaries
The PlanetScale operator will detect a primary failure within seconds and immediately begin the process of replacing the node. The new primary is chosen based on which one is the most caught-up from the state of the primary. All Postgres databases are run with semi-sync replication, meaning that at least one replica should have received all the writes that the primary had seen. Once chosen, this replica is promoted to primary and a new node is brought up to replace it.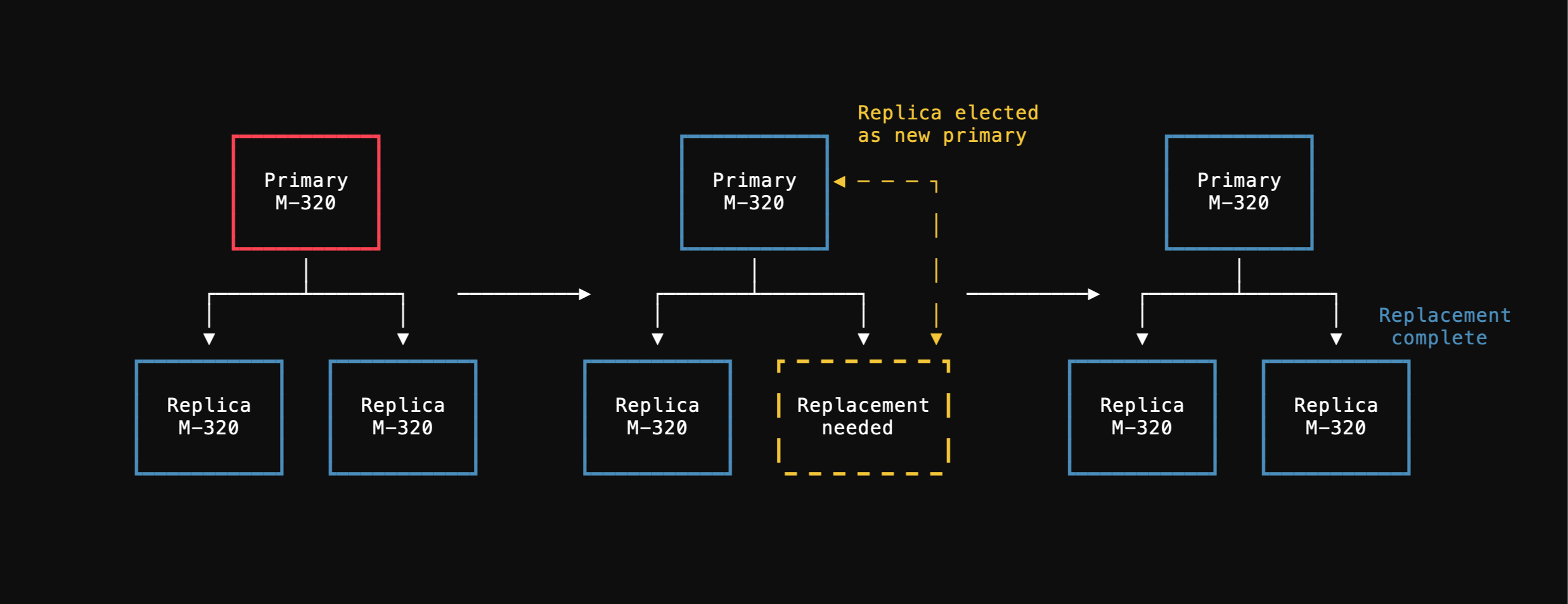
Image upgrades
We have fast iteration cycles at PlanetScale, always aiming to improve the features and capabilities of our customer’s Postgres databases. Postgres minor version updates, PgBouncer updates, and adding support for new extensions all require us to update the container images for your database. When this happens, the Kubernetes pods that power your primary and replicas are updated.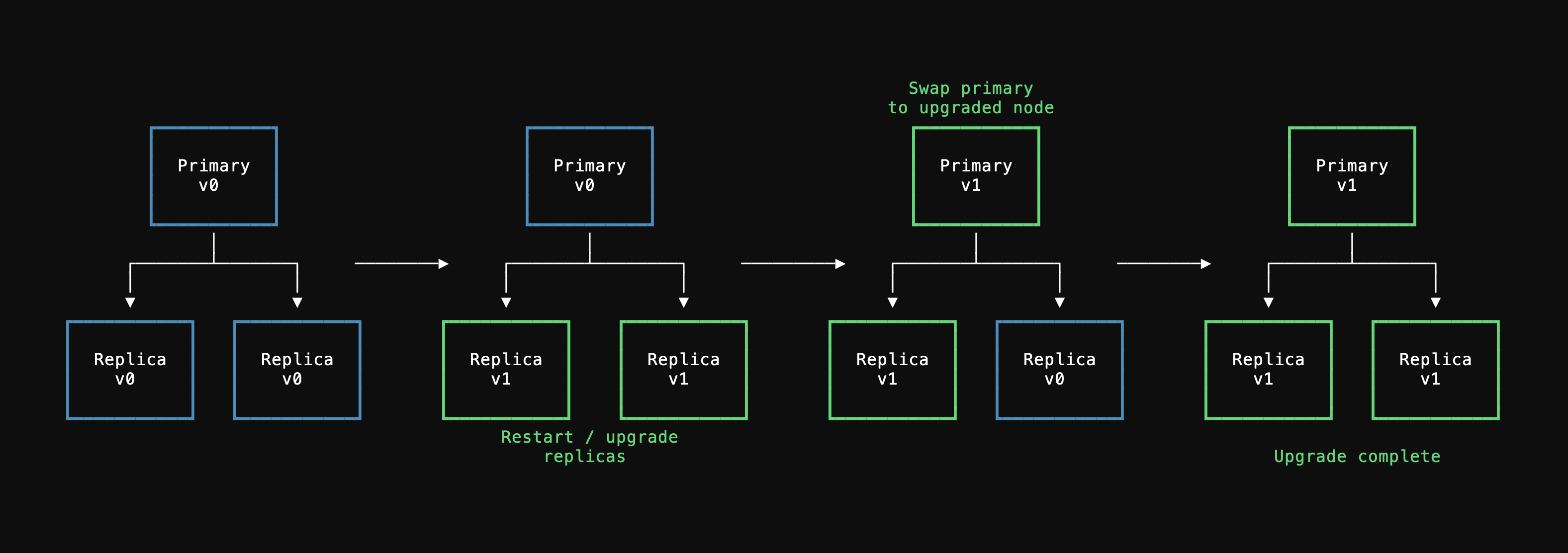
Disk availability, scaling, and cost
For databases using network-attached storage, autoscaling is enabled by default. This is to protect availability of your database. Reaching 100% full on a storage volume leads to database downtime.