Schema recommendations are also available through the PlanetScale MCP server, and can be automatically evaluated and implemented by AI coding agents on a recurring schedule. See Self-improving database.
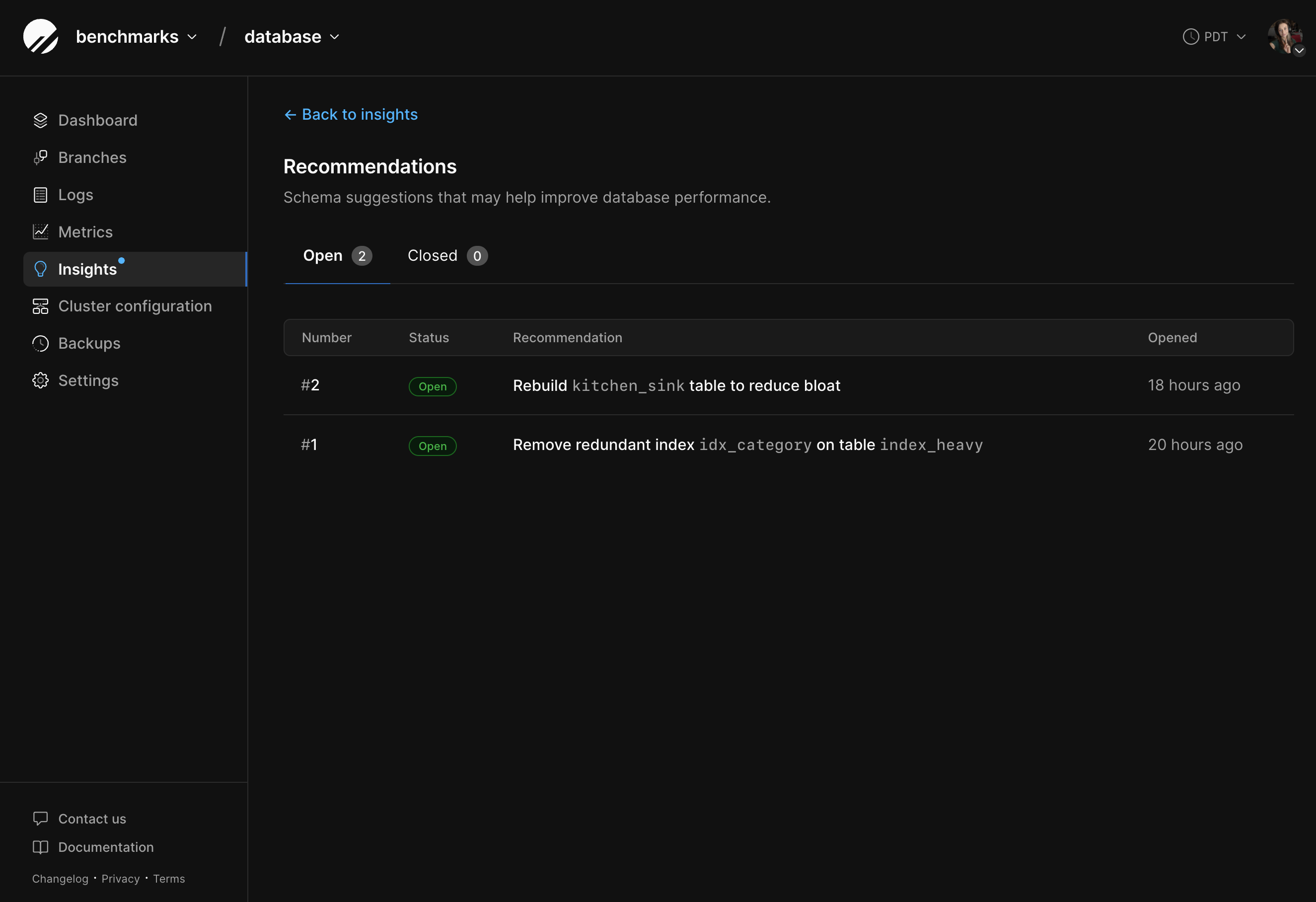
How to use schema recommendations
To find the schema recommendations for your database, go to the “Insights” tab in your PlanetScale database and click “View recommendations.” You will see the current open recommendations that may help improve database performance. Select a recommendation to learn more. Each recommendation will have the following:- An explanation of the recommended changes, including some of the benefits of the recommended change (E.g., reduced memory and storage, decreased execution time, prevent ID exhaustion)
- The schema or query that it will affect
- DDL that can be applied to resolve the recommendation
Schema recommendations that depend on your database traffic run once per day. Recommendations that depend only on
database schema are run whenever the the schema of your default branch is modified. Schema recommendations are
generated only for the database’s default branch.
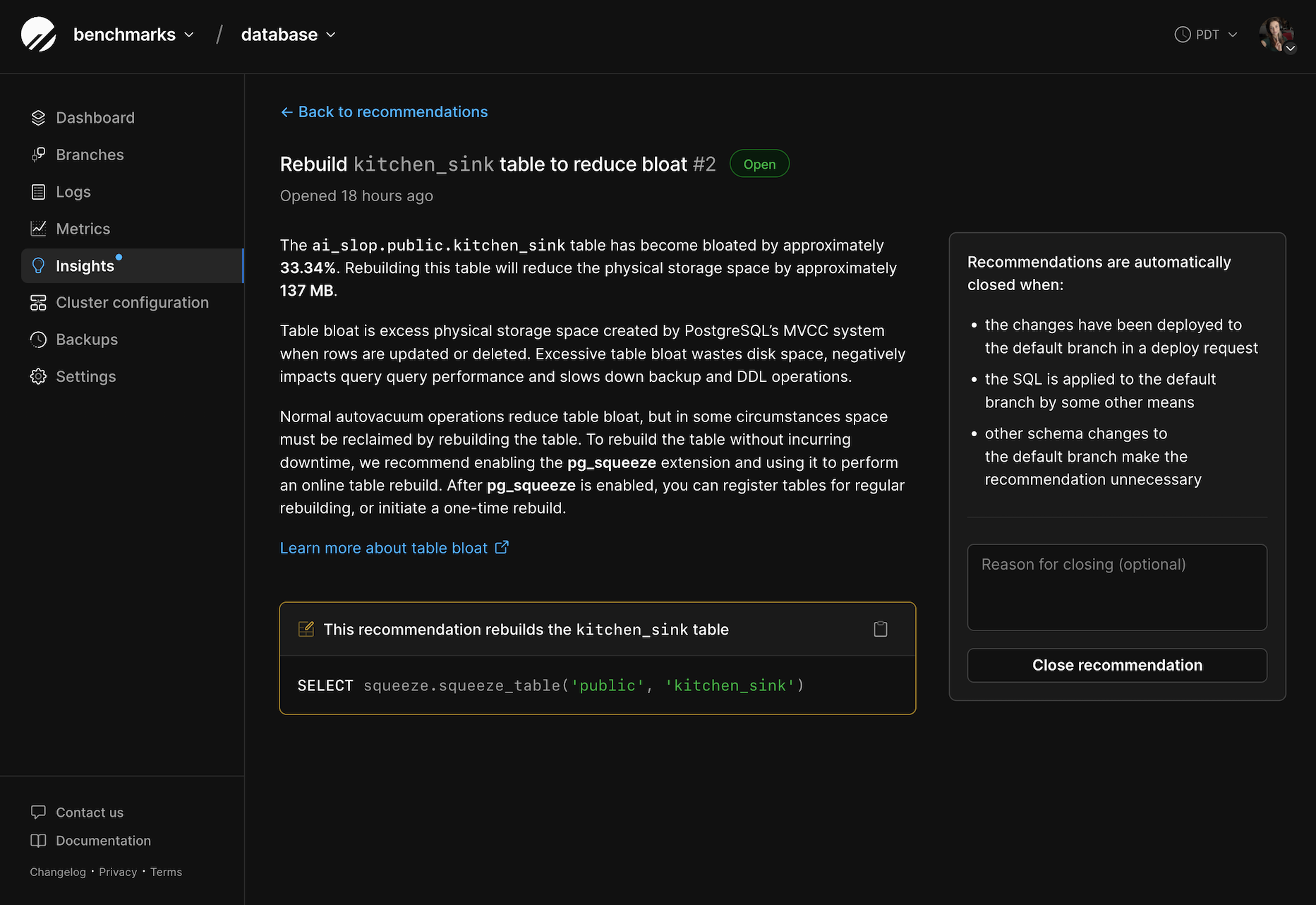
Applying a recommendation
Schema recommendations include a DDL statement that can be applied directly to your database, or integrated into your application or ORM framework. We recommend carefully evaluating the performance impacts or downtime assoicated with running the DDL before applying it to a production environment.Closing a recommendation
Recommendations are automatically closed when:- The changes have been deployed to the default branch
- Other schema changes to the default branch make the recommendation unnecessary
Supported schema recommendations
The following are the currently supported schema recommendations:- Adding indexes for inefficient queries
- Removing redundant indexes
- Preventing primary key ID exhaustion
- Dropping unused tables
- Dropping unused indexes
- Rebuilding bloated tables
- Rebuilding bloated indexes
Schema recommendations may not be in line with your desired outcomes. PlanetScale shall not be held liable for any
actions you take based on these recommendations.
Adding indexes for inefficient queries
Indexes are crucial for relational database performance. With no indexes or suboptimal indexes, PostgreSQL may have to read a large number of rows to satisfy queries that only match a few records. This results in slow queries and poor database performance. PlanetScale Insights automatically scans your database and suggests indexes tailored to your schema and workload.How PlanetScale recommends adding indexes
To find indexes that will improve database performance, Insights scans query telemetry data every 24 hours to find query patterns that use significant resources. Normalized versions of these queries, along with relevant schema information, are provided as input to an LLM prompted to return index suggestions. After validating the returned suggestions for syntactic correctness, we evaluate the estimated performance of each query pattern with and without the suggested index. If any suggested index results in substantial query performance improvement, a new index recommendation is created. New index recommendations show the DDL required to create the index, a list of the queries that will benefit from the index, and an estimate of the performance improvement of each query pattern after creating the index.Caveats
- Indexes can dramatically improve read query performance, but they also increase write costs, memory usage, and the size of tables on disk. Evaluating these additional costs against your application’s improvement in read performance is always a good idea.
- Indexing is a complicated topic and depends on many factors, such as the distribution of values in your database and the particular queries your database receives. If you decide to deploy a suggested index to production, it is a good idea to use Insights to verify that your index has the desired effect on relevant queries.
- Query performance with a suggested index is estimated with the HypoPG extension. This extension is installed by default on all PlanetScale Postgres databases. Removing this extension will disable new index recommendations.
- Index suggestions are generated using AI tools. Learn more about how PlanetScale uses AI here.
- New index suggestions, and other LLM-based features, can be disabled in the organization settings page.
- By default, cost estimates use placeholder parameter values for each normalized query pattern. These values may not match your actual workload, which makes index suggestions less accurate. To improve accuracy, enable the
pginsights.raw_queriessetting. When enabled, candidate indexes are evaluated using actual parameter values from slow queries, resulting in better suggestions. Note: Full query text is only used for generatingEXPLAINplans. No parameter values are sent to the LLM.
Removing redundant indexes
While indexes can drastically improve query performance, having unnecessary indexes slows down writes and consumes additional storage and memory.How PlanetScale recommends removing indexes
Insights scans your schema every time it is changed to find redundant indexes. We suggest removing two types of indexes:- Exact duplicate indexes - an index that has the same columns in the same order
- Left prefix duplicate indexes - an index that has the same columns in the same order as the prefix of another index
Caveats
Removing redundant indexes is more nuanced than adding an index.- Exact duplicate indexes are always safe to remove.
- Left prefix duplicate indexes are almost always safe to remove, but in some cases can lead to a performance regression. Usually, the larger index can be used instead of the left prefix duplicate indexes.
Preventing primary key ID exhaustion
As new rows are inserted, it’s possible for sequence-driven primary keys to exceed the maximum allowable value for the underlying column type. When the column reaches the maximum value, subsequent inserts into the table will fail, which can cause a severe outage to your application.How PlanetScale detects primary key ID exhaustion
Insights scans all of the sequences in your database, finds the owning columns and checks the most recent value daily to identify where you might be approaching primary key ID exhaustion. If Insights detects that one of the columns is above 60% of the maximum allowable type, it will recommend changing the underlying column to a larger type. Additionally, Insights scans queries to parse joins and correlated subqueries to find foreign keys and suggests increasing the column size for those columns.Changing primary key types
To make space for additional table growth, the primary key column and any foreign key columns that reference the primary key need to be updated to a larger integer type:BIGINT. The most straightforward approach is to issue an ALTER TABLE ... ALTER TYPE ... command, and this is the DDL that is shown in the schema recommendation. However, there is a significant downside to this approach: the table will be completely locked while the entire table is rewritten which will result in downtime if your application interacts with this table. ALTER TABLE ... ALTER TYPE ... is not an online operation and rewriting a large table can take many hours.
Do not run
ALTER TABLE ... ALTER TYPE ... if the table is actively used by your application.BIGINT data type unless you are certain that the number of rows in the table will be small.
Caveats
- Running
ALTER TABLE ... ALTER TYPE ...will lead to significant downtime for large tables. - Changing data types without downtime is complicated and will need to be carefully planned and tested.
Dropping unused tables
Dropping unused tables can help clean up data that is no longer needed and reduce storage. If the table is large, it can also decrease backup and restore time. If you are unsure if a table should be retained but decide to drop the table, make sure to create a manual backup of your database before you deploy the change. If you determine that the table should be retained, close the recommendation, preventing the suggestion from being remade.How PlanetScale recommends dropping unused tables
Insights scans your query performance data daily to identify if any tables are more than four weeks old and haven’t been queried in the last four weeks.Caveats
- Only you can know if the table’s data is no longer needed. Ensure that the table is never used (even infrequently) and does not contain important data before removing it.
- Once a drop unused table recommendation is opened, it will remain open even if it is subsequently queried. Check your Insights data to verify that the table is still unused before permanently dropping it.
Dropping unused indexes
Dropping unused indexes can help reduce the cost of inserts and updates, and save memory and storage.How PlanetScale recommends dropping unused indexes
Insights scans your query performance data daily to identify if any indexes are more than four weeks old and haven’t been used by any queries in the last four weeks.Caveats
- Dropping an index, even if hasn’t been recently used, can affect the performance of future queries. Ensure that your application doesn’t make any queries that depend on the index to run efficiently.
- Once a drop unused index recommendation is opened, it will remain open even if the index is subsequently used. Check your Insights data to verify that the index is still unused before permanently dropping it. Insights queries can be filtered by index usage by specifying
index:index_namein the Insights search box.
Rebuilding bloated tables
Table bloat is excess physical storage space created by PostgreSQL’s MVCC system when rows are updated or deleted. Excessive table bloat wastes disk space, negatively impacts query performance and slows down backup and DDL operations. Some amount of table bloat is normal, but high or ever-increasing bloat is a situation that needs to be remediated. Table bloat can occur when frequentupdates or deletes lead to fragmentation in the physical storage layer over time. When this occurs, the table needs to be rebuilt to optimize the physical layout of tuples on disk. To rebuild a bloated table with minimal disruption to your application, we recommend using the pg_squeeze extension, which can be enabled on your database’s Clusters page. Once that is enabled a table can be registered for regular processing or a one-time cleanup can be performed. The schema recommendation shows the command necessary to perform a one-time cleanup. See the pg_squeeze documentation for further information.
How PlanetScale detects table bloat
Insights scans your database once a day to estimate table bloat based on system tables. Table bloat recommendations are triggered when the estimated percent of physical space lost due to bloat is over 25% and 100MB for a given table.Caveats
- Tables can become bloated for reasons other than physical storage fragmentation, such as very long running transactions that prevent dead tuple reclamation, or infrequent vacuuming possibly caused by inadequate auto vacuum settings. If either of these are the case, you will need to address those underlying causes to resolve table bloat.
- Once a table bloat recommendation is created, it will remain open even if bloat drops below the triggering thresholds.
- Once a table bloat recommendation is closed, it will never be opened for that table again.
- Running
pg_squeezewill consume database resources, so be sure that your database has sufficient capacity before rebuilding tables.
Rebuilding bloated indexes
Like table bloat, index bloat is excess physical storage space created by PostgreSQL’s MVCC system when rows are updated or deleted. Excessive index bloat wastes disk space and negatively impacts query performance. Some amount of index bloat is normal, but high or ever-increasing bloat is a situation that needs to be remediated. Index bloat can occur when frequentupdates or deletes lead to fragmentation in the physical storage layer over time. When this occurs, the index needs to be rebuilt to optimize the physical layout of tuples on disk. The index bloat recommendation shows the requisite REINDEX INDEX CONCURRENTLY ... command to rebuild the index and minimize accumulated bloat.
How PlanetScale detects index bloat
Insights scans your database once a day to estimate index bloat based on system tables. Index bloat recommendations are triggered when the estimated percent of physical space lost due to bloat is over 30% and 100MB for a given index.Caveats
- Indexes can become bloated for reasons other than physical storage fragmentation, such as very long running transactions that prevent dead tuple reclamation, or infrequent vacuuming possibly caused by inadequate auto vacuum settings. If either of these are the case, you will need to address those underlying causes to resolve index bloat.
- Once an index bloat recommendation is created, it will remain open even if bloat drops below the triggering thresholds.
- Once an index bloat recommendation is closed, it will never be opened for that index again.
- Running
REINDEX INDEX CONCURRENTLY ...will consume database resources, so be sure that your database has sufficient capacity before rebuilding indexes.